
Video dypfakes betyr at du ikke kan stole på alt du ser. Nå kan lyddypfakes bety at du ikke lenger kan stole på ørene dine. Var det virkelig presidenten som erklærte Canada krig? Er det virkelig faren din på telefonen som ber om passordet hans?
Legg til en annen eksistensiell bekymring i listen over hvordan vår egen hubris uunngåelig kan ødelegge oss. I løpet av Reagan-tiden var den eneste virkelige teknologiske risikoen trusselen om kjernefysisk, kjemisk og biologisk krigføring.
I de påfølgende årene har vi hatt muligheten til å være besatt av nanotechs grå goo og globale pandemier. Nå har vi dype forfalskninger - folk mister kontrollen over deres likhet eller stemme.
Hva er en Audio Deepfake?
De fleste av oss har sett en video dypfake , der dyplæringsalgoritmer brukes til å erstatte en person med andres likhet. Det beste er unødvendig realistisk, og nå er det lyd for tur. En lydfalske er når en "klonet" stemme som potensielt ikke kan skilles fra den virkelige personens, brukes til å produsere syntetisk lyd.
"Det er som Photoshop for stemme," sa Zohaib Ahmed, administrerende direktør for Likner AI , om selskapets stemmekloningsteknologi.
Imidlertid blir dårlige Photoshop-jobber lett avkreftet. Et sikkerhetsfirma vi snakket med sa at folk vanligvis bare gjetter om en lyddypfake er ekte eller falsk med omtrent 57 prosent nøyaktighet - ikke bedre enn en myntvending.
I tillegg, fordi så mange stemmeopptak er av telefonsamtaler av lav kvalitet (eller innspilt på støyende steder), kan lyddypfakes gjøres enda mer skille. Jo dårligere lydkvalitet, jo vanskeligere er det å plukke opp de talende tegnene på at en stemme ikke er ekte.
Men hvorfor skulle noen ha behov for en Photoshop for stemmer?
Den overbevisende saken for syntetisk lyd
Det er faktisk en enorm etterspørsel etter syntetisk lyd. Ifølge Ahmed er "avkastningen veldig umiddelbar."
Dette gjelder spesielt når det gjelder spill. Tidligere var tale den eneste komponenten i et spill som det var umulig å skape etterspørsel. Selv i interaktive titler med scener av kinokvalitet gjengitt i sanntid, er verbale interaksjoner med ikke-spillende karakterer i det vesentlige statiske.
Nå har imidlertid teknologien tatt igjen. Studioer har potensial til å klone en skuespillerstemme og bruke tekst-til-tale-motorer slik at tegn kan si hva som helst i sanntid.
Det er også mer tradisjonelle bruksområder innen reklame, og teknisk og kundesupport. Her er det en stemme som høres autentisk menneskelig ut og reagerer personlig og kontekstuelt uten menneskelig innspill.
Tale-kloning selskaper er også begeistret for medisinske applikasjoner. Selvfølgelig er stemmeskift ikke noe nytt innen medisin - Stephen Hawking brukte kjent en robot-syntetisert stemme etter å ha mistet sin egen i 1985. Moderne stemmekloning lover imidlertid noe enda bedre.
I 2008, syntetisk stemmefirma, CereProc , ga sen filmkritiker, Roger Ebert, stemmen tilbake etter at kreft tok den bort. CereProc hadde publisert en webside som tillot folk å skrive meldinger som deretter ble uttalt med stemmen til tidligere president George Bush.
"Ebert så det og tenkte," vel, hvis de kunne kopiere Bushs stemme, skulle de være i stand til å kopiere min, "sa Matthew Aylett, vitenskapelig sjef for CereProc. Ebert ba deretter selskapet om å lage en erstatningstemme, noe de gjorde ved å behandle et stort bibliotek med stemmeopptak.
"Det var en av de første gangene noen noensinne hadde gjort det, og det var en virkelig suksess," sa Aylett.
De siste årene har en rekke selskaper (inkludert CereProc) jobbet med ALS Association på Prosjekt Revoice å gi syntetiske stemmer til de som lider av ALS.

Hvordan syntetisk lyd fungerer
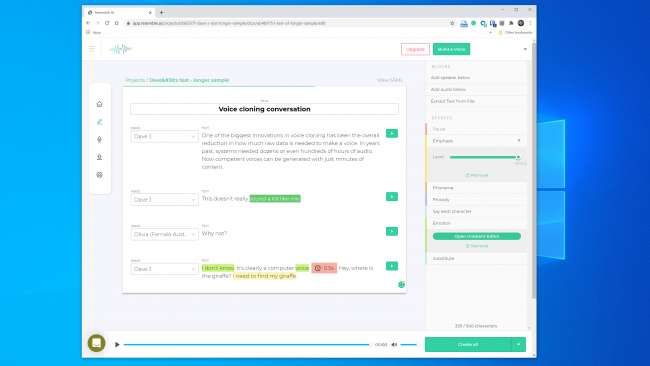
Stemmekloning har et øyeblikk akkurat nå, og en rekke selskaper utvikler verktøy. Likner AI og Beskrivelse ha online demoer som alle kan prøve gratis. Du registrerer bare setningene som vises på skjermen, og på bare noen få minutter blir det laget en modell av stemmen din.
Du kan takke AI - spesielt dyplæringsalgoritmer —For å kunne matche innspilt tale til tekst for å forstå komponentfonemene som utgjør stemmen din. Deretter bruker de resulterende språklige byggesteinene til å tilnærme ord det ikke har hørt deg snakke.
Den grunnleggende teknologien har eksistert en stund, men som Aylett påpekte, krevde det litt hjelp.
"Å kopiere stemmen var litt som å lage bakverk," sa han. "Det var litt vanskelig å gjøre, og det var forskjellige måter du måtte tilpasse det for hånd for å få det til å fungere."
Utviklere trengte enorme mengder innspilte taledata for å få akseptable resultater. Så for noen år siden åpnet flomportene. Forskning innen datasyn viste seg å være kritisk. Forskere utviklet generative motstandernettverk (GAN), som for første gang kunne ekstrapolere og komme med spådommer basert på eksisterende data.
"I stedet for at en datamaskin ser et bilde av en hest og sier" dette er en hest, "kunne modellen min nå gjøre en hest til en sebra," sa Aylett. "Så eksplosjonen i talesyntese er nå takket være det akademiske arbeidet fra datasyn."
En av de største innovasjonene innen stemmekloning har vært den totale reduksjonen i hvor mye rådata som trengs for å lage en stemme. Tidligere trengte systemer dusinvis eller hundrevis av timer med lyd. Nå kan imidlertid kompetente stemmer genereres fra bare få minutter med innhold.
I SLEKT: Problemet med AI: Maskiner lærer ting, men kan ikke forstå dem
Den eksistensielle frykten for ikke å stole på noe
Denne teknologien, sammen med kjernekraft, nanoteknologi, 3D-utskrift og CRISPR, er samtidig spennende og skremmende. Tross alt har det allerede vært tilfeller i nyheten om at folk blir lurt av stemmekloner. I 2019 hevdet et selskap i Storbritannia at det var det lurt av en lydfalske telefonsamtale for å koble penger til kriminelle.
Du trenger heller ikke å gå langt for å finne overraskende overbevisende lydfalsker. YouTube-kanal Vokalsyntese har kjente mennesker som sier ting de aldri sa, som George W. Bush som leser "In Da Club" av 50 Cent . Det er perfekt.
Andre steder på YouTube kan du høre en flokk ex-presidenter, inkludert Obama, Clinton og Reagan, rapping NWA . Musikken og bakgrunnslydene hjelper til med å skjule noe av den åpenbare robotglitchinessen, men selv i denne ufullkomne tilstanden er potensialet åpenbart.
Vi eksperimenterte med verktøyene på Likner AI og Beskrivelse og opprettet stemmeklon. Descript bruker en stemmekloning-motor som opprinnelig ble kalt Lyrebird og var spesielt imponerende. Vi ble sjokkert over kvaliteten. Å høre din egen stemme si ting du vet du aldri har sagt, er nervøs.
Det er definitivt en robotkvalitet til talen, men når en uformell lytting vil de fleste ikke ha noen grunn til å tro at det var en falsk.

Vi hadde enda større håp om å ligne AI. Det gir deg verktøyene for å lage en samtale med flere stemmer og variere uttrykksevne, følelser og tempo i dialogen. Vi trodde imidlertid ikke at stemmemodellen fanget de essensielle egenskapene til stemmen vi brukte. Det var faktisk lite sannsynlig å lure noen.
En lignende AI-representant fortalte oss "de fleste blir blåst bort av resultatene hvis de gjør det riktig." Vi bygde en stemmemodell to ganger med lignende resultater. Så tydeligvis er det ikke alltid lett å lage en stemmeklone du kan bruke til å hente en digital heist.
Likevel føler Lyrebird (som nå er en del av Descript) -stifter, Kundan Kumar, at vi allerede har passert denne terskelen.
"For en liten prosentandel av tilfellene er den allerede der," sa Kumar. "Hvis jeg bruker syntetisk lyd for å endre noen ord i en tale, er det allerede så bra at du vil ha vanskelig for å vite hva som har endret seg."
Vi kan også anta at denne teknologien bare vil bli bedre med tiden. Systemer trenger mindre lyd for å lage en modell, og raskere prosessorer vil kunne bygge modellen i sanntid. Smartere AI vil lære å legge til mer overbevisende menneskelignende tråkkfrekvens og vekt på tale uten å ha et eksempel å jobbe fra.
Hvilket betyr at vi kan krype nærmere den utbredte tilgjengeligheten av uanstrengt stemmekloning.
Etikken til Pandoras boks
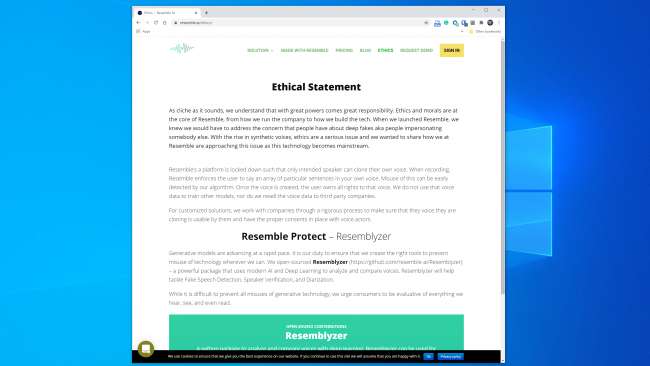
De fleste selskaper som jobber i dette området ser ut til å håndtere teknologien på en trygg og ansvarlig måte. Likner AI, for eksempel, har en hel "Etikk" -seksjon på nettstedet , og følgende utdrag er oppmuntrende:
"Vi samarbeider med selskaper gjennom en streng prosess for å sikre at stemmen de kloner er brukbar av dem og har riktig samtykke på plass med stemmeaktører."
Kumar sa også at Lyrebird var bekymret for misbruk fra starten. Derfor, som en del av Descript, lar det bare folk klone sin egen stemme. Faktisk krever både Lign og Descript at folk registrerer prøvene sine live for å forhindre ikke-konsensuell stemmekloning.
Det er gledelig at de store kommersielle aktørene har pålagt noen etiske retningslinjer. Det er imidlertid viktig å huske at disse selskapene ikke er portvoktere for denne teknologien. Det finnes en rekke open source-verktøy allerede i naturen, som det ikke er noen regler for. I følge Henry Ajder, leder for trusseletterretning ved Deeptrace , du trenger heller ikke avansert kodingskunnskap for å misbruke den.
"Mye av fremgangen i rommet har kommet gjennom samarbeid på steder som GitHub, ved hjelp av open source-implementeringer av tidligere publiserte akademiske artikler," sa Ajder. "Den kan brukes av alle som har moderat dyktighet i koding."
Sikkerhetsproffene har sett alt dette før
Kriminelle har prøvd å stjele penger på telefon lenge før kloning av stemmene var mulig, og sikkerhetseksperter har alltid vært på vakt for å oppdage og forhindre det. Sikkerhetsselskap Pindrop prøver å stoppe banksvindel ved å verifisere om en innringer er den han eller hun hevder å være fra lyden. Bare i 2019 hevder Pindrop å ha analysert 1,2 milliarder taleinteraksjoner og forhindret rundt 470 millioner dollar i svindelforsøk.
Før stemmekloning prøvde svindlere en rekke andre teknikker. Det enkleste var bare å ringe andre steder med personlig informasjon om merket.
"Vår akustiske signatur lar oss bestemme at en samtale faktisk kommer fra en Skype-telefon i Nigeria på grunn av lydegenskapene," sa Pindrop-sjef, Vijay Balasubramaniyan. "Deretter kan vi sammenligne det å vite at kunden bruker en AT & T-telefon i Atlanta."
Noen kriminelle har også gjort karrierer med å bruke bakgrunnslyder for å kaste bankrepresentanter.
"Det er en svindler vi kalte Chicken Man som alltid hadde haner i bakgrunnen," sa Balasubramaniyan. "Og det er en dame som brukte en baby som gråt i bakgrunnen, for i det vesentlige å overbevise kundesenteragentene om at" hei, jeg går gjennom en tøff tid "for å få sympati."
Og så er det de mannlige kriminelle som følger kvinners bankkontoer.
"De bruker teknologi for å øke frekvensen av stemmen sin, for å høres mer feminin ut," forklarte Balasubramaniyan. Disse kan være vellykkede, men "av og til roter programvaren opp og de høres ut som Alvin and the Chipmunks."
Selvfølgelig er stemmekloning bare den siste utviklingen i denne stadig eskalerende krigen. Sikkerhetsfirmaer har allerede fanget svindlere som bruker syntetisk lyd i minst ett spydfiskeangrep.
"Med riktig mål kan utbetalingen være massiv," sa Balasubramaniyan. "Så det er fornuftig å vie tiden til å lage en syntetisert stemme til det rette individet."
Kan noen fortelle om en stemme er falsk?

Når det gjelder å gjenkjenne om en stemme har blitt forfalsket, er det både gode og dårlige nyheter. Det dårlige er at stemmekloner blir bedre hver dag. Dyplæringssystemer blir smartere og gir mer autentiske stemmer som krever mindre lyd å lage.
Som du kan fortelle fra dette klippet av President Obama ba MC Ren ta stillingen , har vi også allerede kommet til et punkt hvor en høykvalitets, nøye konstruert stemmemodell kan høres ganske overbevisende ut for det menneskelige øret.
Jo lenger et lydklipp er, desto mer sannsynlig er det at det er noe galt. For kortere klipp, skjønner du kanskje ikke at det er syntetisk - spesielt hvis du ikke har noen grunn til å stille spørsmål ved legitimiteten.
Jo klarere lydkvalitet, jo lettere er det å legge merke til tegn på en lydfalske. Hvis noen snakker direkte i en mikrofon i studiokvalitet, kan du lytte nøye. Men en ringe opptak av dårlig kvalitet eller en samtale fanget på en håndholdt enhet i et støyende parkeringshus vil være mye vanskeligere å evaluere.
Den gode nyheten er at datamaskiner ikke har de samme begrensningene, selv om mennesker har problemer med å skille ekte fra falsk. Heldigvis finnes det allerede verktøy for stemmebekreftelse. Pindrop har en som setter dyplæringssystemer mot hverandre. Den bruker begge deler for å oppdage om en lydeksempel er personen den skal være. Imidlertid undersøker den også om et menneske til og med kan lage alle lydene i prøven.
Avhengig av lydkvaliteten inneholder hvert sekund av talen mellom 8.000-50.000 dataprøver som kan analyseres.
"De tingene vi vanligvis ser etter er begrensninger i tale på grunn av menneskelig evolusjon," forklarte Balasubramaniyan.
For eksempel har to vokallyder et minimum mulig skille fra hverandre. Dette er fordi det ikke er fysisk mulig å si dem raskere på grunn av hastigheten som musklene i munnen og stemmebåndene kan konfigurere seg på nytt.
“Når vi ser på syntetisert lyd,” sa Balasubramaniyan, “vi ser noen ganger ting og sier,” dette kunne aldri ha blitt generert av et menneske, fordi den eneste personen som kunne ha generert dette, trenger å ha en syv fot lang hals. ”
Det er også en lydklasse som kalles "frikativer". De dannes når luft passerer gjennom en smal innsnevring i halsen når du uttaler bokstaver som f, s, v og z. Frikativer er spesielt vanskelig for dyplæringssystemer å mestre fordi programvaren har problemer med å skille dem fra støy.
Så i det minste foreløpig snubles programvare for stemmekloning av det faktum at mennesker er poser med kjøtt som strømmer luft gjennom hull i kroppen for å snakke.
"Jeg fortsetter å tulle med at deepfakes er veldig sutrende," sa Balasubramaniyan. Han forklarte at det er veldig vanskelig for algoritmer å skille endene på ord fra bakgrunnsstøy i et opptak. Dette resulterer i mange stemmemodeller med tale som sporer mer enn mennesker gjør.
"Når en algoritme ser dette skje mye," sa Balasubramaniyan, "statistisk sett blir det tryggere at det er lyd som er generert i motsetning til menneskelig."
Resemble AI takler også oppdagelsesproblemet front-med med Resemblyzer, et dyp-læringsverktøy med åpen kildekode tilgjengelig på GitHub . Den kan oppdage falske stemmer og utføre høyttalerbekreftelse.
Det tar årvåkenhet
Det er alltid vanskelig å gjette hva fremtiden kan ha, men denne teknologien vil nesten helt sikkert bare bli bedre. Dessuten kan hvem som helst være et offer - ikke bare høyt profilerte individer, som folkevalgte eller banksjefer.
"Jeg tror vi er på randen til det første lydbruddet der folks stemmer blir stjålet," spådde Balasubramaniyan.
For øyeblikket er imidlertid den virkelige risikoen fra dypfakes i lyden lav. Det er allerede verktøy som ser ut til å gjøre en ganske god jobb med å oppdage syntetisk video.
I tillegg risikerer de fleste ikke et angrep. Ifølge Ajder jobber de viktigste kommersielle aktørene “med skreddersydde løsninger for spesifikke kunder, og de fleste har ganske gode etiske retningslinjer for hvem de vil og ikke vil jobbe med."
Den virkelige trusselen ligger imidlertid foran oss, da Ajder fortsatte med å forklare:
"Pandoras boks vil være folk som kobler sammen åpen kildekode-implementering av teknologien til stadig mer brukervennlige, tilgjengelige apper eller tjenester som ikke har den slags etiske lag av gransking som kommersielle løsninger gjør for øyeblikket."
Dette er sannsynligvis uunngåelig, men sikkerhetsselskaper ruller allerede falsk lyddeteksjon inn i verktøysettene sine. Å være trygg krever likevel årvåkenhet.
"Vi har gjort dette i andre sikkerhetsområder," sa Ajder. “Mange organisasjoner bruker mye tid på å prøve å forstå hva som er neste null-dagers sårbarhet. Syntetisk lyd er rett og slett neste grense. ”
I SLEKT: Hva er en dyp forfalskning, og bør jeg være bekymret?







