
Door video-deepfakes kunt u niet alles vertrouwen wat u ziet. Nu kunnen deepfakes met audio betekenen dat u uw oren niet langer kunt vertrouwen. Was dat echt de president die Canada de oorlog verklaarde? Is dat echt je vader aan de telefoon die om zijn e-mailwachtwoord vraagt?
Voeg nog een existentiële zorg toe aan de lijst over hoe onze eigen overmoed ons onvermijdelijk zou kunnen vernietigen. Tijdens het Reagan-tijdperk waren de enige echte technologische risico's de dreiging van nucleaire, chemische en biologische oorlogsvoering.
In de daaropvolgende jaren hebben we de kans gehad om ons te obsederen over de grijze klodder van nanotech en de wereldwijde pandemieën. Nu hebben we deepfakes - mensen verliezen de controle over hun gelijkenis of stem.
Wat is een audio-deepfake?
De meesten van ons hebben een video deepfake , waarin deep-learning-algoritmen worden gebruikt om de ene persoon te vervangen door de gelijkenis van iemand anders. De beste zijn zenuwslopend realistisch, en nu is het de beurt aan audio. Een audio-deepfake is wanneer een 'gekloonde' stem die mogelijk niet van de echte persoon te onderscheiden is, wordt gebruikt om synthetische audio te produceren.
"Het is net als Photoshop voor spraak", zegt Zohaib Ahmed, CEO van Lijken op AI , over de spraakkloontechnologie van zijn bedrijf.
Slechte Photoshop-taken worden echter gemakkelijk ontkracht. Een beveiligingsbedrijf waarmee we spraken, zei dat mensen meestal alleen raden of een audio-deepfake echt of nep is met een nauwkeurigheid van ongeveer 57 procent - niet beter dan een muntstuk.
Omdat zoveel spraakopnamen telefoongesprekken van lage kwaliteit zijn (of opgenomen op lawaaierige locaties), kunnen audio-deepfakes bovendien nog onduidelijker worden gemaakt. Hoe slechter de geluidskwaliteit, hoe moeilijker het is om die veelbetekenende signalen op te vangen dat een stem niet echt is.
Maar waarom zou iemand eigenlijk een Photoshop nodig hebben voor stemmen?
De overtuigende case voor synthetische audio
Er is eigenlijk een enorme vraag naar synthetische audio. Volgens Ahmed is "de ROI zeer onmiddellijk."
Dit geldt met name als het om gamen gaat. In het verleden was spraak het enige onderdeel van een game dat onmogelijk on-demand kon worden gemaakt. Zelfs in interactieve titels met scènes van bioscoopkwaliteit die in realtime worden weergegeven, zijn verbale interacties met niet-spelende personages altijd in wezen statisch.
Maar nu heeft de technologie een inhaalslag gemaakt. Studio's hebben het potentieel om de stem van een acteur te klonen en tekst-naar-spraak-engines te gebruiken, zodat personages alles in realtime kunnen zeggen.
Er zijn ook meer traditionele toepassingen in advertenties en technische en klantenondersteuning. Hier is een stem die authentiek menselijk klinkt en persoonlijk en contextueel reageert zonder menselijke tussenkomst, wat belangrijk is.
Bedrijven die spraak klonen zijn ook enthousiast over medische toepassingen. Stemvervanging is natuurlijk niets nieuws in de geneeskunde - Stephen Hawking gebruikte een beroemde gerobotiseerde gesynthetiseerde stem nadat hij zijn eigen stem in 1985 verloor. Het moderne klonen van stemmen belooft echter nog iets beters.
In 2008, synthetisch spraakbedrijf, CereProc , gaf de late filmcriticus Roger Ebert zijn stem terug nadat kanker het wegnam. CereProc had een webpagina gepubliceerd waarop mensen berichten konden typen die vervolgens zouden worden uitgesproken in de stem van voormalig president George Bush.
"Ebert zag dat en dacht," nou, als ze de stem van Bush konden kopiëren, zouden ze de mijne moeten kunnen kopiëren ", zei Matthew Aylett, CereProc's Chief Scientific Officer. Ebert vroeg het bedrijf vervolgens om een vervangende stem te maken, wat ze deden door een grote bibliotheek met spraakopnamen te verwerken.
"Het was een van de eerste keren dat iemand dat ooit had gedaan en het was een echt succes", zei Aylett.
In de afgelopen jaren hebben een aantal bedrijven (waaronder CereProc) samengewerkt met het ALS Association Aan Project Revoice om synthetische stemmen te geven aan degenen die aan ALS lijden.

Hoe synthetische audio werkt
Het klonen van spraak heeft momenteel een moment, en een hele reeks bedrijven ontwikkelt tools. Lijken op AI en Beschrijving hebben online demo's die iedereen gratis kan proberen. U neemt gewoon de zinnen op die op het scherm verschijnen en in slechts enkele minuten wordt een model van uw stem gemaakt.
U kunt AI bedanken, met name diepgaande algoritmen - om opgenomen spraak aan tekst te kunnen koppelen om de fonemen waaruit uw stem bestaat, te begrijpen. Vervolgens gebruikt het de resulterende linguïstische bouwstenen om woorden te benaderen die het u niet heeft horen spreken.
De basistechnologie bestaat al een tijdje, maar zoals Aylett opmerkte, had het wat hulp nodig.
'Stem kopiëren was een beetje zoals gebak maken,' zei hij. "Het was nogal moeilijk om te doen en er waren verschillende manieren waarop je het met de hand moest aanpassen om het te laten werken."
Ontwikkelaars hadden enorme hoeveelheden opgenomen spraakgegevens nodig om redelijke resultaten te krijgen. Toen, een paar jaar geleden, gingen de sluizen open. Onderzoek op het gebied van computervisie bleek cruciaal. Wetenschappers ontwikkelden generatieve vijandige netwerken (GAN's), die voor het eerst konden extrapoleren en voorspellingen konden doen op basis van bestaande gegevens.
"In plaats van dat een computer een foto van een paard ziet en zegt‘ dit is een paard ’, kan mijn model nu van een paard een zebra maken," zei Aylett. "Dus de explosie in spraaksynthese is nu te danken aan het academische werk van computer vision."
Een van de grootste innovaties bij het klonen van spraak is de algehele vermindering van de hoeveelheid onbewerkte gegevens die nodig zijn om een stem te creëren. In het verleden hadden systemen tientallen of zelfs honderden uren audio nodig. Nu kunnen echter bekwame stemmen worden gegenereerd op basis van slechts enkele minuten inhoud.
VERWANT: Het probleem met AI: machines leren dingen, maar kunnen ze niet begrijpen
De existentiële angst om niets te vertrouwen
Deze technologie, samen met kernenergie, nanotechnologie, 3D-printen en CRISPR, is tegelijkertijd spannend en angstaanjagend. Er zijn tenslotte al gevallen in het nieuws geweest dat mensen werden gedupeerd door klonen. In 2019 beweerde een bedrijf in het VK van wel misleid door een audio-deepfake telefoontje om geld over te maken aan criminelen.
U hoeft ook niet ver te zoeken om verrassend overtuigende audio-vervalsingen te vinden. Youtube kanaal Vocale synthese bevat bekende mensen die dingen zeggen die ze nooit hebben gezegd, zoals George W. Bush leest "In Da Club" door 50 Cent . Het is perfect.
Elders op YouTube hoor je een kudde ex-presidenten, waaronder Obama, Clinton en Reagan, die op NWA tikken . De muziek en achtergrondgeluiden helpen een deel van de voor de hand liggende robotachtige glitchiness te verhullen, maar zelfs in deze onvolmaakte staat is het potentieel duidelijk.
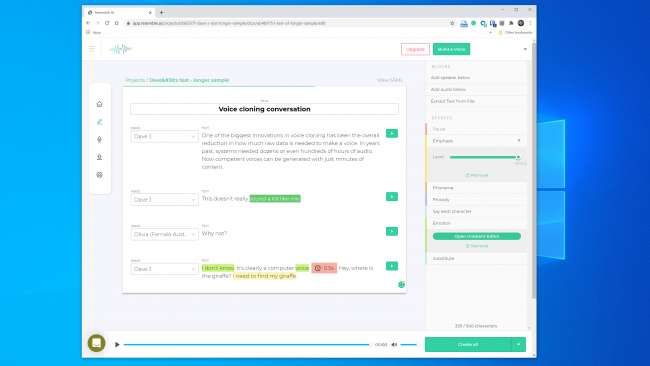
We hebben geëxperimenteerd met de tools op Lijken op AI en Beschrijving en creëerde een stemkloon. Descript gebruikt een stemkloon-engine die oorspronkelijk Lyrebird heette en bijzonder indrukwekkend was. We waren geschokt door de kwaliteit. Het is zenuwslopend om je eigen stem dingen te horen zeggen waarvan je weet dat je ze nog nooit hebt gezegd.
De spraak heeft absoluut een robotachtige kwaliteit, maar bij een informele luisterbeurt hebben de meeste mensen geen reden om te denken dat het nep was.

We hadden zelfs nog hogere verwachtingen van Resemble AI. Het geeft je de tools om een gesprek met meerdere stemmen tot stand te brengen en de expressiviteit, emotie en tempo van de dialoog te variëren. We dachten echter niet dat het spraakmodel de essentiële kwaliteiten van de stem die we gebruikten vastlegde. In feite was het onwaarschijnlijk dat iemand voor de gek zou houden.
Een vertegenwoordiger van Resemble AI vertelde ons "de meeste mensen worden overweldigd door de resultaten als ze het correct doen." We hebben twee keer een spraakmodel gebouwd met vergelijkbare resultaten. Het is dus duidelijk niet altijd gemakkelijk om een stemkloon te maken die u kunt gebruiken om een digitale overval te plegen.
Toch vindt Lyrebird (dat nu onderdeel is van Descript) oprichter, Kundan Kumar, het gevoel dat we die drempel al gepasseerd zijn.
"Voor een klein percentage van de gevallen is het er al", zei Kumar. "Als ik synthetische audio gebruik om een paar woorden in een toespraak te veranderen, is het al zo goed dat je moeilijk zult weten wat er is veranderd."
We kunnen ook aannemen dat deze technologie met de tijd alleen maar beter zal worden. Systemen hebben minder audio nodig om een model te maken, en snellere processors kunnen het model in realtime bouwen. Slimmere AI leert hoe je meer overtuigende mensachtige cadans en nadruk op spraak kunt toevoegen zonder een voorbeeld te hebben om van te werken.
Wat betekent dat we misschien dichter bij de wijdverspreide beschikbaarheid van moeiteloos klonen van stemmen komen.
De ethiek van de doos van Pandora
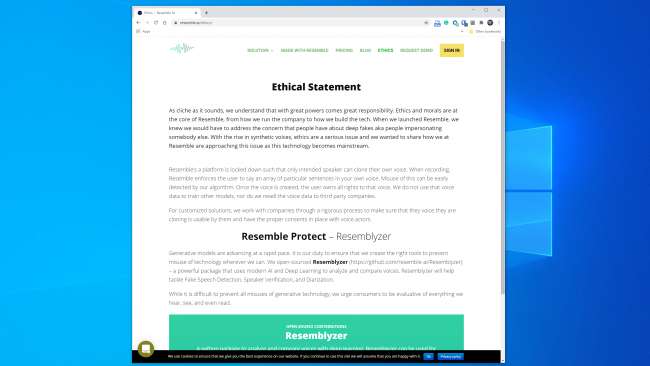
De meeste bedrijven die in deze ruimte werken, lijken klaar om op een veilige, verantwoorde manier met de technologie om te gaan. Lijken op AI heeft bijvoorbeeld een volledige sectie "Ethiek" op haar website , en het volgende fragment is bemoedigend:
"We werken met bedrijven samen via een rigoureus proces om ervoor te zorgen dat de stem die ze klonen, door hen kan worden gebruikt en dat we de juiste toestemming hebben met stemacteurs."
Evenzo zei Kumar dat Lyrebird vanaf het begin bezorgd was over misbruik. Daarom kunnen mensen nu, als onderdeel van Descript, alleen hun eigen stem klonen. In feite vereisen zowel Resemble als Descript dat mensen hun samples live opnemen om niet-consensueel klonen van stemmen te voorkomen.
Het is bemoedigend dat de belangrijkste commerciële spelers enkele ethische richtlijnen hebben opgelegd. Het is echter belangrijk om te onthouden dat deze bedrijven geen poortwachters zijn van deze technologie. Er zijn al een aantal open-source tools in het wild, waarvoor er geen regels zijn. Volgens Henry Ajder, hoofd van dreigingsinformatie bij Deeptrace , je hebt ook geen geavanceerde codeerkennis nodig om deze te misbruiken.
"Veel van de vooruitgang in de ruimte is te danken aan samenwerking op plaatsen zoals GitHub, met behulp van open-source implementaties van eerder gepubliceerde academische papers," zei Ajder. "Het kan worden gebruikt door iedereen met een matige vaardigheid in coderen."
Beveiligingsprofessionals hebben dit allemaal eerder gezien
Criminelen hebben geprobeerd geld te stelen via de telefoon lang voordat klonen van stemmen mogelijk was, en beveiligingsexperts stonden altijd klaar om dit op te sporen en te voorkomen. Beveiligingsbedrijf Pindrop probeert bankfraude te stoppen door aan de hand van de audio te controleren of een beller is wie hij of zij beweert te zijn. Alleen al in 2019 beweert Pindrop 1,2 miljard spraakinteracties te hebben geanalyseerd en ongeveer $ 470 miljoen aan fraudepogingen te hebben voorkomen.
Vóór het klonen van stemmen probeerden fraudeurs een aantal andere technieken. Het eenvoudigste was gewoon van elders bellen met persoonlijke informatie over het merk.
"Onze akoestische handtekening stelt ons in staat om te bepalen of een oproep daadwerkelijk afkomstig is van een Skype-telefoon in Nigeria vanwege de geluidskarakteristieken", aldus Pindrop CEO, Vijay Balasubramaniyan. "Vervolgens kunnen we dat vergelijken, wetende dat de klant een AT & T-telefoon in Atlanta gebruikt."
Sommige criminelen hebben ook carrière gemaakt door achtergrondgeluiden te gebruiken om bankvertegenwoordigers af te zetten.
"Er is een fraudeur die we Chicken Man noemden en die altijd hanen op de achtergrond had," zei Balasubramaniyan. "En er is een dame die een huilende baby op de achtergrond gebruikte om de agenten van het callcenter in wezen ervan te overtuigen dat‘ hey, ik ga het moeilijk hebben ’om sympathie te krijgen."
En dan zijn er de mannelijke criminelen die achter de bankrekeningen van vrouwen aan gaan.
"Ze gebruiken technologie om de frequentie van hun stem te verhogen, om vrouwelijker te klinken", legt Balasubramaniyan uit. Deze kunnen succesvol zijn, maar "af en toe maakt de software een fout en klinken ze als Alvin and the Chipmunks."
Het klonen van stemmen is natuurlijk slechts de nieuwste ontwikkeling in deze steeds escalerende oorlog. Beveiligingsfirma's hebben al fraudeurs betrapt die synthetische audio gebruikten bij ten minste één speervisaanval.
"Met het juiste doelwit kan de uitbetaling enorm zijn", zei Balasubramaniyan. "Het is dus logisch om de tijd te besteden aan het creëren van een gesynthetiseerde stem van de juiste persoon."
Kan iemand zeggen of een stem nep is?

Als het gaat om het herkennen of een stem is vervalst, is er zowel goed als slecht nieuws. Het slechte is dat stemklonen elke dag beter worden. Systemen voor diepgaand leren worden slimmer en maken meer authentieke stemmen waarvoor minder audio nodig is.
Zoals je kunt zien aan deze clip van President Obama zegt tegen MC Ren dat hij het standpunt moet innemen , we zijn ook al op het punt gekomen dat een hifi, zorgvuldig geconstrueerd stemmodel behoorlijk overtuigend kan klinken voor het menselijk oor.
Hoe langer een geluidsfragment is, hoe groter de kans dat u merkt dat er iets niet klopt. Voor kortere clips merk je misschien niet dat het synthetisch is, vooral als je geen reden hebt om de legitimiteit ervan in twijfel te trekken.
Hoe duidelijker de geluidskwaliteit, hoe gemakkelijker het is om tekenen van een diepe audio-opname op te merken. Als iemand rechtstreeks in een microfoon van studiokwaliteit spreekt, kunt u goed luisteren. Maar een opname van een telefoongesprek van slechte kwaliteit of een gesprek dat is vastgelegd op een handheld-apparaat in een lawaaierige parkeergarage, zal veel moeilijker te beoordelen zijn.
Het goede nieuws is dat, zelfs als mensen moeite hebben om echt en nep te scheiden, computers niet dezelfde beperkingen hebben. Gelukkig bestaan er al stemverificatietools. Pindrop heeft er een die deep-learning-systemen tegen elkaar plaatst. Het gebruikt beide om te ontdekken of een audiofragment de persoon is die het hoort te zijn. Het onderzoekt echter ook of een mens zelfs alle geluiden in de sample kan maken.
Afhankelijk van de kwaliteit van de audio, bevat elke seconde spraak tussen de 8.000 en 50.000 datamonsters die kunnen worden geanalyseerd.
"De dingen waar we doorgaans naar op zoek zijn, zijn spraakbeperkingen als gevolg van menselijke evolutie", legt Balasubramaniyan uit.
Twee vocale geluiden hebben bijvoorbeeld een minimaal mogelijke scheiding van elkaar. Dit komt omdat het fysiek niet mogelijk is om ze sneller uit te spreken vanwege de snelheid waarmee de spieren in je mond en stembanden zichzelf kunnen herconfigureren.
'Als we naar gesynthetiseerde audio kijken,' zei Balasubramaniyan, 'zien we soms dingen en zeggen we:' Dit kan nooit door een mens zijn gegenereerd, want de enige persoon die dit had kunnen genereren, moet een nek van twee meter lang hebben. "
Er is ook een geluidsklasse die 'fricatieven' wordt genoemd. Ze worden gevormd wanneer lucht door een nauwe vernauwing in je keel stroomt wanneer je letters uitspreekt als f, s, v en z. Fricatieven zijn vooral moeilijk voor deep-learning-systemen om onder de knie te krijgen, omdat de software ze moeilijk kan onderscheiden van ruis.
Dus, voorlopig, wordt software voor het klonen van stemmen gestruikeld door het feit dat mensen zakken vlees zijn die lucht door gaten in hun lichaam laten stromen om te praten.
"Ik blijf maar grappen maken dat deepfakes erg zeurderig zijn," zei Balasubramaniyan. Hij legde uit dat het voor algoritmen erg moeilijk is om de uiteinden van woorden te onderscheiden van achtergrondruis in een opname. Dit resulteert in veel spraakmodellen met spraak die meer wegglijdt dan mensen.
"Wanneer een algoritme dit vaak ziet gebeuren," zei Balasubramaniyan, "krijgt het statistisch gezien meer vertrouwen dat het audio is die wordt gegenereerd in plaats van menselijk."
Resemble AI pakt het detectieprobleem ook frontaal aan met de Resemblyzer, een open-source tool voor diepgaand leren beschikbaar op GitHub . Het kan nepstemmen detecteren en sprekerverificatie uitvoeren.
Het vereist waakzaamheid
Het is altijd moeilijk te raden wat de toekomst in petto heeft, maar deze technologie zal vrijwel zeker alleen maar beter worden. Bovendien kan iedereen mogelijk het slachtoffer worden - niet alleen bekende personen, zoals gekozen functionarissen of CEO's van banken.
"Ik denk dat we aan de vooravond staan van de eerste audio-inbreuk waarbij de stemmen van mensen worden gestolen," voorspelde Balasubramaniyan.
Op dit moment is het reële risico van audio-deepfakes echter laag. Er zijn al tools die synthetische video behoorlijk goed lijken te detecteren.
Bovendien lopen de meeste mensen geen risico op een aanval. Volgens Ajder werken de belangrijkste commerciële spelers "aan op maat gemaakte oplossingen voor specifieke klanten, en de meeste hebben redelijk goede ethische richtlijnen over met wie ze wel en niet zouden werken."
De echte dreiging ligt echter in het verschiet, zoals Ajder verder uitlegde:
"Pandora’s Box zal mensen zijn die open-source-implementaties van de technologie samenvoegen tot steeds gebruiksvriendelijkere, toegankelijke apps of services die niet zo'n ethische controlelaag hebben als commerciële oplossingen op dit moment."
Dit is waarschijnlijk onvermijdelijk, maar beveiligingsbedrijven rollen nep-audiodetectie al in hun toolkits. Maar om veilig te blijven, is waakzaamheid vereist.
"We hebben dit gedaan in andere beveiligingsgebieden", zei Ajder. "Veel organisaties besteden veel tijd aan het proberen te begrijpen wat bijvoorbeeld de volgende zero-day-kwetsbaarheid is. Synthetische audio is gewoon de volgende grens. "







