
Дипфейки из видео означают, что нельзя доверять всему, что видишь. Дипфейки аудио могут означать, что вы больше не можете доверять своим ушам. Неужели президент объявил войну Канаде? Это действительно твой папа по телефону спрашивает пароль от электронной почты?
Добавьте еще одно экзистенциальное беспокойство к списку того, как наше собственное высокомерие может неминуемо уничтожить нас. В эпоху Рейгана единственными реальными технологическими рисками были угрозы ядерной, химической и биологической войны.
В последующие годы у нас была возможность зацикливаться на серой слизи нанотехнологий и глобальных пандемиях. Теперь у нас есть дипфейки - люди теряют контроль над своим сходством или голосом.
Что такое аудио дипфейк?
Большинство из нас видели видео деепфаке , в котором алгоритмы глубокого обучения используются для замены одного человека на другого. Лучшие из них невероятно реалистичны, и теперь очередь за аудио. Аудио дипфейк - это когда «клонированный» голос, который потенциально неотличим от реального человека, используется для создания синтетического звука.
«Это как Photoshop для голоса», - сказал Зохайб Ахмед, генеральный директор Напоминать AI о технологии клонирования голоса его компании.
Однако плохие работы в Photoshop легко опровергнуть. Фирма по обеспечению безопасности, с которой мы говорили, сказала, что люди обычно только догадываются, является ли звуковой дипфейк настоящим или фальшивым, с точностью около 57 процентов - не лучше, чем подбрасывание монеты.
Кроме того, поскольку так много голосовых записей - это некачественные телефонные звонки (или записанные в шумных местах), дипфейки звука можно сделать еще более неразличимыми. Чем хуже качество звука, тем сложнее уловить эти явные признаки того, что голос не настоящий.
Но зачем вообще кому-то нужен фотошоп для голоса?
Убедительный аргумент в пользу синтетического звука
На самом деле спрос на синтетический звук огромен. По словам Ахмеда, «окупаемость инвестиций наступает очень быстро».
Это особенно верно, когда речь идет об играх. В прошлом речь была единственным компонентом игры, который невозможно было создать по запросу. Даже в интерактивных титрах со сценами кинематографического качества, визуализированными в реальном времени, вербальные взаимодействия с неиграющими персонажами всегда по существу статичны.
Однако теперь технологии догнали. Студии могут клонировать голос актера и использовать механизмы преобразования текста в речь, чтобы персонажи могли говорить что угодно в реальном времени.
Существуют также более традиционные способы использования в рекламе, технической поддержке и поддержке клиентов. Здесь важен голос, который звучит подлинно человеческим и реагирует лично и контекстуально без участия человека.
Компании, занимающиеся клонированием голоса, также заинтересованы в медицинских приложениях. Конечно, замена голоса не является чем-то новым в медицине - Стивен Хокинг, как известно, использовал синтезированный роботом голос после потери своего собственного в 1985 году. Однако современное клонирование голоса обещает кое-что еще лучше.
В 2008 году синтетическая голосовая компания CereProc - вернул покойному кинокритику Роджеру Эберту голос после того, как его забрал рак. CereProc опубликовала веб-страницу, на которой люди могли печатать сообщения, которые затем произносились голосом бывшего президента Джорджа Буша.
«Эберт увидел это и подумал:« Что ж, если они смогут копировать голос Буша, они смогут скопировать мой », - сказал Мэтью Айлетт, главный научный сотрудник CereProc. Затем Эберт попросил компанию создать новый голос, что они и сделали, обработав большую библиотеку голосовых записей.
«Это был один из первых случаев, когда кто-либо делал это, и это был настоящий успех», - сказал Айлетт.
В последние годы ряд компаний (в том числе CereProc) работали с Ассоциация ALS на Project Revoice для передачи синтетических голосов тем, кто страдает БАС.

Как работает синтетическое аудио
Сейчас у клонирования голоса наступает момент, и множество компаний разрабатывают инструменты. Напоминать AI а также Описание есть онлайн-демонстрации, которые каждый может попробовать бесплатно. Вы просто записываете фразы, которые появляются на экране, и всего за несколько минут создается модель вашего голоса.
Вы можете поблагодарить AI, в частности, алгоритмы глубокого обучения - для возможности сопоставить записанную речь с текстом, чтобы понять составляющие фонемы, составляющие ваш голос. Затем он использует полученные лингвистические строительные блоки для приблизительного определения слов, которых вы не слышали.
Базовая технология существует уже некоторое время, но, как указал Айлетт, она требует некоторой помощи.
«Копирование голоса было немного похоже на приготовление теста», - сказал он. «Это было довольно сложно, и приходилось настраивать его вручную разными способами, чтобы заставить работать».
Разработчикам требовалось огромное количество записанных голосовых данных, чтобы получить приемлемые результаты. Затем, несколько лет назад, шлюзы открылись. Исследования в области компьютерного зрения оказались очень важными. Ученые разработали генеративные состязательные сети (GAN), которые впервые могли экстраполировать и делать прогнозы на основе существующих данных.
«Вместо того, чтобы компьютер видел изображение лошади и говорил:« Это лошадь », моя модель теперь могла превратить лошадь в зебру», - сказал Айлетт. «Итак, взрыв в синтезе речи сейчас происходит благодаря академической работе компьютерного зрения».
Одним из самых больших нововведений в клонировании голоса стало общее сокращение количества необработанных данных, необходимых для создания голоса. Раньше системам требовались десятки или даже сотни часов звука. Однако теперь компетентные голоса можно сгенерировать из всего лишь нескольких минут контента.
СВЯЗАННЫЕ С: Проблема с ИИ: машины учатся, но не могут их понять
Экзистенциальный страх ничего не доверять
Эта технология, наряду с ядерной энергетикой, нанотехнологиями, 3D-печатью и CRISPR, одновременно захватывающая и устрашающая. В конце концов, в новостях уже были случаи, когда людей обманывали голосовыми клонами. В 2019 году компания в Великобритании заявила, что обманутый звуковой дипфейком телефонный звонок с целью пересылки денег преступникам.
Не нужно далеко ходить, чтобы найти удивительно убедительные звуковые подделки. YouTube канал Вокальный синтез известные люди говорят то, чего никогда не говорили, например Джордж Буш читает «In Da Club» 50 Cent . Это правильно.
В другом месте на YouTube вы можете услышать стаю экс-президентов, в том числе Обама, Клинтон и Рейган, читающие NWA . Музыка и фоновые звуки помогают замаскировать некоторые очевидные сбои робота, но даже в этом несовершенном состоянии потенциал очевиден.
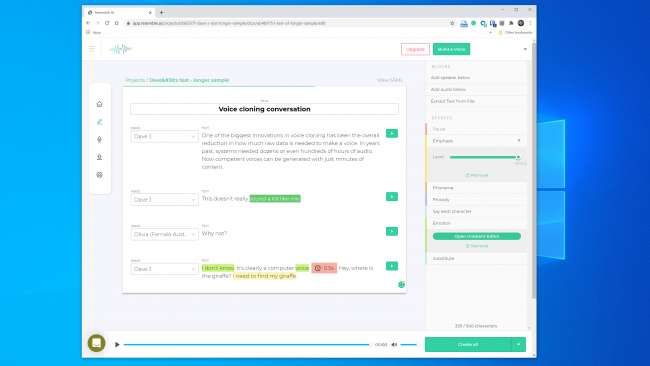
Мы экспериментировали с инструментами на Напоминать AI а также Описание и создал голосовой клон. Descript использует движок клонирования голоса, который изначально назывался Lyrebird и был особенно впечатляющим. Мы были шокированы качеством. Слышать, как ваш собственный голос говорит то, чего, как вы знаете, никогда не говорил, - это нервирует.
В речи определенно присутствует роботизированный характер, но при обычном прослушивании у большинства людей не будет причин думать, что это подделка.

У нас были еще большие надежды на Resemble AI. Он дает вам инструменты для создания разговора с несколькими голосами и изменения выразительности, эмоций и темпа диалога. Однако мы не думали, что модель голоса отражает основные качества голоса, который мы использовали. На самом деле, вряд ли кого-то обмануть.
Представитель компании Resemble AI сказал нам, что «большинство людей поражены результатами, если они сделают это правильно». Мы дважды построили голосовую модель с аналогичными результатами. Так что, очевидно, не всегда легко создать голосовой клон, который можно использовать для совершения цифрового ограбления.
Несмотря на это, основатель Lyrebird (который сейчас является частью Descript) Кундан Кумар считает, что мы уже преодолели этот порог.
«В небольшом количестве случаев он уже существует», - сказал Кумар. «Если я использую синтетический звук, чтобы изменить несколько слов в речи, он уже настолько хорош, что вам будет трудно понять, что изменилось».
Мы также можем предположить, что эта технология со временем станет только лучше. Системам потребуется меньше звука для создания модели, а более быстрые процессоры смогут построить модель в реальном времени. Более умный ИИ научится добавлять более убедительную человеческую ритмику и акцент на речи, не имея примера для работы.
Это означает, что мы, возможно, приближаемся к повсеместной доступности легкого клонирования голоса.
Этика ящика Пандоры
Большинство компаний, работающих в этой сфере, похоже, готовы обращаться с технологиями безопасным и ответственным образом. Наподобие ИИ, например, имеет целый раздел «Этика» на своем сайте , и следующий отрывок обнадеживает:
«Мы работаем с компаниями через строгий процесс, чтобы убедиться, что голос, который они клонируют, может быть использован ими, и что у нас есть надлежащие согласования с актерами».
Точно так же Кумар сказал, что Lyrebird с самого начала был обеспокоен неправильным использованием. Вот почему теперь, как часть Descript, он позволяет людям клонировать только собственный голос. Фактически, и Resemble, и Descript требуют, чтобы люди записывали свои образцы вживую, чтобы предотвратить несогласованное голосовое клонирование.
Отрадно, что основные коммерческие игроки установили некоторые этические принципы. Однако важно помнить, что эти компании не являются привратниками этой технологии. Уже существует ряд инструментов с открытым исходным кодом, для которых нет правил. По словам Генри Айдера, главы службы разведки угроз Deeptrace , вам также не нужны глубокие знания в области программирования, чтобы использовать его неправильно.
«Большой прогресс в этой области достигнут благодаря совместной работе в таких местах, как GitHub, с использованием реализаций с открытым исходным кодом ранее опубликованных научных статей», - сказал Адждер. «Его может использовать любой, у кого средний уровень программирования».
Профессионалы в области безопасности видели все это раньше
Преступники пытались украсть деньги по телефону задолго до того, как стало возможным клонирование голоса, и специалисты по безопасности всегда были на связи, чтобы обнаружить и предотвратить это. Охранное предприятие Пиндроп пытается остановить банковское мошенничество, проверяя, является ли звонящий тем, кем он или она себя называет, по аудио. Только в 2019 году Пиндроп утверждает, что проанализировал 1,2 миллиарда голосовых взаимодействий и предотвратил попытки мошенничества на сумму около 470 миллионов долларов.
До клонирования голоса мошенники испробовали ряд других приемов. Самым простым было просто позвонить из другого места и сообщить личную информацию о знаке.
«Наша акустическая сигнатура позволяет нам определить, что звонок действительно поступает с телефона Skype в Нигерии, по звуковым характеристикам», - сказал генеральный директор Pindrop Виджай Баласубраманиян. «Затем мы можем сравнить это, зная, что клиент пользуется телефоном AT&T в Атланте».
Некоторые преступники также сделали карьеру, используя фоновые звуки, чтобы сбить с толку банковских представителей.
«Есть мошенник, которого мы звали Цыпленок, у которого всегда были петухи на заднем плане, - сказал Баласубраманиян. «И есть одна женщина, которая использовала плачущего ребенка на заднем плане, чтобы убедить агентов колл-центра, что« эй, я сейчас переживаю трудные времена », чтобы вызвать сочувствие».
Кроме того, есть преступники-мужчины, которые захватывают банковские счета женщин.
«Они используют технологии, чтобы повысить частоту своего голоса, чтобы он звучал более женственно», - пояснил Баласубраманиян. Они могут быть успешными, но «иногда программное обеспечение дает сбой, и они звучат как Элвин и бурундуки».
Конечно, клонирование голоса - это всего лишь последняя разработка в этой постоянно обостряющейся войне. Охранные фирмы уже поймали мошенников, использующих синтетический звук, по крайней мере, в одной подводной охоте.
«При правильной цели выплаты могут быть огромными», - сказал Баласубраманиян. «Итак, имеет смысл посвятить время созданию синтезированного голоса правильного человека».
Кто-нибудь может сказать, фальшивый ли голос?

Когда дело доходит до распознавания подделки голоса, есть как хорошие, так и плохие новости. Плохо то, что голосовые клоны становятся лучше с каждым днем. Системы глубокого обучения становятся умнее и воспроизводят более аутентичные голоса, для создания которых требуется меньше звука.
Как видно из этого ролика Президент Обама говорит MC Ren занять позицию , мы также уже достигли точки, когда высококачественная, тщательно построенная модель голоса может звучать довольно убедительно для человеческого уха.
Чем длиннее аудиоклип, тем выше вероятность, что вы заметите что-то неладное. Однако для более коротких роликов вы можете не заметить, что они синтетические, особенно если у вас нет причин сомневаться в их законности.
Чем четче качество звука, тем легче заметить признаки дипфейка звука. Если кто-то говорит прямо в микрофон студийного качества, вы сможете внимательно слушать. А вот некачественную запись телефонного разговора или разговор, записанный на портативное устройство в шумной парковке, будет гораздо сложнее оценить.
Хорошая новость в том, что даже если людям трудно отличить реальное от подделки, у компьютеров нет таких ограничений. К счастью, инструменты голосовой проверки уже существуют. У Пиндропа есть одна, которая противопоставляет системы глубокого обучения друг другу. Он использует и то, и другое, чтобы определить, является ли аудиосэмпл тем человеком, которым он должен быть. Однако он также проверяет, может ли человек вообще издавать все звуки в образце.
В зависимости от качества звука каждая секунда речи содержит от 8 000 до 50 000 выборок данных, которые могут быть проанализированы.
«То, что мы обычно ищем, - это ограничения речи из-за эволюции человека», - пояснил Баласубраманиян.
Например, два вокальных звука имеют минимально возможное расстояние друг от друга. Это потому, что физически невозможно произнести их быстрее из-за скорости, с которой мышцы во рту и голосовые связки могут перенастраивать себя.
«Когда мы смотрим на синтезированный звук, - сказал Баласубраманиян, - мы иногда видим вещи и говорим:« Это никогда не могло быть создано человеком, потому что единственный человек, который мог бы это создать, должен иметь шею семи футов длиной. ”
Есть еще один класс звуков, называемых фрикативными. Они образуются, когда воздух проходит через узкое сужение в вашем горле, когда вы произносите такие буквы, как f, s, v и z. Системам глубокого обучения особенно сложно освоить фрикативы, потому что программному обеспечению трудно отличить их от шума.
Так что, по крайней мере на данный момент, программы для клонирования голоса сбиты с толку тем фактом, что люди представляют собой мешки с мясом, через которые воздух проходит через отверстия в теле, чтобы говорить.
«Я все время шучу, что дипфейки очень плаксивые», - сказал Баласубраманиян. Он объяснил, что алгоритмам очень сложно отличить концы слов от фонового шума в записи. Это приводит к тому, что многие модели голоса затихают чаще, чем люди.
«Когда алгоритм видит, что это происходит часто, - сказал Баласубраманиян, - статистически он становится более уверенным, что это звук, который был сгенерирован, а не человеческий».
Компания Resemble AI также решает проблему обнаружения с помощью Resemblyzer, инструмента глубокого обучения с открытым исходным кодом. доступно на GitHub . Он может обнаруживать поддельные голоса и выполнять проверку говорящего.
Требуется бдительность
Всегда трудно угадать, что нас ждет в будущем, но эта технология почти наверняка станет только лучше. Кроме того, любой потенциально может стать жертвой, а не только высокопоставленные лица, такие как выборные должностные лица или руководители банков.
«Я думаю, что мы находимся на грани первого нарушения звука, когда у людей украдут голоса», - предсказал Баласубраманиян.
Однако на данный момент реальный риск звуковых дипфейков невелик. Уже есть инструменты, которые неплохо справляются с обнаружением синтетического видео.
Кроме того, большинство людей не подвергаются риску нападения. По словам Айдера, основные коммерческие игроки «работают над индивидуальными решениями для конкретных клиентов, и у большинства из них есть довольно хорошие этические принципы в отношении того, с кем они будут и не будут работать».
Однако настоящая угроза впереди, как пояснил Адждер:
«Pandora’s Box - это люди, объединяющие реализации технологии с открытым исходным кодом во все более удобные и доступные приложения или сервисы, которые не имеют такого этического уровня контроля, как в настоящее время коммерческие решения».
Это, вероятно, неизбежно, но охранные компании уже внедряют фальшивое обнаружение звука в свои наборы инструментов. Тем не менее, чтобы оставаться в безопасности, нужно проявлять бдительность.
«Мы сделали это и в других областях безопасности», - сказал Адждер. «Многие организации тратят много времени, пытаясь понять, например, какова следующая уязвимость нулевого дня. Синтетический звук - это просто следующий рубеж ».
СВЯЗАННЫЕ С: Что такое дипфейк и стоит ли мне беспокоиться?







