
I deepfake video significano che non puoi fidarti di tutto ciò che vedi. Ora, i deepfake audio potrebbero significare che non puoi più fidarti delle tue orecchie. Era davvero il presidente che dichiarava guerra al Canada? È davvero tuo padre al telefono che chiede la sua password e-mail?
Aggiungi un'altra preoccupazione esistenziale all'elenco di come la nostra stessa arroganza potrebbe inevitabilmente distruggerci. Durante l'era Reagan, gli unici veri rischi tecnologici erano la minaccia di una guerra nucleare, chimica e biologica.
Negli anni successivi, abbiamo avuto l'opportunità di ossessionarci per la sostanza grigia delle nanotecnologie e le pandemie globali. Ora, abbiamo i deepfake: persone che perdono il controllo sulla loro somiglianza o voce.
Cos'è un Deepfake audio?
La maggior parte di noi ha visto un file video deepfake , in cui vengono utilizzati algoritmi di apprendimento profondo per sostituire una persona con la somiglianza di qualcun altro. I migliori sono estremamente realistici e ora è il turno dell'audio. Un deepfake audio si verifica quando una voce "clonata" potenzialmente indistinguibile da quella della persona reale viene utilizzata per produrre audio sintetico.
"È come Photoshop per la voce", ha affermato Zohaib Ahmed, CEO di Resemble AI , sulla tecnologia di clonazione vocale della sua azienda.
Tuttavia, i cattivi lavori di Photoshop sono facilmente smascherati. Una società di sicurezza con cui abbiamo parlato ha detto che le persone di solito immaginano solo se un deepfake audio è reale o falso con una precisione del 57% circa, non meglio di un lancio di moneta.
Inoltre, poiché molte registrazioni vocali sono di telefonate di bassa qualità (o registrate in luoghi rumorosi), i deepfake audio possono essere resi ancora più indistinguibili. Peggio è la qualità del suono, più difficile è cogliere quei segni rivelatori che una voce non è reale.
Ma perché qualcuno dovrebbe aver bisogno di un Photoshop per le voci, comunque?
Il caso avvincente per l'audio sintetico
In realtà c'è un'enorme richiesta di audio sintetico. Secondo Ahmed, "il ROI è molto immediato".
Ciò è particolarmente vero quando si tratta di giochi. In passato, la parola era l'unica componente di un gioco che era impossibile creare su richiesta. Anche nei titoli interattivi con scene di qualità cinematografica rese in tempo reale, le interazioni verbali con i personaggi che non giocano sono sempre essenzialmente statiche.
Ora, però, la tecnologia ha recuperato. Gli studi hanno il potenziale per clonare la voce di un attore e utilizzare motori di sintesi vocale in modo che i personaggi possano dire qualsiasi cosa in tempo reale.
Esistono anche usi più tradizionali nella pubblicità e nell'assistenza tecnica e ai clienti. In questo caso, ciò che conta è una voce che suoni autenticamente umana e che risponda personalmente e contestualmente senza l'input umano.
Anche le aziende di clonazione vocale sono entusiaste delle applicazioni mediche. Naturalmente, la sostituzione della voce non è una novità in medicina: Stephen Hawking usò notoriamente una voce sintetizzata robotica dopo aver perso la sua nel 1985. Tuttavia, la clonazione vocale moderna promette qualcosa di ancora migliore.
Nel 2008, società di voce sintetica, CereProc , ha restituito al critico cinematografico Roger Ebert la sua voce dopo che il cancro l'ha portata via. CereProc aveva pubblicato una pagina web che permetteva alle persone di digitare messaggi che sarebbero poi stati pronunciati con la voce dell'ex presidente George Bush.
"Ebert lo vide e pensò, 'beh, se potessero copiare la voce di Bush, dovrebbero essere in grado di copiare la mia'", ha detto Matthew Aylett, direttore scientifico di CereProc. Ebert ha quindi chiesto alla società di creare una voce sostitutiva, cosa che hanno fatto elaborando una vasta libreria di registrazioni vocali.
"È stata una delle prime volte che qualcuno l'aveva mai fatto ed è stato un vero successo", ha detto Aylett.
Negli ultimi anni, diverse società (inclusa CereProc) hanno collaborato con Associazione SLA su Project Revoice fornire voci sintetiche a chi soffre di SLA.

Come funziona l'audio sintetico
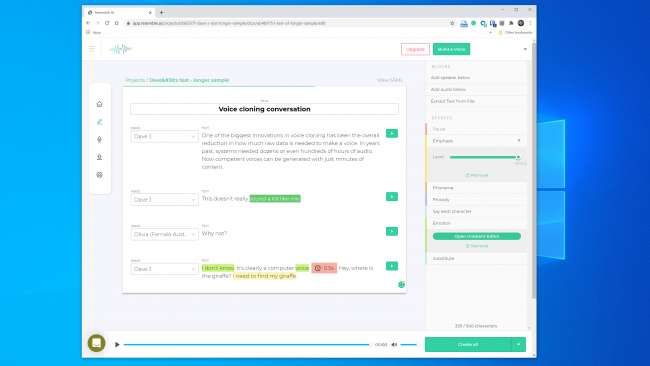
La clonazione vocale sta avendo un momento in questo momento e un gran numero di aziende stanno sviluppando strumenti. Resemble AI e Descript avere demo online che chiunque può provare gratuitamente. Devi solo registrare le frasi che appaiono sullo schermo e, in pochi minuti, viene creato un modello della tua voce.
Puoi ringraziare l'IA, in particolare algoritmi di deep learning —Per essere in grado di abbinare il parlato registrato al testo per comprendere i fonemi che compongono la tua voce. Quindi utilizza i blocchi linguistici risultanti per approssimare le parole che non ti ha sentito pronunciare.
La tecnologia di base esiste da un po ', ma come ha sottolineato Aylett, ha richiesto un po' di aiuto.
"Copiare la voce era un po 'come fare un pasticcino", ha detto. "Era un po 'difficile da fare e c'erano vari modi per modificarlo a mano per farlo funzionare."
Gli sviluppatori avevano bisogno di enormi quantità di dati vocali registrati per ottenere risultati accettabili. Poi, qualche anno fa, le paratoie si sono aperte. La ricerca nel campo della visione artificiale si è rivelata fondamentale. Gli scienziati hanno sviluppato reti generative antagoniste (GAN), che potrebbero, per la prima volta, estrapolare e fare previsioni sulla base dei dati esistenti.
"Invece di un computer che vede la foto di un cavallo e dice" questo è un cavallo ", il mio modello ora potrebbe trasformare un cavallo in una zebra", ha detto Aylett. "Quindi, l'esplosione della sintesi vocale ora è grazie al lavoro accademico della visione artificiale."
Una delle più grandi innovazioni nella clonazione vocale è stata la riduzione complessiva della quantità di dati grezzi necessari per creare una voce. In passato, i sistemi richiedevano dozzine o addirittura centinaia di ore di audio. Ora, tuttavia, è possibile generare voci competenti da pochi minuti di contenuto.
RELAZIONATO: Il problema con l'IA: le macchine stanno imparando cose, ma non riescono a capirle
La paura esistenziale di non fidarsi di nulla
Questa tecnologia, insieme all'energia nucleare, alle nanotecnologie, alla stampa 3D e al CRISPR, è allo stesso tempo elettrizzante e terrificante. Dopotutto, ci sono già stati casi nelle notizie di persone ingannate da cloni vocali. Nel 2019, una società nel Regno Unito ha affermato di sì ingannato da un deepfake audio telefonata per trasferire denaro ai criminali.
Non devi nemmeno andare lontano per trovare falsi audio sorprendentemente convincenti. Canale Youtube Sintesi vocale presenta persone famose che dicono cose che non hanno mai detto, come George W. Bush che legge "In Da Club" di 50 Cent . È perfetto.
Altrove su YouTube, puoi sentire uno stormo di ex presidenti, incluso Obama, Clinton e Reagan, rappando NWA . La musica e i suoni di sottofondo aiutano a mascherare alcune delle evidenti anomalie robotiche, ma anche in questo stato imperfetto, il potenziale è ovvio.
Abbiamo sperimentato gli strumenti Resemble AI e Descript e ha creato la voce clone. Descript utilizza un motore di clonazione vocale originariamente chiamato Lyrebird ed era particolarmente impressionante. Siamo rimasti scioccati dalla qualità. Ascoltare la tua stessa voce dire cose che sai di non aver mai detto è snervante.
C'è sicuramente una qualità robotica nel discorso, ma ad un ascolto casuale, la maggior parte delle persone non avrebbe motivo di pensare che fosse un falso.

Avevamo speranze ancora maggiori per Resemble AI. Offre gli strumenti per creare una conversazione con più voci e variare l'espressività, l'emozione e il ritmo del dialogo. Tuttavia, non pensavamo che il modello vocale catturasse le qualità essenziali della voce che abbiamo usato. In effetti, era improbabile che ingannasse qualcuno.
Un rappresentante di Resemble AI ci ha detto che "la maggior parte delle persone rimane sbalordita dai risultati se lo fa correttamente". Abbiamo costruito due volte un modello vocale con risultati simili. Quindi, evidentemente, non è sempre facile creare un clone vocale che puoi usare per eseguire una rapina digitale.
Anche così, il fondatore di Lyrebird (che ora fa parte di Descript), Kundan Kumar, ritiene che abbiamo già superato quella soglia.
"Per una piccola percentuale di casi, è già lì", ha detto Kumar. "Se uso l'audio sintetico per cambiare alcune parole in un discorso, è già così buono che avrai difficoltà a sapere cosa è cambiato."
Possiamo anche presumere che questa tecnologia migliorerà solo con il tempo. I sistemi avranno bisogno di meno audio per creare un modello e processori più veloci saranno in grado di costruire il modello in tempo reale. L'intelligenza artificiale più intelligente imparerà come aggiungere una cadenza simile a quella umana e un'enfasi sulla parola più convincente senza avere un esempio su cui lavorare.
Ciò significa che potremmo avvicinarci di soppiatto alla disponibilità diffusa della clonazione vocale senza sforzo.
L'etica del vaso di Pandora
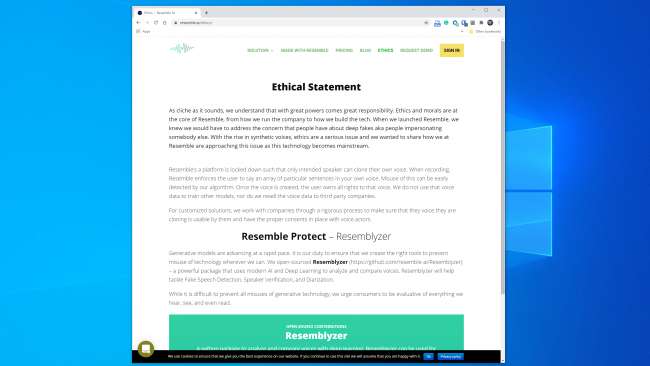
La maggior parte delle aziende che lavorano in questo settore sembra pronta a gestire la tecnologia in modo sicuro e responsabile. Assomiglia a AI, per esempio, ha un'intera sezione “Etica” sul proprio sito web e il seguente estratto è incoraggiante:
"Lavoriamo con le aziende attraverso un processo rigoroso per assicurarci che la voce che stanno clonando sia utilizzabile da loro e abbia i consensi appropriati con i doppiatori".
Allo stesso modo, Kumar ha detto che Lyrebird era preoccupato per l'uso improprio sin dall'inizio. Ecco perché ora, come parte di Descript, consente alle persone di clonare solo la propria voce. In effetti, sia Resemble che Descript richiedono che le persone registrino i loro campioni dal vivo per prevenire la clonazione vocale non consensuale.
È incoraggiante che i principali attori commerciali abbiano imposto alcune linee guida etiche. Tuttavia, è importante ricordare che queste aziende non sono custodi di questa tecnologia. Esistono già numerosi strumenti open source per i quali non esistono regole. Secondo Henry Ajder, capo dell'intelligence sulle minacce di Deeptrace , inoltre, non hai bisogno di conoscenze avanzate di codifica per abusarne.
"Molti progressi nello spazio sono avvenuti attraverso il lavoro di collaborazione in luoghi come GitHub, utilizzando implementazioni open source di documenti accademici pubblicati in precedenza", ha detto Ajder. "Può essere utilizzato da chiunque abbia una discreta competenza nella programmazione."
I professionisti della sicurezza hanno già visto tutto questo
I criminali hanno cercato di rubare denaro per telefono molto prima che fosse possibile la clonazione vocale e gli esperti di sicurezza sono sempre stati a disposizione per rilevarlo e prevenirlo. Azienda di sicurezza Pindrop cerca di fermare le frodi bancarie verificando se un chiamante è chi afferma di essere dall'audio. Solo nel 2019, Pindrop afferma di aver analizzato 1,2 miliardi di interazioni vocali e prevenuto circa $ 470 milioni in tentativi di frode.
Prima della clonazione vocale, i truffatori hanno provato una serie di altre tecniche. Il più semplice è stato chiamare da altrove con informazioni personali sul marchio.
"La nostra firma acustica ci consente di determinare che una chiamata proviene effettivamente da un telefono Skype in Nigeria a causa delle caratteristiche del suono", ha affermato Vijay Balasubramaniyan, CEO di Pindrop. "Quindi, possiamo confrontare il fatto che sapendo che il cliente utilizza un telefono AT&T ad Atlanta."
Alcuni criminali hanno anche fatto carriera usando i suoni di sottofondo per eliminare i rappresentanti bancari.
"C'è un truffatore che abbiamo chiamato Chicken Man che aveva sempre galli in sottofondo", ha detto Balasubramaniyan. "E c'è una signora che ha usato un bambino che piangeva in sottofondo per convincere essenzialmente gli agenti del call center, che 'hey, sto attraversando un momento difficile' per ottenere simpatia".
E poi ci sono i criminali maschi che inseguono i conti bancari delle donne.
"Usano la tecnologia per aumentare la frequenza della loro voce, per sembrare più femminile", ha spiegato Balasubramaniyan. Questi possono avere successo, ma "occasionalmente, il software fa un casino e suonano come Alvin and the Chipmunks".
Naturalmente, la clonazione vocale è solo l'ultimo sviluppo in questa guerra in continua escalation. Le aziende di sicurezza hanno già catturato i truffatori che utilizzano audio sintetico in almeno un attacco di pesca subacquea.
"Con il giusto obiettivo, il pagamento può essere enorme", ha detto Balasubramaniyan. "Quindi, ha senso dedicare il tempo per creare una voce sintetizzata dell'individuo giusto."
Qualcuno sa se una voce è falsa?

Quando si tratta di riconoscere se una voce è stata falsificata, ci sono buone e cattive notizie. Il problema è che i cloni vocali migliorano ogni giorno. I sistemi di deep learning stanno diventando più intelligenti e stanno producendo voci più autentiche che richiedono meno audio per essere create.
Come puoi vedere da questa clip di Il presidente Obama dice a MC Ren di prendere posizione , siamo anche già arrivati al punto in cui un modello vocale ad alta fedeltà e costruito con cura può sembrare abbastanza convincente all'orecchio umano.
Più è lungo un clip audio, più è probabile che noterai che c'è qualcosa di sbagliato. Per clip più brevi, tuttavia, potresti non notare che è sintetico, soprattutto se non hai motivo di metterne in dubbio la legittimità.
Più chiara è la qualità del suono, più facile è notare i segni di un deepfake audio. Se qualcuno parla direttamente in un microfono di qualità da studio, sarai in grado di ascoltare da vicino. Ma una registrazione di una telefonata di scarsa qualità o una conversazione catturata su un dispositivo portatile in un parcheggio rumoroso sarà molto più difficile da valutare.
La buona notizia è che, anche se gli esseri umani hanno problemi a separare il reale dal falso, i computer non hanno le stesse limitazioni. Fortunatamente, esistono già strumenti di verifica vocale. Pindrop ne ha uno che mette l'uno contro l'altro i sistemi di apprendimento profondo. Utilizza entrambi per scoprire se un campione audio è la persona che dovrebbe essere. Tuttavia, esamina anche se un essere umano può persino emettere tutti i suoni nel campione.
A seconda della qualità dell'audio, ogni secondo del parlato contiene tra 8.000-50.000 campioni di dati che possono essere analizzati.
"Le cose che tipicamente cerchiamo sono limitazioni alla parola a causa dell'evoluzione umana", ha spiegato Balasubramaniyan.
Ad esempio, due suoni vocali hanno una separazione minima possibile l'uno dall'altro. Questo perché non è fisicamente possibile pronunciarli più velocemente a causa della velocità con cui i muscoli della bocca e le corde vocali possono riconfigurarsi.
“Quando guardiamo all'audio sintetizzato”, ha detto Balasubramaniyan, “a volte vediamo cose e diciamo, 'questo non avrebbe mai potuto essere generato da un essere umano perché l'unica persona che avrebbe potuto generare questo deve avere un collo lungo sette piedi. "
C'è anche una classe di suoni chiamata "fricative". Si formano quando l'aria passa attraverso una stretta costrizione nella tua gola quando pronunci lettere come f, s, v e z. Le fricative sono particolarmente difficili da padroneggiare per i sistemi di apprendimento profondo perché il software ha difficoltà a differenziarle dal rumore.
Quindi, almeno per ora, il software di clonazione vocale è inciampato dal fatto che gli umani sono sacchi di carne che fanno scorrere l'aria attraverso i buchi del loro corpo per parlare.
"Continuo a scherzare sul fatto che i deepfake sono molto piagnucolosi", ha detto Balasubramaniyan. Ha spiegato che è molto difficile per gli algoritmi distinguere le estremità delle parole dal rumore di fondo in una registrazione. Ciò si traduce in molti modelli vocali con un discorso che si attenua più degli umani.
"Quando un algoritmo vede che questo accade spesso", ha detto Balasubramaniyan, "statisticamente, diventa più sicuro che sia l'audio che è stato generato anziché quello umano".
Resemble AI sta anche affrontando il problema del rilevamento a testa alta con Resemblyzer, uno strumento di apprendimento profondo open source disponibile su GitHub . Può rilevare voci false ed eseguire la verifica dell'altoparlante.
Ci vuole vigilanza
È sempre difficile indovinare cosa potrebbe riservare il futuro, ma questa tecnologia quasi certamente migliorerà solo. Inoltre, chiunque potrebbe potenzialmente essere una vittima, non solo individui di alto profilo, come funzionari eletti o amministratori delegati di banche.
"Penso che siamo sull'orlo della prima violazione audio in cui le voci delle persone vengono rubate", ha predetto Balasubramaniyan.
Al momento, tuttavia, il rischio reale derivante dai deepfake audio è basso. Esistono già strumenti che sembrano fare un buon lavoro nel rilevare video sintetici.
Inoltre, la maggior parte delle persone non è a rischio di un attacco. Secondo Ajder, i principali attori commerciali "stanno lavorando a soluzioni su misura per clienti specifici e la maggior parte ha linee guida etiche abbastanza buone su chi vorrebbe e non lavorerebbe".
La vera minaccia si trova davanti, però, come Ajder ha continuato a spiegare:
"Il vaso di Pandora sarà composto da persone che combinano le implementazioni open source della tecnologia in app o servizi sempre più user-friendly e accessibili che non hanno quel tipo di livello di controllo etico che le soluzioni commerciali hanno al momento".
Questo è probabilmente inevitabile, ma le società di sicurezza stanno già inserendo il rilevamento dell'audio falso nei loro toolkit. Tuttavia, stare al sicuro richiede vigilanza.
"L'abbiamo fatto in altre aree di sicurezza", ha detto Ajder. "Molte organizzazioni trascorrono molto tempo cercando di capire quale sia la prossima vulnerabilità zero-day, ad esempio. L'audio sintetico è semplicemente la prossima frontiera ".
RELAZIONATO: Cos'è un deepfake e dovrei essere preoccupato?







