
วิดีโอเจาะลึกหมายความว่าคุณไม่สามารถเชื่อถือทุกสิ่งที่คุณเห็นได้ ตอนนี้เสียงเจาะลึกอาจหมายความว่าคุณไม่สามารถวางใจหูของคุณได้อีกต่อไป นั่นคือประธานาธิบดีประกาศสงครามกับแคนาดาจริงหรือ? นั่นคือพ่อของคุณที่โทรศัพท์ขอรหัสผ่านอีเมลของเขาจริงหรือ?
เพิ่มความกังวลอื่น ๆ ที่มีอยู่ในรายการว่าความโอหังของเราอาจทำลายเราอย่างหลีกเลี่ยงไม่ได้ ในช่วงยุคเรแกนความเสี่ยงทางเทคโนโลยีที่แท้จริงเพียงอย่างเดียวคือภัยคุกคามจากสงครามนิวเคลียร์เคมีและชีวภาพ
ในปีต่อ ๆ ไปเรามีโอกาสที่จะหมกมุ่นอยู่กับสารที่หนาสีเทาของนาโนเทคและการระบาดทั่วโลก ตอนนี้เรามีของปลอม - ผู้คนที่สูญเสียการควบคุมรูปลักษณ์หรือเสียงของพวกเขา
Audio Deepfake คืออะไร?
พวกเราส่วนใหญ่เคยเห็นไฟล์ วิดีโอ deepfake ซึ่งอัลกอริทึมการเรียนรู้เชิงลึกจะใช้เพื่อแทนที่คน ๆ หนึ่งด้วยความคล้ายคลึงของคนอื่น สิ่งที่ดีที่สุดคือความสมจริงที่ไม่น่ากลัวและตอนนี้ก็ถึงคราวของเสียง การเจาะลึกเสียงคือการใช้เสียงที่ "ลอกเลียนแบบ" ซึ่งอาจแยกไม่ออกจากเสียงของคนจริงเพื่อสร้างเสียงสังเคราะห์
“ มันเหมือนกับ Photoshop สำหรับเสียง” Zohaib Ahmed ซีอีโอของกล่าว คล้ายกับ AI เกี่ยวกับเทคโนโลยีการโคลนเสียงของ บริษัท ของเขา
อย่างไรก็ตามงาน Photoshop ที่ไม่ดีสามารถแก้ไขได้ง่าย บริษัท รักษาความปลอดภัยที่เราพูดคุยด้วยกล่าวว่าผู้คนมักจะเดาได้ว่าเสียงในรายละเอียดเสียงนั้นเป็นของจริงหรือของปลอมโดยมีความแม่นยำประมาณ 57 เปอร์เซ็นต์ซึ่งไม่ดีไปกว่าการพลิกเหรียญ
นอกจากนี้เนื่องจากการบันทึกเสียงจำนวนมากเป็นโทรศัพท์คุณภาพต่ำ (หรือบันทึกในสถานที่ที่มีเสียงดัง) การปลอมแปลงเสียงจึงสามารถแยกออกจากกันไม่ได้ ยิ่งคุณภาพเสียงแย่ลงเท่าใดก็ยิ่งยากที่จะรับสัญญาณที่บ่งบอกว่าเสียงนั้นไม่จริง
แต่ทำไมทุกคนถึงต้องการ Photoshop สำหรับเสียงล่ะ?
เคสที่น่าสนใจสำหรับเสียงสังเคราะห์
มีความต้องการเสียงสังเคราะห์อย่างมาก ตามที่ Ahmed กล่าวว่า“ ROI นั้นเกิดขึ้นทันที”
โดยเฉพาะอย่างยิ่งเมื่อพูดถึงการเล่นเกม ในอดีตคำพูดเป็นองค์ประกอบหนึ่งในเกมที่ไม่สามารถสร้างตามความต้องการได้ แม้ในชื่อเรื่องแบบอินเทอร์แอกทีฟที่มีฉากคุณภาพระดับโรงภาพยนตร์ที่แสดงผลแบบเรียลไทม์การโต้ตอบด้วยวาจากับตัวละครที่ไม่ได้เล่นก็ยังคงอยู่เสมอ
แม้ว่าตอนนี้เทคโนโลยีได้ตามทัน สตูดิโอมีศักยภาพในการลอกเลียนเสียงของนักแสดงและใช้เครื่องมือแปลงข้อความเป็นคำพูดเพื่อให้ตัวละครพูดอะไรก็ได้แบบเรียลไทม์
นอกจากนี้ยังมีการใช้งานแบบดั้งเดิมมากขึ้นในการโฆษณาและการสนับสนุนด้านเทคนิคและลูกค้า สิ่งที่สำคัญคือเสียงที่ฟังดูเป็นมนุษย์โดยแท้และตอบสนองตามบริบทโดยส่วนตัวและตามบริบท
บริษัท โคลนเสียงต่างก็ตื่นเต้นกับการใช้งานทางการแพทย์เช่นกัน แน่นอนว่าการเปลี่ยนเสียงไม่ใช่เรื่องใหม่ในทางการแพทย์สตีเฟนฮอว์คิงมีชื่อเสียงในด้านการใช้เสียงสังเคราะห์จากหุ่นยนต์หลังจากสูญเสียเสียงของตัวเองในปี 2528 อย่างไรก็ตามการโคลนเสียงสมัยใหม่ให้คำมั่นสัญญาว่าจะมีบางอย่างที่ดียิ่งขึ้น
ในปี 2008 บริษัท เสียงสังเคราะห์ CereProc โรเจอร์เอเบิร์ตนักวิจารณ์ภาพยนตร์ผู้ล่วงลับให้เสียงของเขากลับมาหลังจากที่มะเร็งพรากมันไป CereProc ได้เผยแพร่หน้าเว็บที่อนุญาตให้ผู้คนพิมพ์ข้อความที่จะพูดด้วยเสียงของอดีตประธานาธิบดีจอร์จบุช
“ เอเบิร์ตเห็นเช่นนั้นและคิดว่า ‘ถ้าพวกเขาสามารถลอกเลียนเสียงของบุชได้พวกเขาก็น่าจะลอกของฉันได้’” Matthew Aylett หัวหน้าเจ้าหน้าที่วิทยาศาสตร์ของ CereProc กล่าว จากนั้น Ebert ขอให้ บริษัท สร้างเสียงทดแทนซึ่งพวกเขาทำโดยการประมวลผลการบันทึกเสียงขนาดใหญ่
“ นี่เป็นหนึ่งในครั้งแรกที่ทุกคนเคยทำและมันก็ประสบความสำเร็จอย่างแท้จริง” Aylett กล่าว
ในช่วงไม่กี่ปีที่ผ่านมา บริษัท หลายแห่ง (รวมถึง CereProc) ได้ทำงานร่วมกับ สมาคม ALS บน โครงการ Revoice เพื่อให้เสียงสังเคราะห์แก่ผู้ที่เป็นโรค ALS

วิธีการทำงานของเสียงสังเคราะห์
การโคลนเสียงกำลังมีช่วงเวลาหนึ่งและ บริษัท จำนวนหนึ่งกำลังพัฒนาเครื่องมือ คล้ายกับ AI และ คำอธิบาย มีการสาธิตออนไลน์ที่ทุกคนสามารถทดลองใช้ได้ฟรี คุณเพียงแค่บันทึกวลีที่ปรากฏบนหน้าจอและเพียงไม่กี่นาทีรูปแบบเสียงของคุณก็จะถูกสร้างขึ้น
คุณสามารถขอบคุณ AI โดยเฉพาะ อัลกอริทึมการเรียนรู้เชิงลึก - เพื่อให้สามารถจับคู่คำพูดที่บันทึกไว้กับข้อความเพื่อทำความเข้าใจหน่วยเสียงที่ประกอบเป็นเสียงของคุณ จากนั้นจะใช้หน่วยการสร้างทางภาษาที่เป็นผลลัพธ์เพื่อประมาณคำที่คุณไม่เคยได้ยินมาก่อน
เทคโนโลยีพื้นฐานมีมาระยะหนึ่งแล้ว แต่ตามที่ Aylett ชี้ให้เห็นว่ามันต้องการความช่วยเหลือ
“ เสียงคัดลอกก็เหมือนกับการทำขนม” เขากล่าว “ เป็นเรื่องยากที่จะทำและมีหลายวิธีที่คุณต้องปรับแต่งด้วยมือเพื่อให้ใช้งานได้จริง”
นักพัฒนาต้องการข้อมูลเสียงที่บันทึกไว้จำนวนมหาศาลเพื่อให้ได้ผลลัพธ์ที่ผ่านได้ จากนั้นไม่กี่ปีที่ผ่านมาประตูระบายน้ำได้เปิดออก การวิจัยในสาขาการมองเห็นคอมพิวเตอร์พิสูจน์แล้วว่ามีความสำคัญ นักวิทยาศาสตร์ได้พัฒนาเครือข่ายปฏิปักษ์ทางพันธุกรรม (Generative adversarial Network: GANs) ซึ่งสามารถคาดการณ์และคาดการณ์ได้เป็นครั้งแรกโดยอาศัยข้อมูลที่มีอยู่
“ แทนที่จะให้คอมพิวเตอร์เห็นภาพม้าและพูดว่า ‘นี่คือม้า’ ตอนนี้นางแบบของฉันสามารถทำให้ม้ากลายเป็นม้าลายได้” Aylett กล่าว “ ดังนั้นการสังเคราะห์เสียงพูดที่ระเบิดในขณะนี้ต้องขอบคุณผลงานทางวิชาการจากการมองเห็นด้วยคอมพิวเตอร์”
หนึ่งในนวัตกรรมที่ใหญ่ที่สุดในการโคลนเสียงคือการลดจำนวนข้อมูลดิบที่จำเป็นในการสร้างเสียงโดยรวม ในอดีตระบบต้องการเสียงหลายสิบหรือหลายร้อยชั่วโมง อย่างไรก็ตามตอนนี้สามารถสร้างเสียงที่มีอำนาจได้จากเนื้อหาเพียงไม่กี่นาที
ที่เกี่ยวข้อง: ปัญหาเกี่ยวกับ AI: เครื่องจักรกำลังเรียนรู้สิ่งต่าง ๆ แต่ไม่สามารถเข้าใจได้
ความกลัวที่มีอยู่ของการไม่ไว้วางใจสิ่งใด ๆ
เทคโนโลยีนี้พร้อมกับพลังงานนิวเคลียร์นาโนเทคการพิมพ์ 3 มิติและ CRISPR นั้นน่าตื่นเต้นและน่ากลัวไปพร้อม ๆ กัน ท้ายที่สุดแล้วมีกรณีข่าวคนถูกโคลนเสียงหลอก ในปี 2019 บริษัท ในสหราชอาณาจักรอ้างว่าเป็น หลอกโดย deepfake เสียง โทรศัพท์เพื่อเดินสายเงินให้กับอาชญากร
คุณไม่ต้องไปไกลเพื่อค้นหาการปลอมเสียงที่น่าเชื่ออย่างน่าประหลาดใจอีกด้วย ช่อง YouTube การสังเคราะห์เสียง แสดงให้คนรู้จักพูดในสิ่งที่ไม่เคยพูดเช่น George W. Bush อ่าน“ In Da Club” โดย 50 Cent . มันเป็นจุดที่
ที่อื่นบน YouTube คุณจะได้ยินอดีตประธานาธิบดีมากมายรวมถึง โอบามาคลินตันและเรแกนแร็พ NWA . เพลงและเสียงพื้นหลังช่วยอำพรางความผิดพลาดของหุ่นยนต์ที่เห็นได้ชัด แต่ถึงแม้จะอยู่ในสถานะที่ไม่สมบูรณ์แบบนี้ก็ยังมีศักยภาพที่ชัดเจน
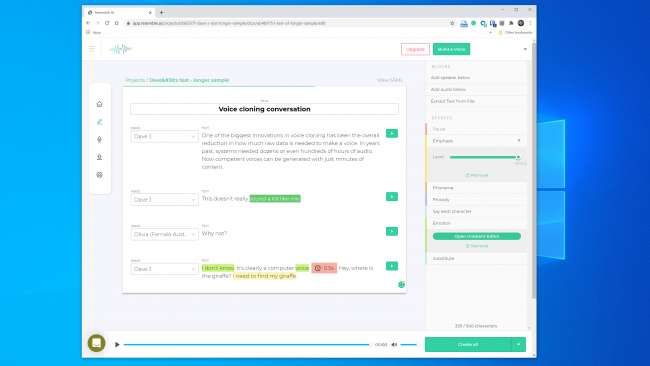
เราทดลองใช้เครื่องมือบน คล้ายกับ AI และ คำอธิบาย และสร้างโคลนเสียง Descript ใช้เอ็นจิ้นการโคลนเสียงที่เดิมเรียกว่า Lyrebird และน่าประทับใจเป็นพิเศษ เราตกใจในคุณภาพ การได้ยินเสียงของคุณเองพูดในสิ่งที่คุณรู้ว่าคุณไม่เคยพูดมานั้นทำให้รู้สึกไม่สบายใจ
คำพูดนั้นมีคุณภาพแน่นอน แต่ในการฟังแบบสบาย ๆ คนส่วนใหญ่จะไม่มีเหตุผลที่จะคิดว่ามันเป็นของปลอม

เรามีความหวังสูงขึ้นสำหรับ Resemble AI ช่วยให้คุณมีเครื่องมือในการสร้างการสนทนาที่มีหลายเสียงและปรับเปลี่ยนการแสดงออกอารมณ์และจังหวะของกล่องโต้ตอบ อย่างไรก็ตามเราไม่คิดว่ารูปแบบเสียงจะจับคุณสมบัติที่สำคัญของเสียงที่เราใช้ อันที่จริงก็ไม่น่าหลอกใคร
ตัวแทนของ Resemble AI บอกกับเราว่า“ คนส่วนใหญ่ประทับใจกับผลลัพธ์หากทำอย่างถูกต้อง” เราสร้างรูปแบบเสียงสองครั้งโดยให้ผลลัพธ์ที่คล้ายกัน เห็นได้ชัดว่าไม่ใช่เรื่องง่ายเสมอไปในการสร้างโคลนเสียงที่คุณสามารถใช้เพื่อดึงการปล้นดิจิทัลได้
ถึงกระนั้น Kundan Kumar ผู้ก่อตั้ง Lyrebird (ซึ่งปัจจุบันเป็นส่วนหนึ่งของ Descript) ก็รู้สึกว่าเราผ่านเกณฑ์นั้นไปแล้ว
“ มีเพียงไม่กี่กรณีเท่านั้นที่มีอยู่แล้ว” Kumar กล่าว “ ถ้าฉันใช้เสียงสังเคราะห์เพื่อเปลี่ยนคำพูดสักสองสามคำมันก็ดีอยู่แล้วที่คุณจะรู้ว่าอะไรเปลี่ยนแปลงไปได้ยาก”
เราสามารถสันนิษฐานได้ว่าเทคโนโลยีนี้จะดีขึ้นเมื่อเวลาผ่านไป ระบบจะต้องใช้เสียงน้อยลงในการสร้างโมเดลและโปรเซสเซอร์ที่เร็วขึ้นจะสามารถสร้างโมเดลได้แบบเรียลไทม์ AI ที่ฉลาดขึ้นจะเรียนรู้วิธีเพิ่มจังหวะการพูดเหมือนมนุษย์ที่น่าเชื่อและเน้นการพูดโดยไม่ต้องมีตัวอย่างให้ใช้
ซึ่งหมายความว่าเราอาจกำลังคืบคลานเข้าใกล้ความพร้อมของการโคลนเสียงที่ง่ายดายอย่างกว้างขวาง
จริยธรรมของ Pandora’s Box
บริษัท ส่วนใหญ่ที่ทำงานในพื้นที่นี้ดูเหมือนพร้อมที่จะจัดการกับเทคโนโลยีด้วยวิธีที่ปลอดภัยและมีความรับผิดชอบ ตัวอย่างเช่นคล้ายกับ AI มี ส่วน "จริยธรรม" ทั้งหมดบนเว็บไซต์ และข้อความที่ตัดตอนมาต่อไปนี้เป็นกำลังใจ:
“ เราทำงานร่วมกับ บริษัท ต่างๆผ่านกระบวนการที่เข้มงวดเพื่อให้แน่ใจว่าเสียงที่พวกเขากำลังโคลนนิ่งนั้นสามารถใช้งานได้โดยพวกเขาและได้รับความยินยอมที่เหมาะสมกับนักพากย์”
ในทำนองเดียวกัน Kumar กล่าวว่า Lyrebird กังวลเกี่ยวกับการใช้ในทางที่ผิดตั้งแต่เริ่มต้น ด้วยเหตุนี้ในฐานะที่เป็นส่วนหนึ่งของ Descript จึงอนุญาตให้ผู้คนลอกเลียนเสียงของตนเองได้เท่านั้น ในความเป็นจริงทั้ง Resemble และ Descript ต้องการให้ผู้คนบันทึกตัวอย่างของตนเพื่อป้องกันการโคลนเสียงที่ไม่เป็นไปตามความรู้สึก
เป็นเรื่องน่ายินดีที่ผู้เล่นการค้ารายใหญ่ได้กำหนดหลักเกณฑ์ด้านจริยธรรมบางประการ อย่างไรก็ตามสิ่งสำคัญคือต้องจำไว้ว่า บริษัท เหล่านี้ไม่ใช่ผู้เฝ้าประตูเทคโนโลยีนี้ มีเครื่องมือโอเพนซอร์สจำนวนมากอยู่แล้วซึ่งไม่มีกฎ ตามที่ Henry Ajder หัวหน้าหน่วยข่าวกรองภัยคุกคามที่ Deeptrace คุณไม่จำเป็นต้องมีความรู้ในการเขียนโค้ดขั้นสูงเพื่อนำไปใช้ในทางที่ผิด
“ ความก้าวหน้ามากมายในอวกาศเกิดขึ้นจากการทำงานร่วมกันในสถานที่ต่างๆเช่น GitHub โดยใช้การใช้งานโอเพ่นซอร์สของเอกสารทางวิชาการที่เผยแพร่ก่อนหน้านี้” Ajder กล่าว “ ทุกคนที่มีความเชี่ยวชาญในการเขียนโค้ดสามารถใช้ได้”
ผู้เชี่ยวชาญด้านความปลอดภัยเคยเห็นทั้งหมดนี้มาก่อน
อาชญากรพยายามขโมยเงินทางโทรศัพท์มานานก่อนที่จะสามารถโคลนเสียงได้และผู้เชี่ยวชาญด้านความปลอดภัยได้โทรหาและป้องกันมาโดยตลอด บริษัท รักษาความปลอดภัย พินดรอป พยายามที่จะหยุดการฉ้อโกงของธนาคารโดยการตรวจสอบว่าผู้โทรเป็นคนที่เขาอ้างว่ามาจากเสียงหรือไม่ ในปี 2019 เพียงอย่างเดียว Pindrop อ้างว่าได้วิเคราะห์การโต้ตอบด้วยเสียง 1.2 พันล้านครั้งและป้องกันการฉ้อโกงประมาณ 470 ล้านดอลลาร์
ก่อนที่จะทำการโคลนเสียงนักต้มตุ๋นได้ลองใช้เทคนิคอื่น ๆ อีกมากมาย วิธีที่ง่ายที่สุดคือโทรจากที่อื่นพร้อมข้อมูลส่วนตัวเกี่ยวกับเครื่องหมาย
“ ลายเซ็นอะคูสติกของเราช่วยให้เราสามารถระบุได้ว่ามีการโทรมาจากโทรศัพท์ Skype ในไนจีเรียจริงเนื่องจากลักษณะของเสียง” Vijay Balasubramaniyan ซีอีโอของ Pindrop กล่าว “ จากนั้นเราสามารถเปรียบเทียบได้ว่าการรู้ว่าลูกค้าใช้โทรศัพท์ AT&T ในแอตแลนตา”
อาชญากรบางคนยังเลิกใช้เสียงพื้นหลังเพื่อกำจัดพนักงานธนาคาร
“ มีนักต้มตุ๋นที่เราเรียกว่า Chicken Man ซึ่งมักจะเจื้อยแจ้วอยู่เบื้องหลัง” บาลาซูบรามานิยันกล่าว “ และมีผู้หญิงคนหนึ่งที่ใช้ทารกร้องไห้อยู่เบื้องหลังเพื่อโน้มน้าวตัวแทนคอลเซ็นเตอร์ว่า ‘เดี๋ยวก่อนฉันกำลังผ่านช่วงเวลาที่ยากลำบาก’ เพื่อขอความเห็นใจ”
จากนั้นก็มีอาชญากรชายที่ติดตามบัญชีธนาคารของผู้หญิง
“ พวกเขาใช้เทคโนโลยีเพื่อเพิ่มความถี่ในการเปล่งเสียงเพื่อให้ฟังดูเป็นผู้หญิงมากขึ้น” บาลาซูบรามานิยันอธิบาย สิ่งเหล่านี้สามารถประสบความสำเร็จได้ แต่“ ในบางครั้งซอฟต์แวร์ก็ทำงานผิดพลาดและฟังดูเหมือน Alvin และ Chipmunks”
แน่นอนว่าการโคลนเสียงเป็นเพียงพัฒนาการล่าสุดในสงครามที่ทวีความรุนแรงขึ้นเรื่อย ๆ บริษัท รักษาความปลอดภัยได้จับผู้ฉ้อโกงโดยใช้เสียงสังเคราะห์ในการโจมตีด้วยการทำหอก
“ ด้วยเป้าหมายที่ถูกต้องการจ่ายเงินอาจมหาศาล” Balasubramaniyan กล่าว “ ดังนั้นจึงเป็นเรื่องที่สมเหตุสมผลที่จะอุทิศเวลาเพื่อสร้างเสียงสังเคราะห์ของบุคคลที่เหมาะสม”
ทุกคนสามารถบอกได้ว่าเสียงปลอมหรือไม่?

เมื่อต้องรู้ว่าเสียงถูกแกล้งมีทั้งข่าวดีและข่าวร้าย ที่แย่ก็คือการโคลนเสียงเริ่มดีขึ้นทุกวัน ระบบการเรียนรู้เชิงลึกจะฉลาดขึ้นและสร้างเสียงที่แท้จริงมากขึ้นซึ่งต้องใช้เสียงน้อยลงในการสร้าง
อย่างที่บอกได้จากคลิปของ ประธานาธิบดีโอบามาบอกให้ MC Ren เข้ารับตำแหน่ง นอกจากนี้เรายังมาถึงจุดที่รูปแบบเสียงที่มีความเที่ยงตรงสูงซึ่งสร้างขึ้นอย่างพิถีพิถันสามารถให้เสียงที่น่าเชื่อต่อหูของมนุษย์ได้
ยิ่งคลิปเสียงมีความยาวมากเท่าไหร่คุณก็ยิ่งมีแนวโน้มที่จะสังเกตเห็นสิ่งผิดปกติมากขึ้นเท่านั้น อย่างไรก็ตามสำหรับคลิปสั้น ๆ คุณอาจไม่สังเกตเห็นว่ามันสังเคราะห์โดยเฉพาะอย่างยิ่งหากคุณไม่มีเหตุผลที่จะตั้งคำถามถึงความถูกต้อง
ยิ่งคุณภาพเสียงชัดเจนมากเท่าไหร่ก็ยิ่งสังเกตเห็นสัญญาณของ Deepfake ของเสียงได้ง่ายขึ้นเท่านั้น หากมีคนพูดใส่ไมโครโฟนคุณภาพระดับสตูดิโอโดยตรงคุณจะสามารถฟังได้อย่างใกล้ชิด แต่การบันทึกการโทรที่มีคุณภาพต่ำหรือการสนทนาที่ถ่ายด้วยอุปกรณ์พกพาในที่จอดรถที่มีเสียงดังจะประเมินได้ยากกว่ามาก
ข่าวดีก็คือแม้ว่ามนุษย์จะมีปัญหาในการแยกของจริงออกจากของปลอม แต่คอมพิวเตอร์ก็ไม่มีข้อ จำกัด เหมือนกัน โชคดีที่มีเครื่องมือตรวจสอบเสียงอยู่แล้ว Pindrop มีระบบการเรียนรู้เชิงลึกซึ่งกันและกัน โดยใช้ทั้งสองอย่างเพื่อค้นหาว่าตัวอย่างเสียงคือบุคคลที่ควรจะเป็นหรือไม่ อย่างไรก็ตามยังตรวจสอบด้วยว่ามนุษย์สามารถสร้างเสียงทั้งหมดในตัวอย่างได้หรือไม่
ขึ้นอยู่กับคุณภาพของเสียงทุก ๆ วินาทีของการพูดจะมีตัวอย่างข้อมูลระหว่าง 8,000-50,000 ตัวอย่างที่วิเคราะห์ได้
“ สิ่งที่เรามักมองหาคือข้อ จำกัด ในการพูดเนื่องจากวิวัฒนาการของมนุษย์” Balasubramaniyan อธิบาย
ตัวอย่างเช่นเสียงที่เปล่งออกสองเสียงจะมีการแยกเสียงออกจากกันน้อยที่สุด เนื่องจากเป็นไปไม่ได้ที่จะพูดเร็วกว่านี้เนื่องจากความเร็วที่กล้ามเนื้อในปากและสายเสียงของคุณสามารถกำหนดค่าตัวเองใหม่ได้
“ เมื่อเราดูเสียงสังเคราะห์” Balasubramaniyan กล่าว“ บางครั้งเราก็เห็นสิ่งต่าง ๆ และพูดว่า 'สิ่งนี้ไม่เคยถูกสร้างขึ้นโดยมนุษย์เพราะคนเพียงคนเดียวที่สามารถสร้างสิ่งนี้ได้จำเป็นต้องมีคอยาวเจ็ดฟุต ”
นอกจากนี้ยังมีคลาสของเสียงที่เรียกว่า "fricatives" พวกมันก่อตัวขึ้นเมื่ออากาศไหลผ่านช่องคอของคุณเมื่อคุณออกเสียงตัวอักษรเช่น f, s, v และ z Fricatives เป็นเรื่องยากโดยเฉพาะอย่างยิ่งสำหรับระบบ deep-learning ที่จะเชี่ยวชาญเนื่องจากซอฟต์แวร์มีปัญหาในการแยกความแตกต่างจากเสียง
ดังนั้นอย่างน้อยในตอนนี้ซอฟต์แวร์โคลนเสียงจึงสะดุดเพราะมนุษย์เป็นถุงเนื้อที่ไหลผ่านรูในร่างกายเพื่อพูดคุย
“ ฉันล้อเล่นอยู่เสมอว่าของปลอมนั้นน่าสะอิดสะเอียนมาก” บาลาซูบรามานิยันกล่าว เขาอธิบายว่าอัลกอริทึมยากมากที่จะแยกความแตกต่างของคำที่ลงท้ายจากเสียงพื้นหลังในการบันทึก สิ่งนี้ส่งผลให้มีแบบจำลองเสียงจำนวนมากที่มีการพูดที่หลุดโลกมากกว่าที่มนุษย์ทำ
“ เมื่ออัลกอริทึมเห็นสิ่งนี้เกิดขึ้นมากมาย” Balasubramaniyan กล่าว“ ในทางสถิติมันจะมั่นใจมากขึ้นว่าเป็นเสียงที่สร้างขึ้นเมื่อเทียบกับมนุษย์”
Resemble AI ยังจัดการปัญหาการตรวจจับด้วย Resemblyzer ซึ่งเป็นเครื่องมือการเรียนรู้เชิงลึกแบบโอเพนซอร์ส พร้อมใช้งานบน GitHub . สามารถตรวจจับเสียงปลอมและทำการตรวจสอบลำโพง
ต้องใช้ความระมัดระวัง
เป็นเรื่องยากที่จะคาดเดาว่าอนาคตจะเป็นอย่างไร แต่เทคโนโลยีนี้จะดีขึ้นอย่างแน่นอน นอกจากนี้ใคร ๆ ก็อาจตกเป็นเหยื่อได้ไม่ใช่แค่บุคคลที่มีชื่อเสียงเท่านั้นเช่นเจ้าหน้าที่ที่มาจากการเลือกตั้งหรือซีอีโอของธนาคาร
“ ฉันคิดว่าเรากำลังใกล้จะเกิดการละเมิดเสียงครั้งแรกที่เสียงของผู้คนถูกขโมยไป” Balasubramaniyan ทำนาย
แม้ว่าในขณะนี้ความเสี่ยงในโลกแห่งความเป็นจริงจากการปลอมแปลงเสียงอยู่ในระดับต่ำ มีเครื่องมือที่ดูเหมือนจะตรวจจับวิดีโอสังเคราะห์ได้ดีอยู่แล้ว
นอกจากนี้คนส่วนใหญ่ไม่เสี่ยงต่อการถูกโจมตี จากข้อมูลของ Ajder ผู้เล่นหลักในเชิงพาณิชย์“ กำลังดำเนินการแก้ปัญหาตามความต้องการของลูกค้าเฉพาะรายและส่วนใหญ่มีแนวทางด้านจริยธรรมที่ดีพอสมควรว่าพวกเขาจะทำกับใครและไม่ทำงานด้วย”
แม้ว่าภัยคุกคามที่แท้จริงรออยู่ข้างหน้าในขณะที่ Ajder อธิบายต่อไป:
“ Pandora’s Box จะเป็นผู้คนที่รวบรวมการนำเทคโนโลยีโอเพนซอร์สมาใช้ร่วมกันในแอปหรือบริการที่เข้าถึงได้ง่ายและเป็นมิตรกับผู้ใช้มากขึ้นซึ่งไม่มีชั้นจริยธรรมในการตรวจสอบข้อเท็จจริงที่โซลูชันเชิงพาณิชย์ทำอยู่ในขณะนี้”
ซึ่งอาจเป็นสิ่งที่หลีกเลี่ยงไม่ได้ แต่ บริษัท รักษาความปลอดภัยได้นำการตรวจจับเสียงปลอมมาใส่ในชุดเครื่องมือของตนแล้ว ถึงกระนั้นการอยู่อย่างปลอดภัยต้องมีความระมัดระวัง
“ เราได้ดำเนินการในพื้นที่ความปลอดภัยอื่น ๆ แล้ว” Ajder กล่าว “ องค์กรจำนวนมากใช้เวลาส่วนใหญ่ในการพยายามทำความเข้าใจว่าอะไรคือช่องโหว่ของ Zero-day ข้างหน้าเป็นต้น เสียงสังเคราะห์เป็นเพียงพรมแดนถัดไป”
ที่เกี่ยวข้อง: Deepfake คืออะไรและฉันควรกังวลอะไร?




")

