
Głębokie podróbki wideo oznaczają, że nie możesz ufać wszystkiemu, co widzisz. Teraz głębokie podróbki dźwięku mogą oznaczać, że nie możesz już ufać swoim uszom. Czy to naprawdę prezydent wypowiedział wojnę Kanadzie? Czy to naprawdę twój tata dzwoni do telefonu i pyta o hasło e-mail?
Dodaj kolejny egzystencjalny niepokój do listy, w jaki sposób nasza własna pycha może nas nieuchronnie zniszczyć. W erze Reagana jedynym rzeczywistym ryzykiem technologicznym było zagrożenie bronią nuklearną, chemiczną i biologiczną.
W kolejnych latach mieliśmy okazję obsesji na punkcie szarej mazi nanotechnologii i globalnych pandemii. Teraz mamy głębokie podróbki - ludzie tracą kontrolę nad swoim podobieństwem lub głosem.
Co to jest Deepfake audio?
Większość z nas widziała wideo deepfake , w których algorytmy uczenia głębokiego zastępują jedną osobę podobnym do kogoś innego. Najlepsze są niepokojąco realistyczne, a teraz kolej na dźwięk. Głębokie fałszowanie dźwięku występuje wtedy, gdy „sklonowany” głos, który jest potencjalnie nie do odróżnienia od głosu prawdziwej osoby, jest używany do tworzenia syntetycznego dźwięku.
„To jest jak głos w Photoshopie” - powiedział Zohaib Ahmed, dyrektor generalny Przypominają AI , o technologii klonowania głosu w jego firmie.
Jednak złe prace w Photoshopie można łatwo obalić. Firma zajmująca się bezpieczeństwem, z którą rozmawialiśmy, powiedziała, że ludzie zwykle tylko zgadują, czy głębokie podróbki audio są prawdziwe, czy fałszywe z około 57-procentową dokładnością - nie lepiej niż rzut monetą.
Ponadto, ponieważ tak wiele nagrań głosowych to rozmowy telefoniczne niskiej jakości (lub nagrane w hałaśliwych miejscach), głębokie podróbki dźwięku mogą być jeszcze bardziej nie do odróżnienia. Im gorsza jakość dźwięku, tym trudniej jest wychwycić te charakterystyczne oznaki, że głos nie jest prawdziwy.
Ale dlaczego ktoś miałby w ogóle potrzebować Photoshopa do głosów?
Przekonująca sprawa dla dźwięku syntetycznego
W rzeczywistości istnieje ogromne zapotrzebowanie na dźwięk syntetyczny. Według Ahmeda „zwrot z inwestycji jest bardzo natychmiastowy”.
Jest to szczególnie prawdziwe w przypadku gier. W przeszłości mowa była jedynym elementem gry, którego nie można było stworzyć na żądanie. Nawet w interaktywnych tytułach ze scenami o jakości kinowej renderowanymi w czasie rzeczywistym, interakcje słowne z postaciami nie grającymi są zawsze zasadniczo statyczne.
Teraz jednak technologia dogoniła. Studia mają potencjał, aby sklonować głos aktora i używać silników zamiany tekstu na mowę, aby postacie mogły powiedzieć wszystko w czasie rzeczywistym.
Istnieją również bardziej tradycyjne zastosowania w reklamie, technice i obsłudze klienta. Tutaj ważny jest głos, który brzmi autentycznie po ludzku i reaguje osobiście i kontekstowo bez udziału człowieka.
Firmy klonujące głos są również podekscytowane zastosowaniami medycznymi. Oczywiście, zastępowanie głosu nie jest niczym nowym w medycynie - Stephen Hawking słynął z użycia syntetyzowanego głosu robota po tym, jak stracił swój własny w 1985 roku. Jednak nowoczesne klonowanie głosu obiecuje coś jeszcze lepszego.
W 2008 roku firma zajmująca się głosem syntetycznym, CereProc , powiedział nieżyjący już krytyk filmowy, Roger Ebert, jego głos powrócił po tym, jak odebrał mu rak. CereProc opublikował stronę internetową, która umożliwiała ludziom wpisywanie wiadomości, które były następnie wypowiadane głosem byłego prezydenta George'a Busha.
„Ebert zobaczył to i pomyślał:„ cóż, gdyby mogli skopiować głos Busha, to powinni móc skopiować mój ”- powiedział Matthew Aylett, dyrektor naukowy CereProc. Ebert poprosił następnie firmę o stworzenie zastępczego głosu, co zrobili, przetwarzając dużą bibliotekę nagrań głosowych.
„To był jeden z pierwszych przypadków, kiedy ktokolwiek to zrobił i był to prawdziwy sukces” - powiedział Aylett.
W ostatnich latach wiele firm (w tym CereProc) współpracowało z Stowarzyszenie ALS na Projekt Revoice zapewnienie syntetycznych głosów tym, którzy cierpią na ALS.

Jak działa dźwięk syntetyczny
Klonowanie głosu ma teraz chwilę, a mnóstwo firm opracowuje narzędzia. Przypominają AI i Opis mieć dema online, które każdy może wypróbować za darmo. Po prostu nagrywasz frazy, które pojawiają się na ekranie, a po kilku minutach tworzony jest model Twojego głosu.
Możesz podziękować AI - w szczególności algorytmy głębokiego uczenia - aby móc dopasować nagraną mowę do tekstu w celu zrozumienia składowych fonemów, z których składa się Twój głos. Następnie wykorzystuje powstałe w ten sposób bloki językowe do przybliżenia słów, których nie słyszał, jak mówisz.
Podstawowa technologia istnieje już od jakiegoś czasu, ale jak zauważył Aylett, wymagała pomocy.
„Kopiowanie głosu było trochę jak robienie ciasta” - powiedział. „Było to trochę trudne i istniało wiele sposobów, w jakie trzeba było go ręcznie poprawić, aby działał”.
Deweloperzy potrzebowali ogromnych ilości nagranych danych głosowych, aby uzyskać zadowalające wyniki. Potem, kilka lat temu, śluzy się otworzyły. Badania w dziedzinie widzenia komputerowego okazały się krytyczne. Naukowcy opracowali generatywne sieci przeciwstawne (GAN), które po raz pierwszy mogą ekstrapolować i prognozować na podstawie istniejących danych.
„Zamiast komputera, który zobaczy zdjęcie konia i powie„ to jest koń ”, mój model może teraz zamienić konia w zebrę” - powiedział Aylett. „Tak więc eksplozja syntezy mowy jest teraz wynikiem pracy akademickiej związanej z widzeniem komputerowym”.
Jedną z największych innowacji w klonowaniu głosu jest ogólne zmniejszenie ilości surowych danych potrzebnych do stworzenia głosu. W przeszłości systemy wymagały dziesiątek, a nawet setek godzin dźwięku. Teraz jednak kompetentne głosy można wygenerować z zaledwie kilku minut treści.
ZWIĄZANE Z: Problem ze sztuczną inteligencją: maszyny uczą się rzeczy, ale ich nie rozumieją
Egzystencjalny strach przed brakiem zaufania do niczego
Ta technologia, wraz z energią jądrową, nanotechnologią, drukowaniem 3D i CRISPR, jest jednocześnie ekscytująca i przerażająca. W końcu były już przypadki w wiadomościach o ludziach oszukiwanych przez klony głosowe. W 2019 roku firma z Wielkiej Brytanii twierdziła, że tak oszukany przez deepfake audio telefon w celu przelewania pieniędzy przestępcom.
Nie musisz też daleko szukać, aby znaleźć zaskakująco przekonujące podróbki audio. Kanał Youtube Synteza wokalna przedstawia znanych ludzi, którzy mówią rzeczy, których nigdy nie powiedzieli, na przykład George W. Bush reading “In Da Club” by 50 Cent . Jest na miejscu.
Gdzie indziej na YouTube można usłyszeć stado byłych prezydentów, w tym Obama, Clinton i Reagan, rapują NWA . Muzyka i dźwięki w tle pomagają ukryć niektóre oczywiste usterki robotów, ale nawet w tym niedoskonałym stanie potencjał jest oczywisty.
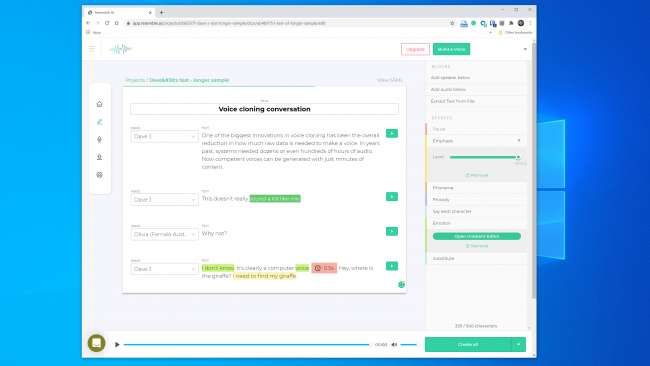
Eksperymentowaliśmy z włączonymi narzędziami Przypominają AI i Opis i stworzył klon głosu. Descript używa silnika klonowania głosu, który pierwotnie nosił nazwę Lyrebird i był szczególnie imponujący. Byliśmy zszokowani jakością. Słyszenie własnego głosu mówiącego rzeczy, o których wiesz, że nigdy nie powiedziałeś, jest denerwujące.
Przemówienie ma zdecydowanie robotyczny charakter, ale przy swobodnym słuchaniu większość ludzi nie miałaby powodu sądzić, że to fałszerstwo.

Jeszcze większe nadzieje wiązaliśmy z Resemble AI. Zapewnia narzędzia do prowadzenia rozmowy z wieloma głosami i różnicowania ekspresji, emocji i tempa dialogu. Jednak nie sądziliśmy, że model głosu uchwycił podstawowe cechy głosu, którego użyliśmy. W rzeczywistości nikogo nie oszukał.
Przedstawiciel Resemble AI powiedział nam, że „większość ludzi jest zachwycona wynikami, jeśli robią to poprawnie”. Dwa razy zbudowaliśmy model głosu z podobnymi wynikami. Więc najwyraźniej nie zawsze jest łatwo stworzyć klon głosu, którego można użyć do przeprowadzenia cyfrowego napadu.
Mimo to Lyrebird (który jest teraz częścią Descript), Kundan Kumar, uważa, że przekroczyliśmy już ten próg.
„W przypadku niewielkiego odsetka przypadków już tam jest” - powiedział Kumar. „Jeśli użyję syntetycznego dźwięku do zmiany kilku słów w przemówieniu, jest już tak dobrze, że trudno będzie Ci dowiedzieć się, co się zmieniło”.
Możemy również założyć, że ta technologia będzie się poprawiać z czasem. Systemy będą potrzebowały mniej dźwięku do stworzenia modelu, a szybsze procesory będą mogły zbudować model w czasie rzeczywistym. Mądrzejsza sztuczna inteligencja nauczy się, jak dodać bardziej przekonującą ludzką kadencję i nacisk na mowę bez posiadania przykładu do pracy.
Co oznacza, że możemy zbliżać się do powszechnej dostępności łatwego klonowania głosu.
Etyka puszki Pandory
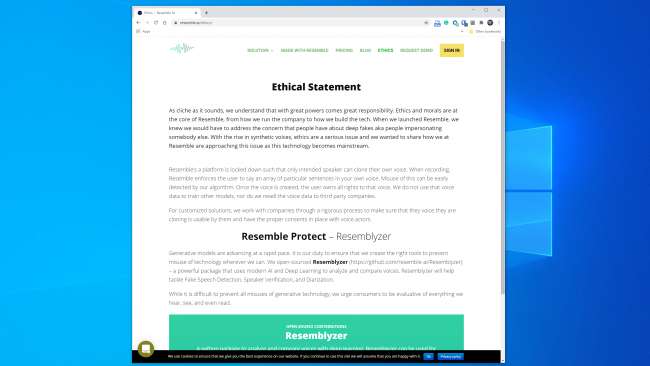
Większość firm działających w tej przestrzeni wydaje się być gotowa do obsługi technologii w bezpieczny i odpowiedzialny sposób. Przypomnijmy na przykład sztuczną inteligencję całą sekcję „Etyka” na swojej stronie internetowej , a poniższy fragment jest zachęcający:
„Współpracujemy z firmami w ramach rygorystycznego procesu, aby upewnić się, że głos, który klonują, jest dla nich użyteczny i że posiadamy odpowiednie zgody dla aktorów głosowych.”
Podobnie Kumar powiedział, że Lyrebird od początku był zaniepokojony niewłaściwym użyciem. Dlatego teraz, jako część Descript, pozwala on tylko klonować własny głos. W rzeczywistości zarówno Resemble, jak i Descript wymagają, aby ludzie nagrywali swoje próbki na żywo, aby zapobiec bezsensownemu klonowaniu głosu.
To pocieszające, że główni gracze komercyjni narzucili pewne zasady etyczne. Należy jednak pamiętać, że te firmy nie są strażnikami tej technologii. Istnieje wiele narzędzi typu open source, które już istnieją na wolności, dla których nie ma żadnych reguł. Według Henry Ajder, szef wywiadu zagrożeń w Deeptrace , nie potrzebujesz też zaawansowanej wiedzy o kodowaniu, aby go niewłaściwie używać.
„Duży postęp w kosmosie dokonał się dzięki współpracy w miejscach takich jak GitHub, z wykorzystaniem implementacji open source wcześniej opublikowanych artykułów naukowych” - powiedział Ajder. „Może być używany przez każdego, kto ma umiarkowaną biegłość w kodowaniu”.
Profesjonaliści w dziedzinie bezpieczeństwa widzieli to już wcześniej
Przestępcy próbowali ukraść pieniądze przez telefon na długo przed tym, zanim możliwe było klonowanie głosu, a eksperci ds. Bezpieczeństwa zawsze byli pod telefonem, aby wykryć i zapobiec temu. Firma ochroniarska Pindrop próbuje powstrzymać oszustwa bankowe, sprawdzając, czy dzwoniący jest tym, za kogo się podaje. Tylko w 2019 roku Pindrop twierdzi, że przeanalizował 1,2 miliarda interakcji głosowych i zapobiegł około 470 milionom dolarów próbom oszustwa.
Przed klonowaniem głosu oszuści wypróbowali wiele innych technik. Najprostszym było po prostu zadzwonić z innego miejsca z osobistymi informacjami o znaku.
„Nasza sygnatura akustyczna pozwala nam określić, że połączenie rzeczywiście pochodzi z telefonu Skype w Nigerii ze względu na charakterystykę dźwięku” - powiedział dyrektor generalny Pindrop, Vijay Balasubramaniyan. „Następnie możemy to porównać, wiedząc, że klient korzysta z telefonu AT&T w Atlancie”.
Niektórzy przestępcy zrobili również kariery, używając dźwięków w tle, aby zmylić przedstawicieli banków.
„Jest oszust, którego nazywaliśmy Kurczakiem, który zawsze miał koguty w tle” - powiedział Balasubramaniyan. „I jest jedna pani, która wykorzystała płacz dziecka w tle, aby zasadniczo przekonać pracowników call center, że„ hej, przechodzę przez trudny okres ”, aby uzyskać współczucie”.
Są też przestępcy płci męskiej, którzy szukają kont bankowych kobiet.
„Używają technologii, aby zwiększyć częstotliwość swojego głosu, aby brzmiał bardziej kobieco” - wyjaśnił Balasubramaniyan. Mogą się one udać, ale „czasami oprogramowanie się psuje i brzmią jak Alvin i wiewiórki”.
Oczywiście klonowanie głosu to tylko najnowsze osiągnięcie w tej nieustannie eskalującej wojnie. Firmy ochroniarskie już przyłapały oszustów korzystających z syntetycznego dźwięku w co najmniej jednym ataku łowiectwa podwodnego.
„Przy odpowiednim celu wypłata może być ogromna” - powiedział Balasubramaniyan. „Dlatego warto poświęcić czas na stworzenie zsyntetyzowanego głosu właściwej osoby”.
Czy ktoś może stwierdzić, czy głos jest fałszywy?

Jeśli chodzi o rozpoznanie, czy głos został sfałszowany, są zarówno dobre, jak i złe wieści. Złe jest to, że klony głosu są coraz lepsze każdego dnia. Systemy uczenia głębokiego stają się inteligentniejsze i generują bardziej autentyczne głosy, których tworzenie wymaga mniejszego dźwięku.
Jak widać z tego klipu Prezydent Obama mówi MC Renowi, aby zajął stanowisko Doszliśmy już do punktu, w którym wierny, starannie skonstruowany model głosu może brzmieć całkiem przekonująco dla ludzkiego ucha.
Im dłuższy klip dźwiękowy, tym większe prawdopodobieństwo, że zauważysz, że coś jest nie tak. Jednak w przypadku krótszych klipów możesz nie zauważyć, że jest on syntetyczny - zwłaszcza jeśli nie masz powodu kwestionować jego legalności.
Im wyraźniejsza jakość dźwięku, tym łatwiej jest zauważyć oznaki głębokiego fałszowania dźwięku. Jeśli ktoś mówi bezpośrednio do mikrofonu o jakości studyjnej, możesz uważnie słuchać. Jednak słaba jakość nagrania rozmowy telefonicznej lub rozmowy zarejestrowanej na urządzeniu przenośnym w hałaśliwym garażu będzie znacznie trudniejsza do oceny.
Dobra wiadomość jest taka, że nawet jeśli ludzie mają problem z oddzieleniem prawdziwego od fałszywego, komputery nie mają takich samych ograniczeń. Na szczęście narzędzia do weryfikacji głosowej już istnieją. Pindrop ma taki, który zestawia ze sobą systemy uczenia głębokiego. Używa obu, aby dowiedzieć się, czy próbka audio jest osobą, którą ma być. Jednak bada również, czy człowiek może nawet wydać wszystkie dźwięki w próbce.
W zależności od jakości dźwięku każda sekunda mowy zawiera od 8 000 do 50 000 próbek danych, które można przeanalizować.
„To, czego zwykle szukamy, to ograniczenia mowy spowodowane ewolucją człowieka” - wyjaśnił Balasubramaniyan.
Na przykład dwa dźwięki wokalne mają minimalną możliwą separację od siebie. Dzieje się tak, ponieważ nie jest fizycznie możliwe wypowiedzenie ich szybciej ze względu na szybkość, z jaką mięśnie ust i struny głosowe mogą się zrekonfigurować.
„Kiedy patrzymy na zsyntetyzowany dźwięk”, powiedział Balasubramaniyan, „czasami widzimy rzeczy i mówimy:„ to nigdy nie mogłoby zostać wygenerowane przez człowieka, ponieważ jedyna osoba, która mogłaby to wygenerować, musi mieć szyję o długości siedmiu stóp. ”
Istnieje również klasa dźwięków zwana „fricatives”. Powstają, gdy powietrze przechodzi przez wąski ucisk w gardle, gdy wymawiasz litery takie jak f, s, v i z. Fricatives są szczególnie trudne do opanowania przez systemy uczenia głębokiego, ponieważ oprogramowanie ma problemy z odróżnieniem ich od szumu.
Tak więc, przynajmniej na razie, oprogramowanie do klonowania głosu jest zaskoczone faktem, że ludzie są workami mięsa, które przepuszczają powietrze przez otwory w ich ciele, aby rozmawiać.
„Ciągle żartuję, że deepfake'i są bardzo jęczące” - powiedział Balasubramaniyan. Wyjaśnił, że algorytmom bardzo trudno jest odróżnić końce słów od szumu tła w nagraniu. Skutkuje to wieloma modelami głosu, w których mowa przerywa się bardziej niż ludzie.
„Kiedy algorytm widzi, że dzieje się to często” - powiedział Balasubramaniyan - „statystycznie rzecz biorąc, staje się bardziej pewny, że to dźwięk jest generowany, a nie ludzki”.
Resemble AI rozwiązuje również problem z wykrywaniem bezpośrednio przy użyciu Resemblyzer, narzędzia do głębokiego uczenia się typu open source dostępne na GitHub . Może wykrywać fałszywe głosy i przeprowadzać weryfikację mówcy.
To wymaga czujności
Zawsze trudno zgadnąć, co przyniesie przyszłość, ale ta technologia prawie na pewno będzie tylko lepsza. Ponadto ofiarą może stać się każdy - nie tylko znane osoby, takie jak wybrani urzędnicy lub prezesi banków.
„Myślę, że jesteśmy u progu pierwszego naruszenia dźwięku, w wyniku którego głosy ludzi zostaną skradzione” - przewidział Balasubramaniyan.
W tej chwili jednak rzeczywiste ryzyko związane z głębokimi podróbkami dźwięku jest niskie. Istnieją już narzędzia, które wydają się całkiem nieźle radzić sobie z wykrywaniem wideo syntetycznego.
Ponadto większość ludzi nie jest zagrożona atakiem. Według Ajdera, główni gracze komercyjni „pracują nad rozwiązaniami dostosowanymi do konkretnych klientów, a większość z nich ma dość dobre wytyczne etyczne dotyczące tego, z kim współpracowaliby, a z kim nie”.
Prawdziwe zagrożenie jest jednak przed nami, jak wyjaśnił Ajder:
„Puszka Pandory to ludzie łączący implementacje technologii typu open source w coraz bardziej przyjazne dla użytkownika, dostępne aplikacje lub usługi, które nie mają takiej etycznej warstwy kontroli, jak obecnie dostępne rozwiązania komercyjne”.
Jest to prawdopodobnie nieuniknione, ale firmy zajmujące się bezpieczeństwem wprowadzają już fałszywe wykrywanie dźwięku do swoich zestawów narzędzi. Jednak pozostanie bezpiecznym wymaga czujności.
„Zrobiliśmy to w innych obszarach bezpieczeństwa” - powiedział Ajder. „Na przykład wiele organizacji spędza dużo czasu, próbując zrozumieć, jaka jest następna luka w zabezpieczeniach typu zero-day. Dźwięk syntetyczny to po prostu kolejna granica ”.
ZWIĄZANE Z: Co to jest Deepfake i czy powinienem się tym przejmować?
")






")