
Video deepfake berarti Anda tidak bisa mempercayai semua yang Anda lihat. Sekarang, audio deepfake mungkin berarti Anda tidak bisa lagi mempercayai telinga Anda. Benarkah itu presiden yang menyatakan perang terhadap Kanada? Apa itu benar-benar ayahmu di telepon yang menanyakan kata sandi emailnya?
Tambahkan kekhawatiran eksistensial lainnya ke daftar tentang bagaimana keangkuhan kita sendiri dapat menghancurkan kita secara tak terelakkan. Selama era Reagan, satu-satunya risiko teknologi yang nyata adalah ancaman perang nuklir, kimia, dan biologis.
Di tahun-tahun berikutnya, kami memiliki kesempatan untuk terobsesi dengan cairan abu-abu nanoteknologi dan pandemi global. Sekarang, kita memiliki kesalahan besar — orang kehilangan kendali atas rupa atau suara mereka.
Apa Itu Audio Deepfake?
Sebagian besar dari kita pernah melihat a video deepfake , di mana algoritme pembelajaran mendalam digunakan untuk menggantikan satu orang dengan kemiripan orang lain. Yang terbaik ternyata sangat realistis, dan sekarang giliran audio. Audio deepfake adalah saat suara "kloning" yang berpotensi tidak dapat dibedakan dari suara orang aslinya digunakan untuk menghasilkan audio sintetis.
“Ini seperti Photoshop untuk suara,” kata Zohaib Ahmed, CEO Mirip dengan AI , tentang teknologi penggandaan suara perusahaannya.
Namun, pekerjaan Photoshop yang buruk dengan mudah dibantah. Sebuah firma keamanan yang kami ajak bicara mengatakan bahwa orang biasanya hanya menebak apakah deepfake audio itu asli atau palsu dengan akurasi sekitar 57 persen — tidak lebih baik dari flip koin.
Selain itu, karena begitu banyak rekaman suara dari panggilan telepon berkualitas rendah (atau direkam di lokasi yang bising), audio deepfake dapat dibuat lebih tidak dapat dibedakan. Semakin buruk kualitas suaranya, semakin sulit untuk menangkap tanda-tanda bahwa suara itu tidak nyata.
Tapi mengapa ada orang yang membutuhkan Photoshop untuk suara?
Kasus Menarik untuk Audio Sintetis
Sebenarnya ada permintaan yang sangat besar untuk audio sintetis. Menurut Ahmed, "ROI sangat cepat."
Ini terutama benar dalam hal bermain game. Di masa lalu, ucapan adalah salah satu komponen dalam game yang tidak mungkin dibuat sesuai permintaan. Bahkan dalam judul interaktif dengan adegan berkualitas bioskop yang ditampilkan dalam waktu nyata, interaksi verbal dengan karakter yang tidak bermain pada dasarnya selalu statis.
Sekarang, teknologi telah menyusul. Studio memiliki potensi untuk mengkloning suara aktor dan menggunakan mesin text-to-speech sehingga karakter dapat mengatakan apa pun secara real time.
Ada juga penggunaan yang lebih tradisional dalam periklanan, serta dukungan teknologi dan pelanggan. Di sini, suara yang terdengar seperti manusia secara otentik dan merespons secara pribadi dan kontekstual tanpa masukan manusia adalah yang terpenting.
Perusahaan kloning suara juga senang dengan aplikasi medis. Tentu saja, penggantian suara bukanlah hal baru dalam dunia kedokteran — Stephen Hawking terkenal menggunakan suara sintesis robot setelah kehilangan suara miliknya pada tahun 1985. Namun, kloning suara modern menjanjikan sesuatu yang lebih baik.
Pada tahun 2008, perusahaan suara sintetis, CereProc , memberikan kritikus film terlambat, Roger Ebert, suaranya kembali setelah kanker menghilangkannya. CereProc telah menerbitkan halaman web yang memungkinkan orang mengetik pesan yang kemudian akan diucapkan dengan suara mantan Presiden George Bush.
“Ebert melihatnya dan berpikir, 'baiklah, jika mereka bisa meniru suara Bush, mereka pasti bisa meniru suara saya,'” kata Matthew Aylett, kepala petugas ilmiah CereProc. Ebert kemudian meminta perusahaan untuk membuat suara pengganti, yang mereka lakukan dengan memproses perpustakaan rekaman suara yang besar.
“Itu adalah salah satu kali pertama orang melakukan itu dan itu benar-benar sukses,” kata Aylett.
Dalam beberapa tahun terakhir, sejumlah perusahaan (termasuk CereProc) telah bekerja sama dengan Asosiasi ALS di Revoice Proyek untuk memberikan suara sintetis kepada mereka yang menderita ALS.

Cara Kerja Audio Sintetis
Kloning suara mengalami momen saat ini, dan banyak perusahaan sedang mengembangkan alat. Mirip dengan AI dan Deskripsi memiliki demo online yang dapat dicoba siapa pun secara gratis. Anda hanya merekam frasa yang muncul di layar dan, hanya dalam beberapa menit, model suara Anda dibuat.
Anda dapat berterima kasih kepada AI — khususnya, algoritma pembelajaran mendalam —Untuk dapat mencocokkan rekaman ucapan dengan teks untuk memahami fonem komponen yang membentuk suara Anda. Ia kemudian menggunakan blok penyusun linguistik yang dihasilkan untuk memperkirakan kata-kata yang belum Anda dengar.
Teknologi dasar telah ada untuk sementara waktu, tetapi seperti yang ditunjukkan Aylett, itu membutuhkan bantuan.
“Menyalin suara itu seperti membuat kue,” katanya. “Ini agak sulit dilakukan dan ada berbagai cara yang harus Anda lakukan untuk mengubahnya secara manual agar berfungsi.”
Pengembang membutuhkan data rekaman suara dalam jumlah besar untuk mendapatkan hasil yang lumayan. Kemudian, beberapa tahun lalu, pintu air dibuka. Penelitian di bidang computer vision terbukti sangat penting. Ilmuwan mengembangkan jaringan adversarial generatif (GAN), yang dapat, untuk pertama kalinya, mengekstrapolasi dan membuat prediksi berdasarkan data yang ada.
"Daripada komputer melihat gambar kuda dan mengatakan 'ini adalah kuda', model saya sekarang bisa membuat kuda menjadi zebra," kata Aylett. “Jadi, ledakan sintesis ucapan sekarang ini berkat kerja akademis dari computer vision.”
Salah satu inovasi terbesar dalam kloning suara adalah pengurangan secara keseluruhan berapa banyak data mentah yang dibutuhkan untuk membuat suara. Di masa lalu, sistem membutuhkan puluhan atau bahkan ratusan jam audio. Namun, sekarang, suara yang kompeten dapat dihasilkan hanya dari beberapa menit konten.
TERKAIT: Masalah Dengan AI: Mesin Mempelajari Berbagai Hal, Tetapi Tidak Dapat Memahaminya
Ketakutan Eksistensial karena Tidak Mempercayai Apa Pun
Teknologi ini, bersama dengan tenaga nuklir, nanoteknologi, pencetakan 3D, dan CRISPR, secara bersamaan menggetarkan dan menakutkan. Lagipula, sudah ada kasus dalam berita tentang orang-orang yang ditipu oleh klon suara. Pada 2019, sebuah perusahaan di Inggris mengklaim itu diakali oleh deepfake audio panggilan telepon untuk mentransfer uang ke penjahat.
Anda juga tidak perlu jauh-jauh untuk menemukan audio palsu yang sangat meyakinkan. Saluran Youtube Sintesis Vokal menampilkan orang-orang terkenal yang mengatakan hal-hal yang tidak pernah mereka katakan, suka George W. Bush membaca "In Da Club" oleh 50 Cent . Tepat sekali.
Di tempat lain di YouTube, Anda dapat mendengar sekawanan mantan Presiden, termasuk Obama, Clinton, dan Reagan, nge-rap NWA . Musik dan suara latar membantu menyamarkan beberapa kesalahan robotik yang jelas, tetapi bahkan dalam keadaan tidak sempurna ini, potensinya jelas.
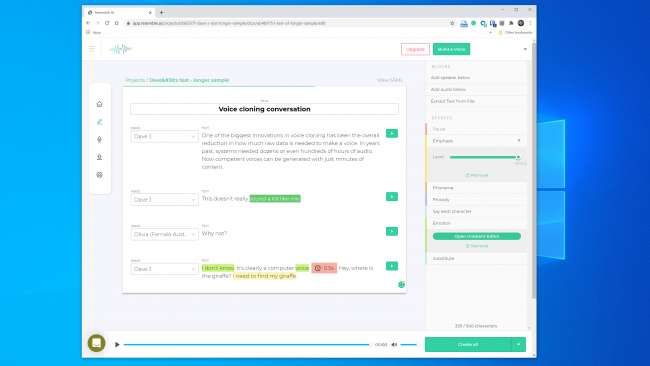
Kami bereksperimen dengan alat di Mirip dengan AI dan Deskripsi dan membuat klon suara. Deskripsi menggunakan mesin kloning suara yang awalnya disebut Lyrebird dan sangat mengesankan. Kami terkejut dengan kualitasnya. Mengerikan sekali mendengar suara Anda sendiri mengatakan hal-hal yang Anda tahu tidak pernah Anda ucapkan.
Jelas ada kualitas robotik pada pidato tersebut, tetapi jika didengarkan secara santai, kebanyakan orang tidak akan memiliki alasan untuk menganggapnya palsu.

Kami memiliki harapan yang lebih tinggi untuk Menyerupai AI. Ini memberi Anda alat untuk membuat percakapan dengan banyak suara dan memvariasikan ekspresi, emosi, dan tempo dialog. Namun, menurut kami model suara tidak menangkap kualitas penting dari suara yang kami gunakan. Faktanya, tidak mungkin untuk membodohi siapa pun.
Perwakilan Resemble AI memberi tahu kami "kebanyakan orang akan terpesona oleh hasil jika mereka melakukannya dengan benar." Kami membuat model suara dua kali dengan hasil yang serupa. Jadi, jelas tidak selalu mudah membuat klon suara yang dapat Anda gunakan untuk melakukan pencurian digital.
Meski begitu, pendiri Lyrebird (yang kini menjadi bagian dari Descript), Kundan Kumar, merasa kami sudah melewati ambang itu.
“Untuk sebagian kecil kasus, itu sudah ada,” kata Kumar. "Jika saya menggunakan audio sintetis untuk mengubah beberapa kata dalam pidato, itu sudah sangat bagus sehingga Anda akan kesulitan mengetahui apa yang berubah."
Kami juga dapat berasumsi bahwa teknologi ini akan menjadi lebih baik seiring berjalannya waktu. Sistem memerlukan lebih sedikit audio untuk membuat model, dan prosesor yang lebih cepat akan dapat membuat model secara real time. AI yang lebih cerdas akan belajar cara menambahkan irama mirip manusia yang lebih meyakinkan dan menekankan pada ucapan tanpa memiliki contoh untuk digunakan.
Yang berarti kita mungkin semakin mendekati ketersediaan kloning suara yang mudah digunakan.
Etika Kotak Pandora
Sebagian besar perusahaan yang bekerja di bidang ini tampaknya siap menangani teknologi dengan cara yang aman dan bertanggung jawab. Menyerupai AI, misalnya, memiliki keseluruhan bagian "Etika" di situsnya , dan kutipan berikut membesarkan hati:
“Kami bekerja dengan perusahaan melalui proses yang ketat untuk memastikan bahwa suara yang mereka kloning dapat digunakan oleh mereka dan memiliki persetujuan yang tepat dengan pengisi suara.”
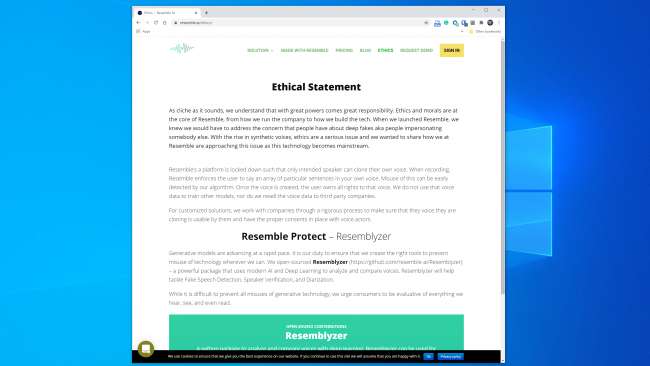
Demikian pula, Kumar mengatakan Lyrebird prihatin tentang penyalahgunaan sejak awal. Itulah mengapa sekarang, sebagai bagian dari Descript, fitur ini hanya memungkinkan orang untuk mengkloning suaranya sendiri. Faktanya, Resemble dan Descript mengharuskan orang merekam sampel mereka secara langsung untuk mencegah kloning suara yang tidak sesuai.
Sungguh menggembirakan bahwa para pemain komersial besar telah memberlakukan beberapa pedoman etika. Namun, penting untuk diingat bahwa perusahaan ini bukanlah penjaga gerbang teknologi ini. Ada sejumlah alat sumber terbuka yang sudah tersedia, yang tidak memiliki aturan. Menurut Henry Ajder, kepala intelijen ancaman di Deeptrace , Anda juga tidak memerlukan pengetahuan pengkodean lanjutan untuk menyalahgunakannya.
“Banyak kemajuan di bidang ini datang melalui kerja kolaboratif di tempat-tempat seperti GitHub, menggunakan implementasi sumber terbuka dari makalah akademis yang diterbitkan sebelumnya,” kata Ajder. “Ini dapat digunakan oleh siapa saja yang memiliki kemampuan sedang dalam pengkodean.”
Profesional Keamanan Telah Melihat Semua Ini Sebelumnya
Penjahat telah mencoba mencuri uang melalui telepon jauh sebelum kloning suara dimungkinkan, dan pakar keamanan selalu siap sedia untuk mendeteksi dan mencegahnya. Perusahaan keamanan Pindrop mencoba menghentikan penipuan bank dengan memverifikasi apakah penelepon adalah yang dia klaim dari audio. Pada 2019 saja, Pindrop mengklaim telah menganalisis 1,2 miliar interaksi suara dan mencegah sekitar $ 470 juta dalam upaya penipuan.
Sebelum kloning suara, penipu mencoba sejumlah teknik lain. Yang paling sederhana adalah menelepon dari tempat lain dengan info pribadi tentang merek tersebut.
“Tanda tangan akustik kami memungkinkan kami menentukan bahwa panggilan sebenarnya datang dari telepon Skype di Nigeria karena karakteristik suaranya,” kata CEO Pindrop, Vijay Balasubramaniyan. “Kemudian, kita dapat membandingkan bahwa mengetahui pelanggan menggunakan telepon AT&T di Atlanta.”
Beberapa penjahat juga berkarier dengan menggunakan suara latar belakang untuk menjatuhkan perwakilan bank.
“Ada penipu yang kami sebut Manusia Ayam yang selalu memiliki ayam jago di latar belakang,” kata Balasubramaniyan. "Dan ada seorang wanita yang menggunakan bayi yang menangis di latar belakang untuk meyakinkan agen call center, bahwa 'hei, saya sedang melalui masa sulit' untuk mendapatkan simpati.”
Dan kemudian ada penjahat pria yang mengincar rekening bank wanita.
“Mereka menggunakan teknologi untuk meningkatkan frekuensi suaranya agar terdengar lebih feminin,” jelas Balasubramaniyan. Ini bisa berhasil, tetapi "terkadang, perangkat lunaknya kacau dan terdengar seperti Alvin and the Chipmunks".
Tentu saja, kloning suara hanyalah perkembangan terbaru dalam perang yang terus meningkat ini. Perusahaan keamanan telah menangkap penipu yang menggunakan audio sintetis dalam setidaknya satu serangan spearfishing.
“Dengan target yang tepat, bayarannya bisa masif,” kata Balasubramaniyan. “Jadi, masuk akal untuk mendedikasikan waktu untuk membuat suara yang disintesis dari individu yang tepat.”
Bisakah Ada yang Tahu Jika Suara Itu Palsu?

Dalam hal mengenali apakah suatu suara telah dipalsukan, ada kabar baik dan buruk. Yang buruk adalah klon suara semakin baik setiap hari. Sistem pembelajaran mendalam semakin pintar dan membuat suara yang lebih otentik yang membutuhkan lebih sedikit audio untuk dibuat.
Seperti yang Anda ketahui dari klip ini Presiden Obama menyuruh MC Ren untuk mengambil sikap , kita juga sudah sampai pada titik di mana model suara dengan ketelitian tinggi dan dibuat dengan cermat dapat terdengar cukup meyakinkan di telinga manusia.
Semakin panjang klip suara, semakin besar kemungkinan Anda melihat ada sesuatu yang salah. Untuk klip yang lebih pendek, Anda mungkin tidak menganggapnya sintetik — terutama jika Anda tidak punya alasan untuk mempertanyakan keabsahannya.
Semakin jelas kualitas suaranya, semakin mudah mengenali tanda-tanda deepfake audio. Jika seseorang berbicara langsung ke mikrofon berkualitas studio, Anda akan dapat mendengarkan dengan cermat. Tetapi rekaman panggilan telepon berkualitas buruk atau percakapan yang direkam dengan perangkat genggam di garasi parkir yang bising akan jauh lebih sulit untuk dievaluasi.
Kabar baiknya adalah, meskipun manusia kesulitan memisahkan yang asli dari yang palsu, komputer tidak memiliki batasan yang sama. Untungnya, alat verifikasi suara sudah ada. Pindrop memiliki satu sistem yang mengadu domba sistem pembelajaran mendalam satu sama lain. Ini menggunakan keduanya untuk mengetahui apakah sampel audio adalah orang yang seharusnya. Namun, itu juga memeriksa apakah manusia bahkan dapat membuat semua suara dalam sampel.
Bergantung pada kualitas audio, setiap detik ucapan berisi antara 8.000-50.000 sampel data yang dapat dianalisis.
“Hal-hal yang biasanya kami cari adalah kendala bicara karena evolusi manusia,” jelas Balasubramaniyan.
Misalnya, dua suara vokal memiliki kemungkinan pemisahan minimum satu sama lain. Ini karena secara fisik tidak mungkin untuk mengucapkannya lebih cepat karena kecepatan otot di mulut dan pita suara Anda dapat mengatur ulang dirinya sendiri.
“Saat kami melihat audio yang disintesis,” Balasubramaniyan berkata, “kami terkadang melihat sesuatu dan berkata, 'ini tidak akan pernah bisa dibuat oleh manusia karena satu-satunya orang yang dapat menghasilkan ini harus memiliki leher sepanjang tujuh kaki. ”
Ada juga kelas suara yang disebut "frikatif". Mereka terbentuk saat udara melewati penyempitan sempit di tenggorokan Anda saat Anda mengucapkan huruf seperti f, s, v, dan z. Frikatif sangat sulit dikuasai sistem deep-learning karena perangkat lunak kesulitan membedakannya dari kebisingan.
Jadi, setidaknya untuk saat ini, perangkat lunak kloning suara tersandung oleh fakta bahwa manusia adalah kantong daging yang mengalirkan udara melalui lubang di tubuh mereka untuk berbicara.
“Saya terus bercanda bahwa deepfakes sangat merengek,” kata Balasubramaniyan. Dia menjelaskan bahwa sangat sulit bagi algoritme untuk membedakan akhir kata dari kebisingan latar belakang dalam rekaman. Ini menghasilkan banyak model suara dengan ucapan yang lebih sedikit dibandingkan manusia.
“Saat algoritme melihat hal ini sering terjadi,” Balasubramaniyan berkata, “secara statistik, menjadi lebih yakin bahwa audio yang dihasilkan, bukan manusia”.
Resemble AI juga menangani masalah pendeteksian langsung dengan Resemblyzer, alat pembelajaran dalam sumber terbuka tersedia di GitHub . Itu dapat mendeteksi suara palsu dan melakukan verifikasi speaker.
Dibutuhkan Kewaspadaan
Selalu sulit untuk menebak apa yang mungkin akan terjadi di masa depan, tetapi teknologi ini hampir pasti akan menjadi lebih baik. Selain itu, siapa pun berpotensi menjadi korban — bukan hanya individu terkenal, seperti pejabat terpilih atau CEO perbankan.
“Saya pikir kita berada di ambang pelanggaran audio pertama saat suara orang dicuri,” prediksi Balasubramaniyan.
Namun, saat ini, risiko dunia nyata dari deepfake audio rendah. Sudah ada alat yang tampaknya melakukan pekerjaan yang cukup baik untuk mendeteksi video sintetis.
Plus, kebanyakan orang tidak berisiko mengalami serangan. Menurut Ajder, pemain komersial utama "sedang mengerjakan solusi yang dipesan lebih dahulu untuk klien tertentu, dan sebagian besar memiliki pedoman etika yang cukup baik tentang dengan siapa mereka akan dan tidak akan bekerja sama."
Ancaman sebenarnya ada di depan, saat Ajder melanjutkan untuk menjelaskan:
“Pandora's Box akan menjadi orang-orang yang menggabungkan penerapan teknologi sumber terbuka menjadi aplikasi atau layanan yang semakin ramah pengguna dan dapat diakses yang tidak memiliki lapisan pengawasan etis seperti yang dilakukan oleh solusi komersial saat ini.”
Ini mungkin tidak bisa dihindari, tetapi perusahaan keamanan sudah memasukkan deteksi audio palsu ke dalam perangkat mereka. Tetap saja, tetap aman membutuhkan kewaspadaan.
Kami telah melakukan ini di area keamanan lain, kata Ajder. “Banyak organisasi menghabiskan banyak waktu untuk mencoba memahami apa kerentanan zero-day berikutnya, misalnya. Audio sintetis hanyalah perbatasan berikutnya. ”







