
Video-väärennökset tarkoittavat, että et voi luottaa kaikkeen, mitä näet. Nyt äänen syväpetokset saattavat tarkoittaa sitä, että et voi enää luottaa korviin. Oliko se todella presidentti, joka julisti sodan Kanadalle? Onko se todella isäsi puhelimessa, joka pyytää hänen sähköpostiosoitettaan?
Lisää toinen eksistentiaalinen huoli luetteloon siitä, kuinka omat hubrimme voivat väistämättä tuhota meidät. Reaganin aikakaudella ainoat todelliset tekniset riskit olivat ydin-, kemiallisten ja biologisten sodankäyntien uhka.
Seuraavien vuosien aikana meillä on ollut tilaisuus pakkomielle nanoteknologian harmaasta goosta ja maailmanlaajuisista pandemioista. Nyt meillä on syviä väärennöksiä - ihmiset menettävät hallinnan kaltaisuudesta tai äänestä.
Mikä on äänen väärennös?
Useimmat meistä ovat nähneet video deepfake , jossa syvällisen oppimisen algoritmeja käytetään korvaamaan yksi henkilö jonkun toisen kaltaisella. Parhaat ovat ärsyttävän realistisia, ja nyt on äänen vuoro. Äänifake on silloin, kun synteettisen äänen tuottamiseen käytetään "kloonattua" ääntä, jota ei voida erottaa todellisen henkilön äänestä.
"Se on kuin Photoshop for voice", sanoi Zohaib Ahmed, toimitusjohtaja Muistuttavat tekoälyä , hänen yrityksensä äänen kloonaustekniikasta.
Huonot Photoshop-työt poistetaan kuitenkin helposti. Turvayhtiö, jonka kanssa puhuimme, sanoi ihmisten vain vain arvaavan, onko äänen syvä väärennös todellinen vai väärennetty noin 57 prosentin tarkkuudella - ei parempi kuin kolikon läppä.
Lisäksi, koska niin monet äänitallenteet ovat heikkolaatuisia puheluita (tai nauhoitettu meluisissa paikoissa), äänen väärennökset voidaan tehdä vielä erottamattomammiksi. Mitä huonompi äänenlaatu on, sitä vaikeampi on poimia niitä ilmaisimia, joiden mukaan ääni ei ole oikea.
Mutta miksi kukaan tarvitsee silti Photoshopia?
Synteettisen äänen pakottava kotelo
Synteettiselle äänelle on oikeastaan valtava kysyntä. Ahmedin mukaan "sijoitetun pääoman tuottoprosentti on hyvin välitön".
Tämä pätee erityisesti pelaamiseen. Aiemmin puhe oli pelin yksi komponentti, jota ei ollut mahdollista luoda tarpeen mukaan. Jopa vuorovaikutteisissa nimikkeissä, joissa on reaaliajassa toistettuja elokuvalaatuisia kohtauksia, sanallinen vuorovaikutus pelaamattomien hahmojen kanssa on aina oleellisesti staattista.
Nyt tekniikka on kuitenkin kiinni. Studiot voivat kloonata näyttelijän äänen ja käyttää tekstistä puheeksi -moottoreita, jotta hahmot voivat sanoa mitä tahansa reaaliajassa.
Mainonnassa, tekniikassa ja asiakastukessa on myös perinteisempiä käyttötapoja. Tässä on tärkeää, että ääni kuulostaa aidosti ihmiseltä ja reagoi henkilökohtaisesti ja asiayhteyteen ilman inhimillistä panosta.
Ääni kloonausyritykset ovat myös innoissaan lääketieteellisistä sovelluksista. Äänen korvaaminen ei tietenkään ole mitään uutta lääketieteessä - Stephen Hawking käytti tunnetusti robottisyntetisoitua ääntä menetettyään omansa vuonna 1985. Moderni äänikloonaus kuitenkin lupaa jotain vielä parempaa.
Vuonna 2008 synteettinen ääniyhtiö, CereProc , antoi myöhäiselle elokuvakriitikolle Roger Ebertille äänensä takaisin syövän jälkeen. CereProc oli julkaissut verkkosivun, jonka avulla ihmiset voivat kirjoittaa viestejä, jotka sitten puhutaan entisen presidentin George Bushin äänellä.
"Ebert näki sen ja ajatteli:" No, jos he pystyvät kopioimaan Bushin äänen, heidän pitäisi pystyä kopioimaan minun ", sanoi Matthew Aylett, CereProcin tieteellinen johtaja. Sitten Ebert pyysi yritystä luomaan korvaavan äänen, jonka he tekivät käsittelemällä suuren kirjaston äänitallenteita.
"Se oli yksi ensimmäisistä kerroista, kun kukaan oli koskaan tehnyt niin, ja se oli todellinen menestys", Aylett sanoi.
Viime vuosina useat yritykset (mukaan lukien CereProc) ovat tehneet yhteistyötä ALS-yhdistys on Projekti Revoice tarjota synteettisiä ääniä ALS-potilaista.

Kuinka synteettinen ääni toimii
Ääni kloonauksella on hetki juuri nyt, ja joukko yrityksiä kehittää työkaluja. Muistuttavat tekoälyä ja Kuvaus on online-demoja, kuka tahansa voi kokeilla ilmaiseksi. Tallennat vain näytöllä näkyvät lauseet ja muutamassa minuutissa luodaan malli äänestäsi.
Voit kiittää tekoälyä - erityisesti syvällisesti oppivat algoritmit —Soittaa äänitetyn puheen sovittaminen tekstiin ymmärtääksesi äänesi muodostavat komponenttifoneemit. Sitten se käyttää tuloksena olevia kielellisiä rakennuspalikoita arvioimaan sanoja, joita se ei ole kuullut puhuvasi.
Perustekniikka on ollut käytössä jonkin aikaa, mutta kuten Aylett huomautti, se vaati apua.
"Äänen kopiointi oli vähän kuin leivonnaisia", hän sanoi. "Se oli tavallaan vaikea tehdä, ja oli olemassa useita tapoja, joilla joudut säätämään sitä käsin saadaksesi sen toimimaan."
Kehittäjät tarvitsivat valtavia määriä tallennettua äänidataa saadakseen saavutettavissa olevat tulokset. Muutama vuosi sitten tulvat avautuivat. Tietokonenäköalan tutkimus osoittautui kriittiseksi. Tutkijat kehittivät generatiivisia kontradiktorisia verkkoja (GAN), jotka voisivat ensimmäistä kertaa ekstrapoloida ja tehdä ennusteita olemassa olevien tietojen perusteella.
"Sen sijaan, että tietokone näki hevosen kuvan ja sanoi" tämä on hevonen ", mallini voisi nyt tehdä hevosesta seepran", Aylett sanoi. "Joten puhesynteesin räjähdys johtuu nyt akateemisesta työstä tietokoneen näkemisen kautta."
Yksi suurimmista innovaatioista äänikloonauksessa on ollut yleinen vähennys siitä, kuinka paljon raakadataa tarvitaan äänen luomiseen. Aikaisemmin järjestelmät tarvitsivat kymmeniä tai jopa satoja tunteja ääntä. Nyt kuitenkin osaavia ääniä voidaan tuottaa vain muutaman minuutin sisällöstä.
LIITTYVÄT: Tekoälyn ongelma: koneet oppivat asioita, mutta eivät ymmärrä niitä
Eksistenttinen pelko olla luottamatta mihinkään
Tämä tekniikka sekä ydinvoima, nanotekniikka, 3D-tulostus ja CRISPR ovat samanaikaisesti jännittäviä ja kauhistuttavia. Loppujen lopuksi uutisissa on jo esiintynyt tapauksia, joissa ihmisiä kloonattiin. Vuonna 2019 yritys Yhdistyneessä kuningaskunnassa väitti sen olevan huijasi äänen syvä väärennös puhelu rahan johtamiseen rikollisille.
Sinun ei myöskään tarvitse mennä kauas löytääksesi yllättävän vakuuttavia ääniväärennöksiä. YouTube-kanava Laulujen synteesi sisältää tunnettuja ihmisiä, jotka sanovat asioita, joita eivät koskaan sanoneet George W. Bush lukee 50 Cent: n julkaisua ”In Da Club” . Se on paikalla.
Muualla YouTubessa voit kuulla lauman entisiä presidenttejä, mukaan lukien Obama, Clinton ja Reagan, rappaavat NWA: ta . Musiikki ja taustan äänet auttavat peittämään joitain ilmeisiä robottihäiriöitä, mutta jopa epätäydellisessä tilassa potentiaali on ilmeinen.
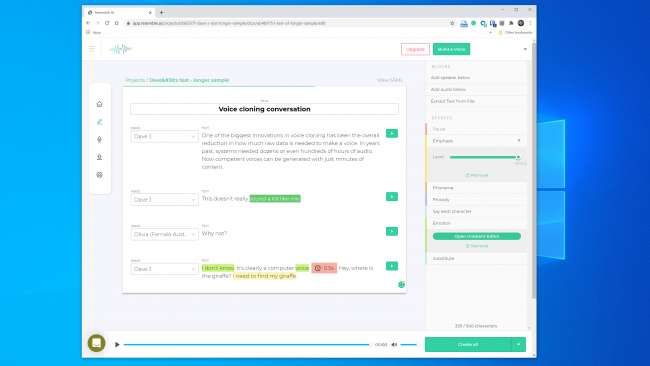
Kokeilimme työkaluja Muistuttavat tekoälyä ja Kuvaus ja loi äänikloonin. Descript käyttää ääni-kloonausmoottoria, jota alun perin kutsuttiin Lyrebirdiksi ja joka oli erityisen vaikuttava. Olimme järkyttyneitä laadusta. Oman äänesi kuuleminen sanomalla asioita, joita et ole koskaan sanonut, on ärsyttävää.
Puhe on ehdottomasti robottilaatu, mutta rennossa kuunnelussa useimmilla ihmisillä ei olisi syytä ajatella, että se on väärennös.

Meillä oli vielä suuremmat toiveet Resemble AI: stä. Se antaa sinulle työkalut keskustelun luomiseen useilla äänillä ja vaihdella valintaikkunan ilmeikkyyttä, tunteita ja tahdistusta. Emme kuitenkaan uskoneet, että äänimalli tarttui käyttämämme äänen olennaisiin ominaisuuksiin. Itse asiassa tuskin pettänyt ketään.
Eräs AI-edustaja kertoi meille, että "tulokset räjäyttävät suurimman osan ihmisistä, jos he tekevät sen oikein". Rakensimme äänimallin kahdesti samanlaisilla tuloksilla. Joten ilmeisesti ei ole aina helppoa tehdä äänikloonia, jolla voit vetää digitaalisen ryöstön.
Siitä huolimatta Lyrebirdin (joka on nyt osa Descriptin perustajaa) Kundan Kumarin mielestä olemme jo ylittäneet tämän kynnyksen.
"Pienessä osassa tapauksia se on jo olemassa", Kumar sanoi. "Jos käytän synteettistä ääntä muuttaaksesi muutaman sanan puheessa, se on jo niin hyvä, että sinulla on vaikea tietää, mikä muuttui."
Voimme myös olettaa, että tämä tekniikka paranee vain ajan myötä. Järjestelmät tarvitsevat vähemmän ääntä mallin luomiseen, ja nopeammat prosessorit pystyvät rakentamaan mallin reaaliajassa. Älykkäämpi tekoäly oppii lisäämään vakuuttavampaa ihmismaista poljinnopeutta ja puheen korostamista ilman esimerkkiä.
Mikä tarkoittaa, että voimme hiipiä lähemmäksi vaivattoman äänikloonauksen laajaa saatavuutta.
Pandoran laatikon etiikka
Useimmat tällä alueella työskentelevät yritykset näyttävät olevan valmiita käsittelemään tekniikkaa turvallisella ja vastuullisella tavalla. Muistuttavat esimerkiksi tekoälyä koko ”etiikka” -osio verkkosivustollaan , ja seuraava ote on rohkaiseva:
"Työskentelemme yritysten kanssa tiukan prosessin avulla varmistaaksemme, että heidän kloonaama ääni on heidän käytettävissään ja että meillä on asianmukaiset suostumukset ääninäyttelijöiden kanssa."
Samoin Kumar sanoi Lyrebirdin olevan huolissaan väärinkäytöksistä alusta alkaen. Siksi nyt osana Descriptiä se antaa ihmisten vain kloonata oman äänensä. Itse asiassa sekä muistuttaa että kuvailevat vaativat, että ihmiset tallentavat näytteensä elävinä, jotta estetään epäjohdonmukainen äänikloonaus.
On rohkaisevaa, että suuret kaupalliset toimijat ovat asettaneet eettisiä ohjeita. On kuitenkin tärkeää muistaa, että nämä yritykset eivät ole tämän tekniikan vartijoita. Luonnossa on jo useita avoimen lähdekoodin työkaluja, joille ei ole sääntöjä. Uhrin tiedustelupäällikkö Henry Ajderin mukaan Deeptrace , et myöskään tarvitse edistynyttä koodaustietoa väärinkäyttöä varten.
"Paljon edistymistä avaruudessa on tapahtunut yhteistyötyössä sellaisissa paikoissa kuin GitHub, käyttäen aiemmin julkaistujen akateemisten julkaisujen avoimen lähdekoodin toteutuksia", Ajder sanoi. "Sitä voivat käyttää kuka tahansa, jolla on kohtuullinen taito koodaamiseen."
Turvallisuusalan ammattilaiset ovat nähneet kaiken tämän aiemmin
Rikolliset ovat yrittäneet varastaa rahaa puhelimitse kauan ennen kuin ääni kloonaus oli mahdollista, ja turvallisuusasiantuntijat ovat aina olleet päivystämässä sen havaitsemiseksi ja estämiseksi. Turvayhtiö Pindrop yrittää lopettaa pankkipetokset tarkistamalla, onko soittaja äänen perusteella se, jonka hän väittää olevansa. Pelkästään vuonna 2019 Pindrop väittää analysoineensa 1,2 miljardia ääniyhteyttä ja estävän noin 470 miljoonan dollarin petosyritykset.
Ennen äänikloonausta petokset kokeilivat useita muita tekniikoita. Yksinkertaisin oli vain soittaminen muualta ja henkilökohtaisia tietoja merkistä.
"Akustisen allekirjoituksemme avulla voimme määrittää, että puhelu on todella tulossa Nigerian Skype-puhelimesta ääniominaisuuksien vuoksi", sanoi Pindropin toimitusjohtaja Vijay Balasubramaniyan. "Sitten voimme verrata sitä, että asiakkaan tietäminen käyttää AT & T-puhelinta Atlantassa."
Jotkut rikolliset ovat myös tehneet uran taustahälytysten käytöstä pankkitoiminnan heittämiseksi.
"Meillä on petos, jota kutsumme kanamieheksi ja jolla oli aina kukkoja taustalla", Balasubramaniyan sanoi. "Ja on yksi nainen, joka käytti taustalla itkevää vauvaa saadakseen pohjimmiltaan vakuuttamaan puhelinkeskuksen edustajat siitä, että" hei, olen menossa kovassa ajassa "saadakseni sympatiaa."
Ja sitten ovat miesrikolliset, jotka hoitavat naisten pankkitilejä.
"He käyttävät tekniikkaa äänen taajuuden lisäämiseksi, naisellisemmaksi kuulemiseksi", Balasubramaniyan selitti. Nämä voivat olla onnistuneita, mutta "toisinaan ohjelmisto sekaantuu ja ne kuulostavat Alvinilta ja pikkuorjoilta".
Tietenkin ääni kloonaus on vain viimeisin kehitys tässä jatkuvasti kärjistyvässä sodassa. Turvayritykset ovat jo kiinni petoksista, jotka käyttävät synteettistä ääntä ainakin yhdessä hautauskalahyökkäyksessä.
"Oikealla kohteella voitto voi olla valtava", Balasubramaniyan sanoi. "Joten, on järkevää käyttää aikaa oikean yksilön syntetisoidun äänen luomiseen."
Voiko kukaan kertoa, onko ääni väärennetty?

Kun on kyse äänen väärentämisestä, on sekä hyviä että huonoja uutisia. Huono on se, että äänikloonit paranevat joka päivä. Syväoppimisjärjestelmät ovat älykkäämpiä ja tuottavat aitoja ääniä, joiden luominen vaatii vähemmän ääntä.
Kuten voit kertoa tästä leikkeestä Presidentti Obama käski MC Renin ottamaan kantaa , olemme myös jo päässeet pisteeseen, jossa korkealaatuinen, huolellisesti rakennettu äänimalli voi kuulostaa melko vakuuttavalta ihmiskorvalle.
Mitä pidempi äänileike on, sitä todennäköisemmin huomaat, että jotain on vialla. Lyhyemmissä leikkeissä et ehkä huomaa, että se on synteettistä - varsinkin jos sinulla ei ole syytä kyseenalaistaa sen laillisuutta.
Mitä selkeämpi äänenlaatu on, sitä helpompaa on havaita äänifake-merkkejä. Jos joku puhuu suoraan studiolaatuiseen mikrofoniin, voit kuunnella tarkkaan. Mutta meluisassa pysäköintihallissa olevaan kädessä pidettävään laitteeseen tallennettua huonolaatuista puhelutallennusta tai keskustelua on paljon vaikeampi arvioida.
Hyvä uutinen on, että vaikka ihmisillä on vaikeuksia erottaa todellinen väärennöksestä, tietokoneilla ei ole samoja rajoituksia. Onneksi äänivahvistustyökalut ovat jo olemassa. Pindropilla on se, joka asettaa syvällisen oppimisen järjestelmät toisiinsa. Se käyttää molempia selvittääkseen, onko ääninäyte henkilö, jonka sen pitäisi olla. Se tutkii kuitenkin myös, pystyykö ihminen edes tuottamaan kaikki näytteessä olevat äänet.
Äänen laadusta riippuen jokainen puheen sekunti sisältää 8 000-50 000 analysoitavaa datanäytettä.
"Tyypillisesti etsimämme asiat ovat ihmisen evoluutiosta johtuvia puheen rajoituksia", Balasubramaniyan selitti.
Esimerkiksi kahdella lauluäänellä on mahdollisimman pieni etäisyys toisistaan. Tämä johtuu siitä, että fyysisesti ei ole mahdollista sanoa niitä nopeammin, koska nopeus, jolla suusi lihakset ja äänijohdot voivat muuttaa itseään.
"Kun katsomme syntetisoitua ääntä", Balasubramaniyan sanoi, "me joskus näemme asioita ja sanomme:" Ihminen ei olisi koskaan voinut tuottaa tätä, koska ainoalla henkilöllä, joka olisi voinut tuottaa tämän, on oltava seitsemän jalkaa pitkä kaula. ”
Siellä on myös ääniluokka nimeltä "frikatiivit". Ne muodostuvat, kun ilma kulkee kapean kurkun kurkun läpi, kun lausut f, s, v ja z kirjaimia. Fricatiiveja on erityisen vaikea oppia syvälleoppiville järjestelmille, koska ohjelmistolla on vaikeuksia erottaa ne melusta.
Joten ainakin toistaiseksi ääni-kloonausohjelmisto on kompastunut siitä, että ihmiset ovat lihapusseja, jotka virtaavat ilmaa kehossa olevien reikien läpi puhumaan.
"Jätän vitsailua siitä, että syväpetokset ovat erittäin valittavia", sanoi Balasubramaniyan. Hän selitti, että algoritmien on erittäin vaikea erottaa sanojen päät taustamelun äänitteestä. Tämä johtaa moniin puhemalleihin, joiden puhe kulkee enemmän kuin ihmiset.
"Kun algoritmi näkee tämän tapahtuvan paljon", Balasubramaniyan sanoi, "tilastollisesti on varmempaa, että ääni on luotu ihmisen sijaan."
Resemblezer on avoimen lähdekoodin syvän oppimisen työkalu, joka muistuttaa myös AI: ta saatavilla GitHubissa . Se tunnistaa väärennetyt äänet ja suorittaa kaiuttimien vahvistuksen.
Se vie valppautta
Aina on vaikea arvata, mitä tulevaisuus voi odottaa, mutta tämä tekniikka paranee melkein varmasti vain. Kuka tahansa voi myös olla uhri - ei vain korkean profiilin henkilöt, kuten valitut virkamiehet tai pankkien toimitusjohtajat.
"Luulen, että olemme ensimmäisen äänirikkomuksen partaalla, jossa ihmisten ääni varastetaan", Balasubramaniyan ennusti.
Tällä hetkellä audiosyvennysten aiheuttama tosiasiallinen riski on kuitenkin pieni. On jo työkaluja, jotka näyttävät tekevän melko hyvää työtä havaita synteettinen video.
Lisäksi useimmat ihmiset eivät ole vaarassa hyökätä. Ajderin mukaan tärkeimmät kaupalliset toimijat "työskentelevät räätälöityjen ratkaisujen parissa tietyille asiakkaille, ja useimmilla on melko hyvät eettiset ohjeet siitä, kenen kanssa he tekisivät ja eivät."
Todellinen uhka on kuitenkin edessä, kun Ajder selitti:
"Pandoran laatikko tulee olemaan ihmisiä, jotka mukauttavat avoimen lähdekoodin teknologian toteutuksia yhä käyttäjäystävällisemmiksi, helppokäyttöisemmiksi sovelluksiksi tai palveluiksi, joilla ei ole sellaista eettistä valvontakerrosta kuin kaupallisilla ratkaisuilla tällä hetkellä."
Tämä on luultavasti väistämätöntä, mutta turva-alan yritykset vievät jo väärennetyn äänentunnistuksen työkalupakkeihinsa. Silti turvassa pysyminen vaatii valppautta.
"Olemme tehneet tämän muilla turvallisuusalueilla", sanoi Ajder. "Monet organisaatiot viettävät paljon aikaa esimerkiksi yrittäessään ymmärtää mikä on seuraava nollapäivän haavoittuvuus. Synteettinen ääni on yksinkertaisesti seuraava raja. "
LIITTYVÄT: Mikä on syväfake, ja pitäisikö minun olla huolissani?







