Begrijp de verwerking van natuurlijke taal

Websites en apps kunnen verschillende bewegende delen hebben, inclusief creatieve, server-side-side-side-side-side-side-side-side-side-side-side-side. AI kan een van deze componenten aansluiten.
Aan de voorkant kunt u spraakopdrachten, chatbot-interfaces of reactieve WebGL creatieve elementen aansluiten. Op het achtereinde gebruiken databases intelligente algoritmen om snelheid en analyse te maximaliseren. API's kunnen een laag abstractie bieden van een breed scala aan AI-functies, van voorspellingen tot collectieve training.
Als je net begint als een ontwikkelaar en wat pointers nodig heeft, zoek dan erachter Hoe maak je een app , of we kunnen u helpen kiezen welke website bouwer web hosting service en cloud opslag gebruiken.
- Chatbots: Wat u moet weten.
Natuurlijke taal
Natuurlijke taalverwerking (NLP) richt zich op de interacties tussen machines en menselijke talen. Het is het doel van NLP om enorme hoeveelheden taalgegevens te verwerken en te analyseren om de natuurlijke communicatie tussen mensen en machines te verbeteren. Dit veld van AI bevat spraakherkenning, het begrijpen van taal en het genereren van natuurlijke taal. Onze focus ligt op het begrijpen van de natuurlijke taal, het proces van het analyseren en bepalen van de betekenis of de intentie van een tekst.
Er zijn verschillende concepten die gewoon zijn voor NLP:
- Taal detecteren - Inzicht in welke taal wordt gebruikt in de tekst is fundamenteel om te weten welke woordenboeken, syntaxis- en grammatica-regels om in analyse te gebruiken.
- Entiteit extractie - Identificatie van de sleutelwoorden in frases, hoe relevant of saillant zij zijn voor de algemene tekst en het bepalen van wat de entiteiten zijn, gebaseerd op trainings- of kennisbases.
- Sentiment analyse - Beoordeling van het algemene niveau van 'gevoel' in een tekst. Is het over het algemeen positief of negatief? Ook het sentiment gerelateerd aan elke entiteit. Weerspiegelt de verklaring positieve gevoelens of negatieve over het 'onderwerp'?
- Syntactische analyse - het begrijpen van de structuur van de tekst. Identificeer attributen zoals zinnen, delen van spraak (bijvoorbeeld zelfstandig naamwoord, werkwoord), stem, geslacht, stemming en gespannen.
- Inhoudsclassificatie of indeling - het organiseren van de inhoud van de tekst in gemeenschappelijke categorieën om ze efficiënter te verwerken. Bijvoorbeeld New York, Londen, Parijs, München zijn allemaal 'locaties' of 'steden'.
Er zijn talloze technische benaderingen van het parseren en verwerken van de gegevens. Ongeacht welke NLP-tool die u gebruikt, u de gemeenschappelijke stappen van het parseren en analyse moet aanpakken. Typisch is tekst gescheiden in logische brokken. Deze brokken worden geanalyseerd tegen getrainde gegevens of kennisbases en toegewezen waarden, meestal variërend van 0,0 tot 1,0 om het vertrouwenspercentage in de analyse weer te geven.
Google's natuurlijke taal API
We gebruiken de nieuwe natuurlijke taal API die Google is ontwikkeld voor deze tutorial. Er zijn talloze API's beschikbaar, maar Google's heeft een aantal leuke voordelen, waaronder cloud computing, snelheid, een ongelooflijk grote gebruikersbasis en machinaal leren. Google's zoekmachines en tools gebruiken al jaren AI. Dus je benadrukt al die ervaring en leren door gebruik te maken van zijn diensten voor het openbaar gericht.
API's bevatten gemakkelijk in elk project. Dit bespaart veel tijd versus handcodering van uw eigen NLP. De geabstraheerde rustgevende API stelt u in staat om te integreren met bijna elke taal die u wenst door middel van gewone krulroepen of een van de vele SDK's die beschikbaar zijn. Er zijn een paar trucjes om op te zetten, maar we zullen er een stap tegelijk doorwerken.
Klik op het pictogram bij de rechterbovenhoek van de afbeelding om het te vergroten.
01. Maak een nieuw Google Cloud-project
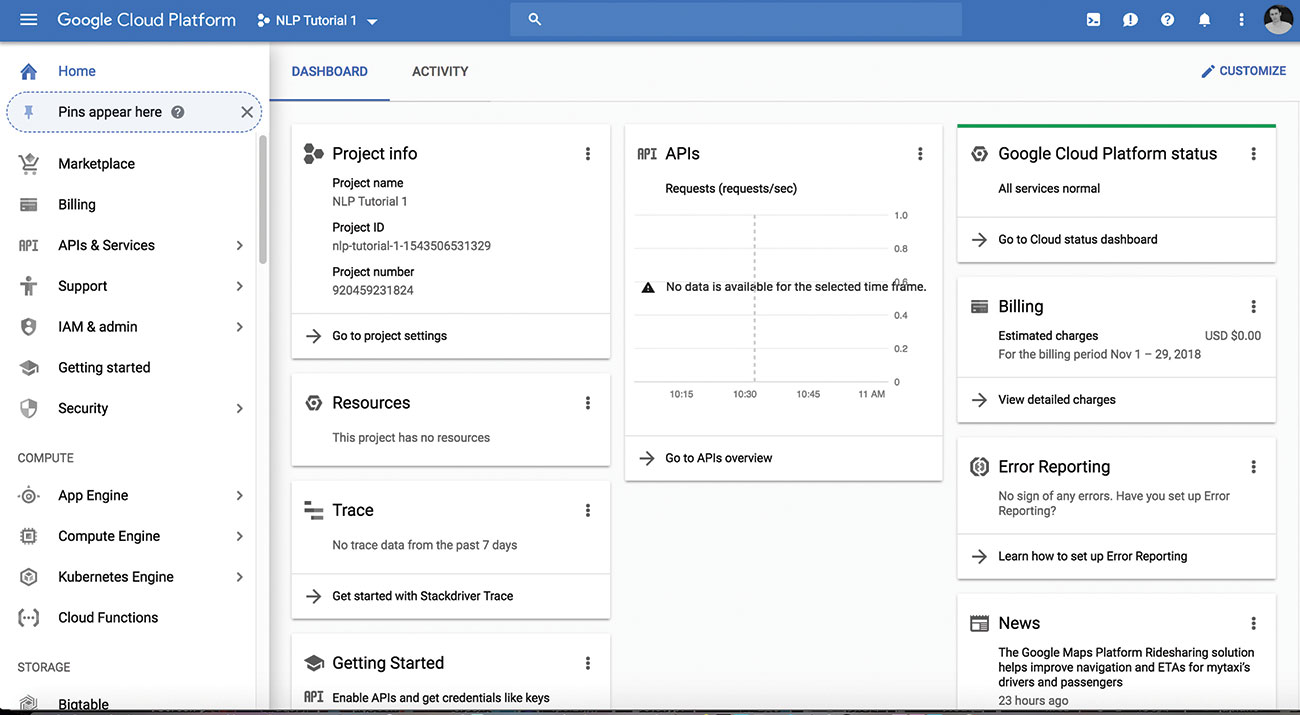
Ga naar de Google Cloud Platform Console en maak een nieuw project of selecteer een bestaande om mee te werken. De service is gratis om te gebruiken totdat u begint met het maken van een groot aantal API-aanvragen. Mogelijk moet u factureringsinformatie koppelen aan het account wanneer u de API activeert, maar dit wordt niet in rekening gebracht bij een laag volume en u kunt de services verwijderen nadat u het tests hebt getest als u dat wenst.
02. Schakel de cloud nl in
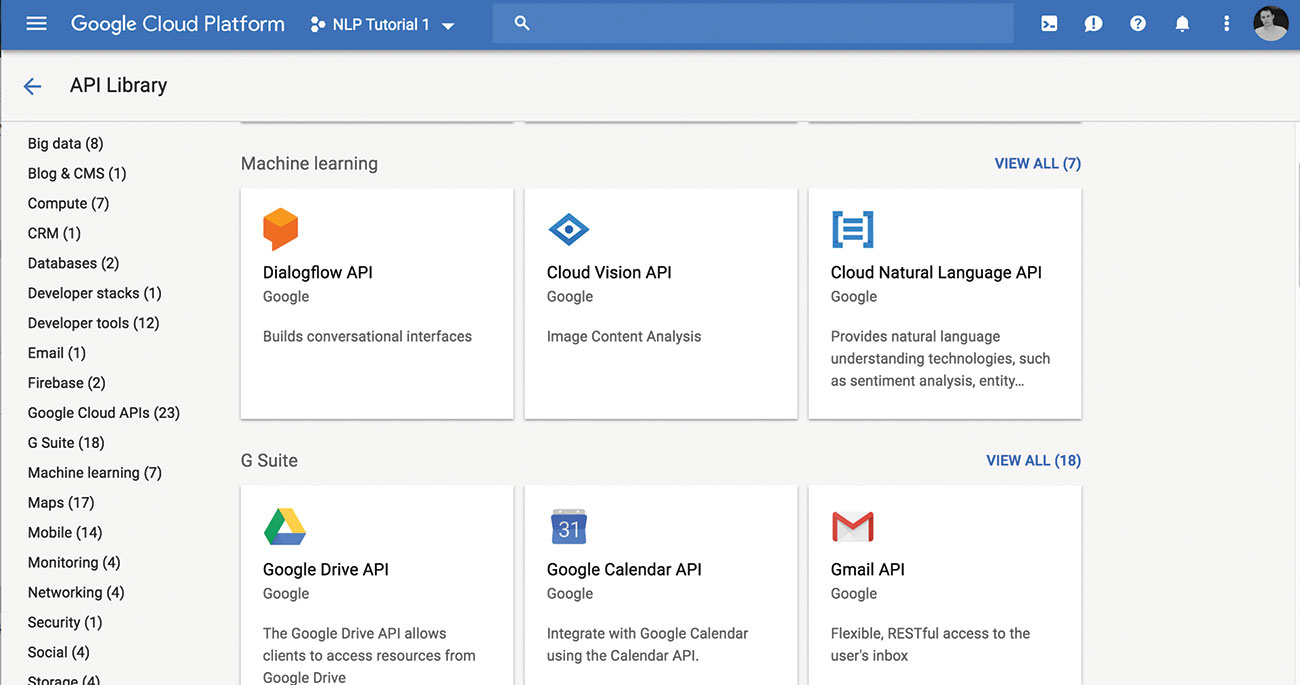
Blader naar de API-bibliotheek en selecteer de NL API. Eenmaal ingeschakeld, zou u een beetje groene cheque en het bericht 'API' hiernaast moeten zien.
03. Maak een serviceaccount aan
Je moet een opzetten serviceaccount Voor deze service. Omdat we het gebruik als een typische service gaan opzetten, is dit de beste praktijk. Het werkt ook het beste met authenticatiestroom.
04. Download privésleutel
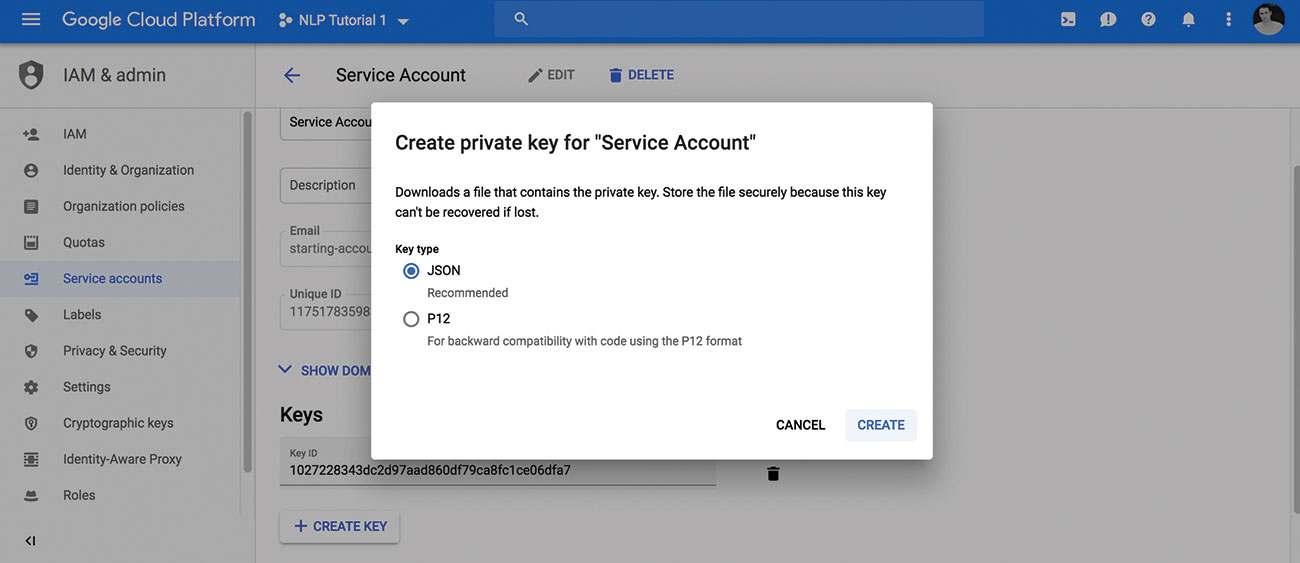
Zodra u een project hebt met de API ingeschakeld en een servicekening kunt u uw privésleutel downloaden als een JSON-bestand. Let op de locatie van het bestand, zodat u het in de volgende stappen kunt gebruiken.
Als u problemen hebt met de eerste paar stappen is er een gids hier Dat helpt, wat eindigt met het downloaden van de JSE-sleutel.
05. Set Milieuvariabele
Vervolgens moet je de Google_Application_credentials Milieuvariabele, dus het is toegankelijk via onze API-oproepen. Dit wijst op uw JSON-bestand dat u zojuist hebt gedownload en bespaart u om elke keer het pad te typen. Open een nieuw terminalvenster en gebruik de exportopdracht zoals SO:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/username/Downloads/[file name].json"Vervang de [bestandsnaam] Met uw privésleutelbestand en gebruik het pad naar uw bestand.
Op Windows kunt u hetzelfde doen via de opdrachtregel, zoals deze:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].json"Opmerking: als u uw Terminal- of Console-venster sluit, moet u mogelijk dat opnieuw uitvoeren om de variabele in te stellen.
06. Breng de API aan
Nu ben je klaar om te graven in het gebruik van de API en zie NLP in actie. U gebruikt Curl om snelle tests van de API te doen. U kunt deze methode ook vanuit uw code gebruiken.
Curl-aanvragen kunnen in de meeste talen worden gemaakt, wat betekent dat u de oproepen rechtstreeks in de opdrachtregel kunt maken of het resultaat wilt toewijzen aan een variabele in de taal van uw keuze. Kijk hier Voor sommige snelle tips over het gebruik van krullen.
Laten we een testverzoek proberen, met een eenvoudige zin. We zullen het door de analyseren eindpunt.
Voer in de interface van uw terminal of opdrachtregel de volgende opdracht in:
Curl -x Post \
-H "autorisatie: drager" $ (gcloud auth-applicatie-standaard print-access-token) \
-H "Inhoudstype: Toepassing / JSON; CharsSet = UTF-8" \
--Data "{
'document':{
'Type': 'Plain_Text',
'Inhoud': 'John McCarthy is een van de oprichtende vaders van kunstmatige intelligentie.'
'EncoDingType': 'UTF8'
} "" https://language.gogleapis.com/v1/documents:analyzeenties"Je zou een JSON-resultaat moeten zien na het uitvoeren. U kunt erop worden gevraagd de eerste keer dat u dit gebruikt om de API te activeren of toegang toe te staan. Je kunt 'ja' of 'y' beantwoorden aan die prompt en het zou de JSON daarna moeten retourneren.
Het zal een reeks vermeldingen retourneren, vergelijkbaar met degenen zoals deze eerste voor het item "John McCarthy".
{
"Naam": "John McCarthy",
"Type": "Persoon",
"Metadata": {
"Wikipedia_url": "https://en.wikipedia.org/wiki/john_mccarthy_(computer_scientist)",
"Midden": "/ m / 01SVFJ"
"Salience": 0.40979216,
"vermeldingen": [
"Tekst": {
"Inhoud": "John McCarthy",
"BEGINOFFETSET": 0
"Type": "juiste"
}, Notitie: U kunt een URL gebruiken in plaats van inhoudstekst in de inhoudsparameter van de krulverklaring.
Je kunt zien in de pagina voor monster entiteit, de naam geïdentificeerd en de type , wat de AI is bepaald is een PERSOON Het vond ook een Wikipedia-match voor de naam en heeft dat geretourneerd. Dit kan nuttig zijn, aangezien u die URL kunt gebruiken als de inhoud voor een tweede verzoek aan de API en nog meer entiteiten en informatie over deze kunt krijgen. Je kunt het ook zien salient Waarde bij 0.4, die een significant relatief belang aangeeft van de entiteit in de context van de tekst die we hebben verstrekt. Je kunt het ook zien dat het correct is geïdentificeerd als GEPAST , wat verwijst naar het Noun-type (een eigen zelfstandig naamwoord), evenals hoeveel voorkomens (vermeldingen) van de entiteit in de tekst.
De API zal waarden retourneren voor alle belangrijke entiteiten in de tekst die u indient. Dit alleen kan extreem handig zijn voor de verwerking van wat een gebruiker kan communiceren met uw app. Ongeacht wat de zin bevatte, er is een goede kans om het gaat om de persoon, John McCarthy, en we zouden wat informatie kunnen opzoeken voor de gebruiker op basis van dit alleen. We kunnen ook reageren op een manier die weerspiegelt ons inzicht Deze verklaring verwijst naar een persoon.
U kunt deze methode blijven gebruiken om de oproepen te testen die we gebruiken. U kunt ook lokale SDK in een taal instellen die u verkiest en integer in uw app.
07. Installeer de clientbibliotheek
Tijd om een eenvoudige webgebaseerde app te maken om te laten zien hoe de API in projecten te integreren.
Voor NLP-apps is het gebruikelijk om Python of Node te gebruiken. Om de veelzijdigheid van het gebruik van de API's te tonen, gebruiken we de PHP SDK. Als je de code in een andere taal wilt aanpassen, is er een geweldige bron van SDK's hier
Begin met ervoor te zorgen dat u een projectmap hebt ingesteld op uw lokale of externe server. Als u het nog niet hebt, krijgt u Composer en installeert u op uw projectmap. Mogelijk hebt u de componist al globaal geïnstalleerd en dat is ook goed.
Voer de volgende componistopdracht uit om de leveranciersbestanden op uw project te installeren:
PHP -R "kopiëren ('https://getcomposer.org/installer', 'componer-setup.php');"
php -r "if (hash_file ( 'SHA384', 'composer-setup.php') === '93b54496392c06277467 0ac18b134c3b3a95e5a5e5 c8f1a9f115f203b75bf9a129d5 daa8ba6a13e2cc8a1da080 6388a8') {echo 'Installer geverifieerd';} else {echo 'Installer corrupt'; unlink (' componist-setup.php ');} echo php_eol; "
PHP Composer-Setup.php
PHP -R "ontkoppelen ('componer-setup.php');"
PHP Composer.Phar vereist Google / Cloud-taal Componist maakt een leveranciersmap in uw projectmap en installeert alle afhankelijkheden voor u.
Als je vastloopt, instellen dit en wil je PHP gebruiken, kun je deze bron bekijken Componist installeren
08. Maak een nieuw bestand
Als u in PHP volgt, maakt u een nieuw PHP-bestand in uw projectmap. Stel het in dat je maar wilt, maar neem een eenvoudig HTML-formulier op om snel tekst door te geven.
Hier is een voorbeeld PHP-bestand met het formulier:
& LT;! DOCTYPE HTML & GT;
& lt; html & gt;
& LT; HOOFD & GT;
& LT; TITLE & GT; NET - NLP TUTORIAL & LT; / TITLE & GT;
& LT; / HOOFD & GT;
& LT; BODY & GT;
& LT; Vorm & GT;
& LT; P & GT; & LT; INPUT TYPE = 'Tekst' id = "inhoud" naam = "inhoud" placeholder = "Wat kan ik analyseren?" / & GT; & LT; / P & GT;
& LT; P & GT; & LT; INPUT TYPE = 'INDIEND' NAME = 'INDIENINGEN' ID = 'INDIENINGEN' VALUE = 'ANALYSE' & GT; & LT; / P & GT;
& LT; / Form & GT;
& lt; div class = "resultaten" & GT;
& lt;? php
// PHP-code gaat hier //
if (leeg ($ _ krijgt ['inhoud'])) {dobbelsteen ();
$ inhoud = $ _get ['inhoud'];
? & GT;
& LT; / DIV & GT;
& LT; / BODY & GT;
& LT; / HTML & GT; De code bevat een standaard HTML-bestand met een formulier, samen met een tijdelijke aanduiding voor uw PHP-code. De Code start door simpelweg te controleren op het bestaan van de inhoudsvariabele (ingediend vanuit het formulier). Als het nog niet is ingediend, gaat het gewoon uit en doet niets.
09. Maak de omgeving variabele
Vergelijkbaar met de stap die we eerder hebben gedaan bij gebruik van de opdrachtregel Curl Call, moeten we de Google_Application_credentials variabele. Dit is essentieel om het te laten authenticeren.
In PHP gebruiken we de PUTENV opdracht om een omgevingsvariabele in te stellen. De authenticatie gemaakt door de SDK verloopt, dus u moet dit in uw code op opnemen om het te pakken en deze elke keer in te stellen.
Voeg deze code volgende toe in uw PHP-code:
PUTENV ('Google_Application_credentials = / gebruikers / Richardmattka / downloads / NLP-tutorial 1-1027228343dc.json'); Vervang het pad en de bestandsnaam zoals eerder met de jouwe.
10. Initialiseer de bibliotheek
Voeg vervolgens de bibliotheek toe en initialiseer de Languageclient Klasse in uw code. Voeg deze code naast uw sectie PHP-code toe:
eisen __dir__. '/ventor/autoload.php';
gebruik Google \ Cloud \ Taal \ LanguageClient;
$ projectid = 'NLP-tutorial-1-1543506531329';
$ taal = nieuw Languageclient ([
'Projectid' = & GT; $ projectid
]); Begin met het vereisen van de Autoload van de Verkoper. Dit is vergelijkbaar in Python of Knooppunt als u uw afhankelijkheden nodig hebt. Importeer de Languageclient Vervolgens om gebruik te maken van de klas. Definieer je projectid Als u niet zeker weet wat dit is, kunt u het opzoeken in uw GCP-console, waar u het project oorspronkelijk opzet. Maak eindelijk een nieuwe Languageclient object met behulp van uw projectid en wijs het toe aan de $ taal variabele.
11. Analyseer de entiteiten
Nu ben je klaar om de NLP API in je code te gebruiken. U kunt de inhoud van het formulier in de API indienen en het resultaat krijgen. Voor nu geeft u gewoon het resultaat weer als JSON naar het scherm. In de praktijk zou je de resultaten kunnen beoordelen en ze elke manier gebruiken die je wilt. U kunt op de gebruiker op de resultaten reageren op basis van de resultaten, meer informatie opzoeken of taken uitvoeren.
To Recap, zal entiteitsanalyse informatie retourneren over de 'wat' of de 'dingen' in de tekst.
$ resultaat = $ Taal- & GT; Analyseersen ($ inhoud);
foreach ($ resultaat- & gt; entiteiten () als $ e) {
echo "& lt; div class = 'resultaat' & GT;";
$ resultaat = JSON_ENCODE ($ E, JSON_PRETTY_PRINT);
echo $ resultaat;
echo "& lt; / div & gt;";
} Deze code voert de inhoud van het ingediende formulier in aan de analyseren eindpunt en slaat het resultaat op in de $ resultaat variabele. Dan, jullie herharden over de lijst met entiteiten die is geretourneerd van $ resultaat- & gt; entiteiten () Om het een beetje meer leesbaar te maken, kunt u deze als JSON formatteren voordat u naar het scherm uitvoert. Nogmaals, dit is gewoon een voorbeeld om je te laten zien hoe je het moet gebruiken. Je zou het kunnen verwerken en reageren op de resultaten, maar je hebt echter nodig.
12. Analyseer het sentiment
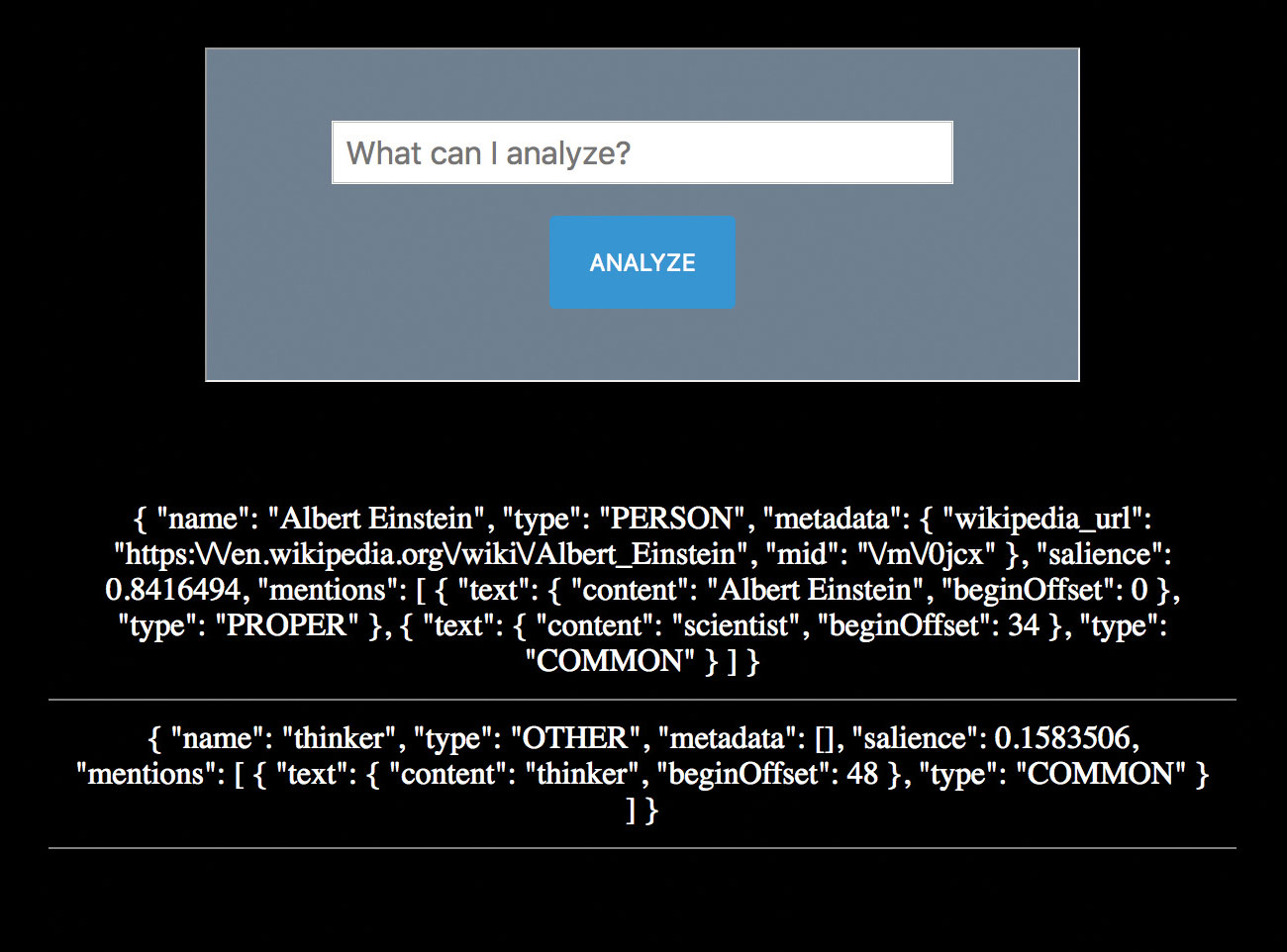
In plaats van het kennen van de 'wat' van de inhoud, kan het ook waardevol zijn om het sentiment te kennen. Hoe voelt de gebruiker? Hoe voelen ze zich over de entiteiten in hun communicatie?
Werk de code bij om de analysezeentelijkheid eindpunt. Dit beoordeelt zowel de entiteiten als voorheen, maar retourneer ook een sentimentscore voor elk.
$ resultaat = $ Taal- & GT; AnalysezeentessionSentiment ($ Inhoud);
foreach ($ resultaat- & gt; entiteiten () als $ e) {
echo "& lt; div class = 'resultaat' & GT;";
$ resultaat = JSON_ENCODE ($ E, JSON_PRETTY_PRINT);
echo $ resultaat;
echo "& lt; / div & gt;";
} Testen met de inhoud via het formulier, "Star Wars is de beste film aller tijden.", Ziet u een resultaat vergelijkbaar met dit:
{"Naam": "Star Wars", "Type": "Work_of_Art", "Metadata": {"MID": "\ / m \ / 06mmr", "Wikipedia_url": "HTTPS: \ / \ / nl.wikipedia.org \ / wiki \ / Star_wars "}," Salience ": 0.63493526," vermeldt ": [{" Tekst ": {" Inhoud ":" Star Wars "," BEGINOFFET ": 0}," Type " : "Juist", "Sentiment": {"Magnitude": 0.6, "Score": 0.6}}], "Sentiment": {"Magnitude": 0.6, "Score": 0.6}}
{"Naam": "Movie", "Type": "Work_of_Art", "Metadata": [], "Salience": 0.36506474, "vermeldt": [{"Tekst": {"Inhoud": "Film", " BEGINOFOFFSET ": 22}," Type ":" Gemeenschappelijk "," Sentiment ": {" Magnitude ": 0.9," Score ": 0.9}}]," Sentiment ": {" Magnitude ": 0.9," Score ": 0.9 }} Dit toont een positieve sentimentscore van aanzienlijke waarde. U weet nu niet alleen de sleutelwoorden die de gebruiker communiceert, maar ook hoe zij zich hierover voelen. Uw app kan op de juiste manier reageren op basis van deze gegevens. Je hebt een duidelijke identificatie van 'Star Wars' als het primaire onderwerp met een hoge salience. Je hebt een Wikipedia-link om meer informatie te pakken als je die URL terug wilt uitvoeren via dezelfde API-oproep. Je weet ook dat de gebruiker er positief over voelt. Je kunt zelfs de verklaring zien gewichten het positieve sentiment op de kwaliteit ervan als een film. Heel cool.
Gedachten afscheiden
Probeer te experimenteren met andere eindpunten. Bekijk specifiek de analysesyntax en klassifytext eindpunten. Deze geven u nog meer delen van spraakgegevens en classificatie van de inhoudsentiteiten.
Dit artikel is oorspronkelijk gepubliceerd in kwestie 315 van netto- , 's werelds best verkochte magazine voor webontwerpers en ontwikkelaars. Koop hier nummer 315 of Abonneer hier
Gerelateerde artikelen:
- 7 enorme technische trends die ontwerpers nu moeten weten
- Hoe een chatbot-ervaring te ontwerpen
- 5 tegenzichtieve conversietrucs
Procedures - Meest populaire artikelen

Maak texturen met de patroonstempelgereedschap
Procedures Jan 20, 2026(Beeldkrediet: Lino Drieghe) Als je vastzit naar een leeg canvas, of geconfronteerd met een korte die veel ruimte hee..

Maak een betere personage-animaties in Maya
Procedures Jan 20, 2026Mierenafdeling wordt een van onze artiesten die uw specifieke vragen beantwoorden Vertex ..

Hoe massale explosies te maken met V-Ray
Procedures Jan 20, 2026Het maken en compositeren van 3D-explosies is meestal een taak voor twee verschillende kunstenaars of studio-afdelingen, maar hie..

Maak realistische planten in Cinema 4D
Procedures Jan 20, 2026Ongeacht uw laatste gebruik, de meeste scènes gecentreerd op een door de mens gemaakte structuur zullen profiteren van een vleug..

Hoe codeert een Augmented Reality Marker
Procedures Jan 20, 2026Pagina 1 van 2: Pagina 1 Pagina 1 Pagina..

Textuur een authentiek versleten K-2So droid
Procedures Jan 20, 2026Pagina 1 van 2: Pagina 1 Pagina 1 Pagina..

Hoe Manga te maken met een wilde west-twist
Procedures Jan 20, 2026Westerns zijn iets waar ik altijd van heb gehouden. In deze tutorial creëer ik een afbeelding in de typische manga-stijl, maar i..

Versnel uw 3D-modellering
Procedures Jan 20, 2026Deze tutorial bestrijkt het proces van het bouwen van een actief - in dit geval A ruimteschipontwerp - met een eer..
Categorieën
- AI & Machine Learning
- AirPods
- Amazone
- Amazon Alexa & Amazon Echo
- Alexa Amazon En Amazon Echo
- Amazon Fire TV
- Amazon Prime Video
- Android
- Android-telefoons En -tablets
- Android -telefoons En Tablets
- Android TV
- Apple
- Apple App Store
- Apple HomeKit & Apple HomePod
- Apple Music
- Apple TV
- Apple Watch
- Apps & Web Apps
- Apps En Web -apps
- Audio
- Chromebook En Chrome OS
- Chromebook & Chrome OS
- Chromecast
- Cloud & Internet
- Cloud & Internet
- Cloud En Internet
- Computers
- Computer History
- Cord Cutting & Streaming
- Snoer Snijden En Streamen
- Onenigheid
- Disney +
- DIY
- Elektrische Voertuigen
- Readers
- Essentiële Zaken
- Uitleg
- Bij
- Gamen
- Algemeen
- Gmail
- Google Assistant & Google Nest
- Google Assistant & Google Nest
- Google Chrome
- Google Docs
- Google Drive
- Google Maps
- Google Play Store
- Google Spreadsheets
- Google Slides
- Google TV
- Hardware
- HBO Max
- Procedures
- Hulu
- Internet Slang & Afkortingen
- IPhone & IPad
- Kindle
- Linux
- Mac
- Onderhoud En Optimalisatie
- Microsoft Edge
- Microsoft Excel
- Microsoft Office
- Microsoft Outlook
- Microsoft Powerpoint
- Microsoft Teams
- Microsoft Word
- Firefox
- Netflix
- Nintendo Schakelaar
- Paramount +
- PC Gaming
- Pauw
- Fotografie
- Photoshop
- PlayStation
- Privacy & Security
- Privacy En Beveiliging
- Privacy En Veiligheid
- Artikel Roundups
- Programmeren
- Framboos Pi
- Roku
- Safari
- Samsung-telefoons En -tablets
- Samsung -telefoons En Tablets
- Slack
- Smart Home
- Snapchat
- Social Media
- Ruimte
- Spotify
- Tinder
- Probleemoplossen
- TV
- Video Games
- Virtuele Realiteit
- VPN
- Web Browsers
- Wifi & Routers
- Wifi & Routers
- Windows
- Windows 10
- Windows 11
- Windows 7
- Xbox
- YouTube En YouTube TV
- YouTube & YouTube TV
- Zoom
- Explainers