Forstå naturlig språkbehandling

Nettsteder og apper kan ha ulike bevegelige deler, inkludert frontendrekreativ, server-sidebehandling, APIer og datalagring. AI kan koble til noen av disse komponentene.
På forsiden kan du koble talekommandoer, chatbotgrensesnitt eller reaktive Webgl-kreative elementer. På bakenden bruker databasene intelligente algoritmer for å maksimere hastighet og analyse. APIer kan gi et lag av abstraksjon fra et bredt spekter av AI-funksjoner, fra spådommer til kollektiv trening.
Hvis du bare starter som en utvikler og trenger noen poeng, finn ut Hvordan lage en app , eller vi kan hjelpe deg med å velge hvilken Nettstedbygger , Web Hosting. Service og skylagring å bruke.
- Chatbots: Hva du trenger å vite.
Naturlig språk
Naturlig språkbehandling (NLP) fokuserer på samspillet mellom maskiner og menneskelige språk. Det er målet med NLP å behandle og analysere store mengder språkdata for å forbedre naturlig kommunikasjon mellom mennesker og maskiner. Dette feltet av AI inkluderer talegjenkjenning, forståelse språk og generering av naturlig språk. Vårt fokus vil være på forståelse av naturlig språk, prosessen med å analysere og bestemme betydningen eller hensikten med en tekst.
Det er flere konsepter som er felles for NLP:
- Oppdage språk - Forstå hvilket språk som brukes i teksten, er grunnleggende for å vite hvilke ordbøker, syntaks- og grammatikkregler som skal brukes i analyse.
- Entity Extraction - Identifisere nøkkelordene i setninger, hvor relevant eller fremtredende de er til den overordnede teksten og bestemme hva enhetene er, basert på trenings- eller kunnskapsbaser.
- Sentiment analyse - Vurdere det generelle nivået av "følelse" i en tekst. Er det generelt positivt eller negativt? Også sentiment relatert til hver enhet. Reviserer utsagnet positive følelser eller negative om "emnet"?
- Syntaktisk analyse - Forstå strukturen i teksten. Identifiser attributter som setninger, deler av tale (f.eks. Substantiv, verb), stemme, kjønn, stemning og tid.
- Innholdsklassifisering eller kategorisering - Organisering av innholdet i teksten i vanlige kategorier for å effektivt behandle dem. For eksempel er New York, London, Paris, München alle "steder" eller "byer".
Det er mange tekniske tilnærminger for å parse og behandle dataene. Uansett hvilket NLP-verktøy du bruker, må du takle de vanlige trinnene i parsing og analyse. Typisk er tekst skilt i logiske biter. Disse bitene analyseres mot utdannede data- eller kunnskapsbaser og tildelte verdier, vanligvis fra 0,0 til 1,0 for å gjenspeile nivået av tillit til analysen.
Googles naturlige språk API
Vi bruker det nye naturlige språket API utviklet av Google for denne opplæringen. Det er mange APIer tilgjengelig, men Googles har noen fine fordeler, inkludert cloud computing, hastighet, en utrolig stor brukerbase og maskinlæring. Googles søkemotorer og verktøy har brukt AI i årevis. Så du utnytter all den erfaringen og læringen ved å bruke sine offentlige tjenester.
APIer innlemme lett inn i et hvilket som helst prosjekt. Dette sparer mye tid mot håndkoding din egen NLP. Dens abstrakte avslappende API gjør at du kan integrere med nesten hvilket som helst språk du ønsker gjennom vanlige krølleanrop eller en av de mange SDKene som er tilgjengelige. Det er noen få triks for å få satt opp, men vi vil jobbe gjennom det ett steg om gangen.
Klikk på ikonet øverst til høyre for bildet for å forstørre det.
01. Opprett nytt Google Cloud-prosjekt
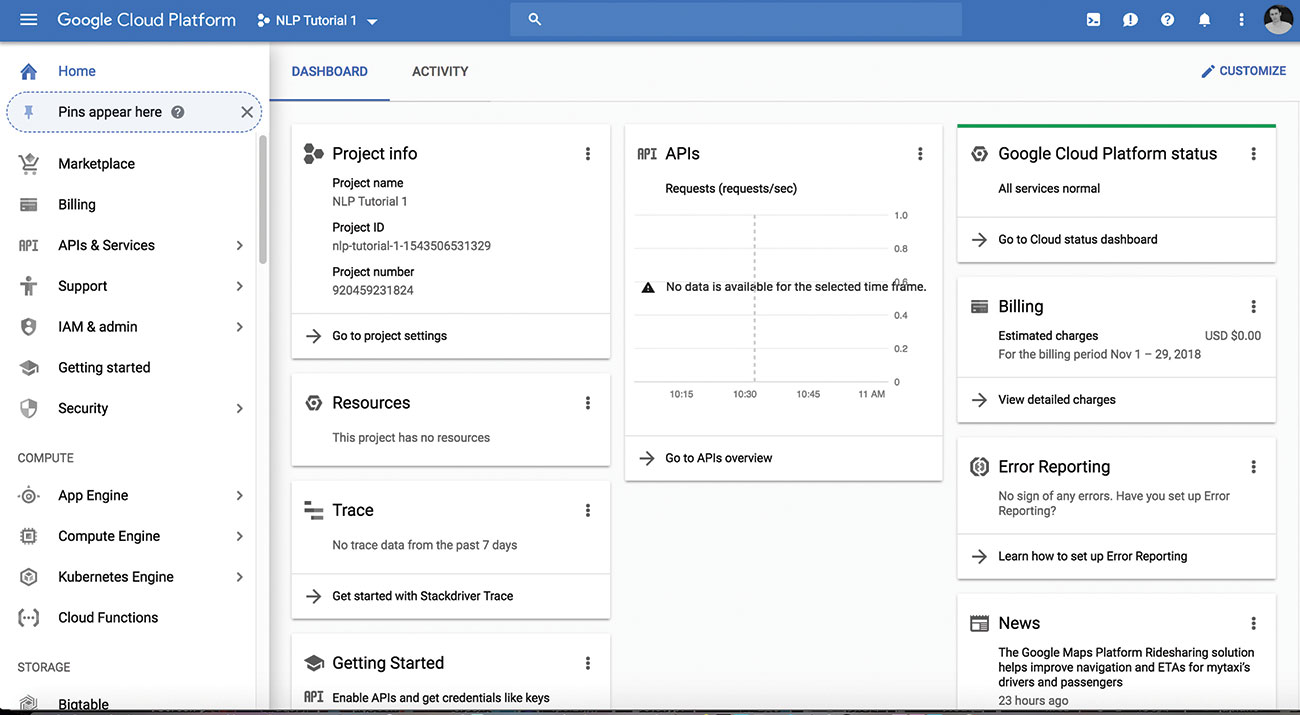
Gå til den Google Cloud Platform Console og opprett et nytt prosjekt eller velg en eksisterende for å jobbe med. Tjenesten er gratis å bruke til du begynner å lage et stort volum API-forespørsler. Du må kanskje knytte faktureringsinformasjon med kontoen når du aktiverer API, men dette er ikke ladet med lavt volum, og du kan fjerne tjenestene etter at du har gjort testet hvis du ønsker det.
02. Aktiver skyen nl
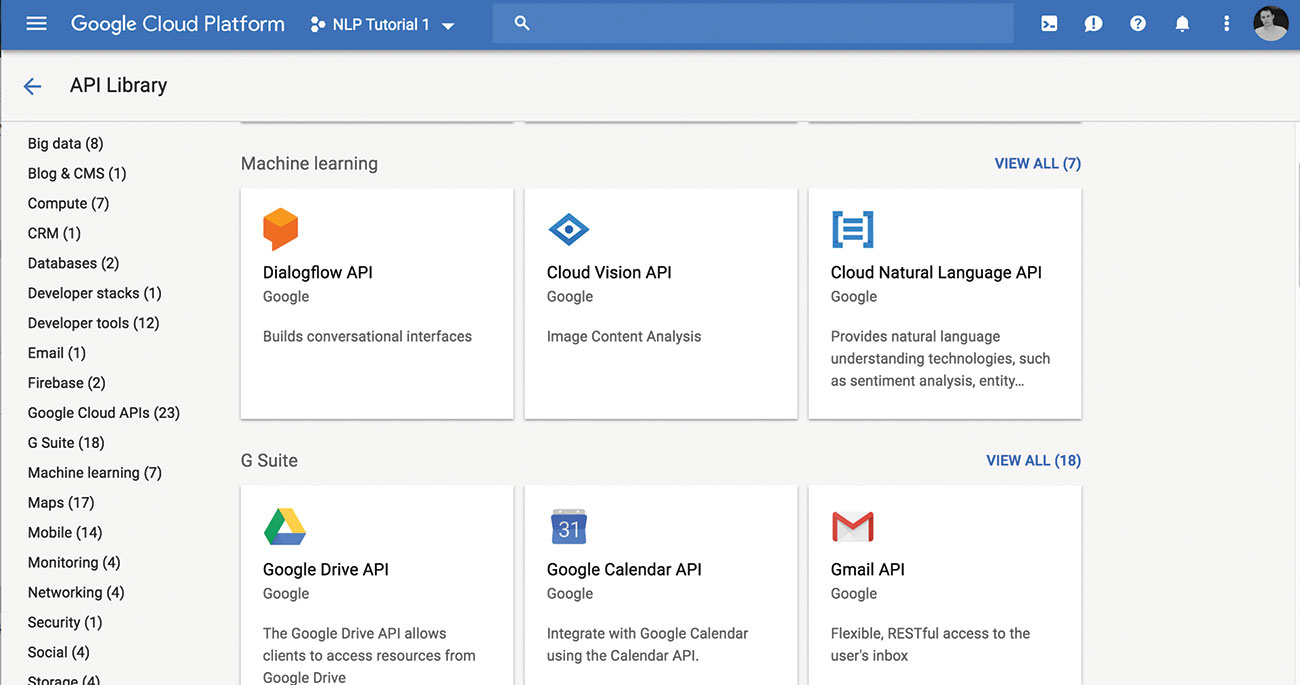
Bla til API Library og velg NL API. Når du har gjort det mulig, bør du se en liten grønn sjekk og meldingen 'API aktiverte' ved siden av den.
03. Opprett en servicekonto
Du må sette opp en Servicekonto for denne tjenesten. Siden vi skal sette opp bruk som en typisk tjeneste, er dette den beste praksisen. Det fungerer også best med godkjenningsflyt.
04. Last ned Privat Key
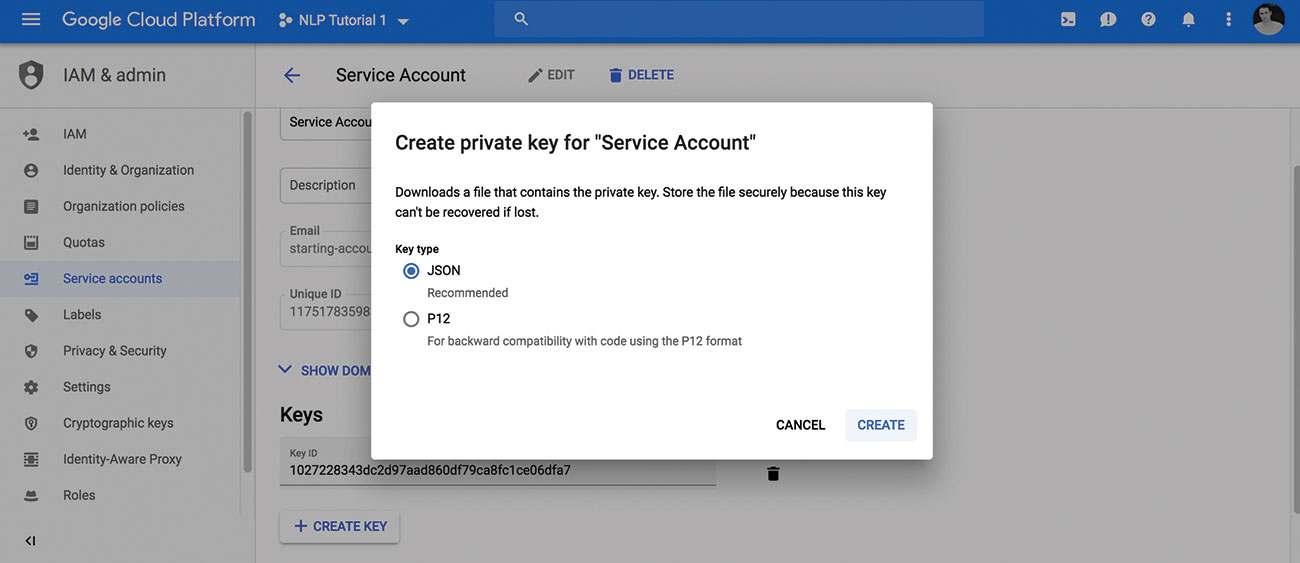
Når du har et prosjekt med API-aktivert og en servicekonto, kan du laste ned din private nøkkel som en JSON-fil. Legg merke til plasseringen av filen, slik at du kan bruke den i de neste trinnene.
Hvis du har noen problemer med de første få trinnene, er det en guide her Det hjelper, som slutter med nedlasting av JSON-nøkkelen.
05. Sett miljøvariabel
Deretter må du sette Google_application_credentials. Miljøvennlig variabel, så den kan nås av våre API-anrop. Dette peker på JSON-filen du nettopp lastet ned og sparer deg for å skrive stien hver gang. Åpne et nytt terminalvindu og bruk eksportkommandoen som så:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/username/Downloads/[file name].json"Erstatt den [filnavn] Med din private nøkkelfil og bruk banen til filen din.
På Windows kan du gjøre det samme via kommandolinjen, slik:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].json"Merk: Hvis du lukker terminal- eller konsollvinduet, må du kanskje kjøre det igjen for å angi variabelen.
06. Ringe til API
Nå er du klar til å grave til å bruke API og se NLP i aksjon. Du bruker krøllen til å gjøre raske tester av API. Du kan også bruke denne metoden fra koden din.
Curl-forespørsler kan gjøres på de fleste språk, noe som betyr at du kan ringe anropene direkte i kommandolinjen eller tildele resultatet til en variabel på språket du ønsker. Se her For noen raske tips om bruk av krøll.
La oss prøve en testforespørsel, med en enkel setning. Vi løper det gjennom analyse endepunkt.
I ditt terminal- eller kommandolinjegrensesnitt, skriv inn følgende kommando:
Curl -X Post \
-H "Autorisasjon: Bærer" $ (GCloud Auth Application-standard Print-Access-Token) \
-H "Innholdstype: Søknad / JSON; Charset = UTF-8" \
--Data "{
'dokument':{
'Type': 'Plain_text',
'Innhold': 'John McCarthy er en av de grunnleggende fedre av kunstig intelligens.'
},
'EncodingType': 'UTF8'
} "" https://language.googleapis.com/v1/documents:analyzeentities"Du bør se et JSON-resultat etter å ha gjennomført. Du kan bli bedt om første gang du bruker dette til å aktivere API eller tillate tilgang. Du kan svare på "ja" eller "y" til den aktuelle spørsmålet, og det bør returnere JSON etter det.
Det vil returnere en rekke oppføringer, som ligner på de som denne første for oppføringen "John McCarthy".
{
"Navn": "John McCarthy",
"Type": "Person",
"Metadata": {
"Wikipedia_url": "https://en.wikipedia.org/wiki/john_mccarthy_(computer_scientist)",
"Midt": "/ m / 01svfj"
},
"Salience": 0.40979216,
"Nevnte": [
{
"Tekst": {
"Innhold": "John McCarthy",
"BeginToffset": 0
},
"Type": "riktig"
}
]
}, Merk: Du kan bruke en URL i stedet for innholdstekst i innholdsparameteren til krøllenklæringen.
Du kan se i prøve-enhetsoppføringen, Navn identifisert og den type , som AI bestemt er en PERSON . Det fant også en Wikipedia-kamp for Navn og returnerte det. Dette kan være nyttig, siden du kan bruke denne nettadressen som innholdet for en annen forespørsel til API og få enda flere enheter og informasjon om denne. Du kan også se salience. Verdi på 0,4, som indikerer en betydelig relativ betydning av enheten i sammenheng med teksten vi oppgav. Du kan også se den er riktig identifisert som ORDENTLIG , som refererer til substantivet type (et riktig substantiv), så vel som hvor mange forekomster (nevner) i enheten i teksten.
API vil returnere verdier for alle de viktigste enhetene i teksten du sender inn. Dette alene kan være ekstremt nyttig for behandling av hva en bruker kan kommunisere til appen din. Uansett hva setningen inneholdt, er det en god sjanse for at det handler om personen, John McCarthy, og vi kan se opp litt informasjon for brukeren basert på dette alene. Vi kan også svare på en måte som gjenspeiler vår forståelse av denne utsagnet refererer til en person.
Du kan fortsette å bruke denne metoden for å teste samtalene vi bruker. Du kan også sette opp lokal SDK på et språk du foretrekker og helt ut i appen din.
07. Installer klientbibliotek
Tid til å lage en enkel webbasert app for å demonstrere hvordan man integrerer API i prosjekter.
For NLP-apper er det vanlig å bruke python eller node. For å vise allsidigheten til å bruke APIene, bruker vi PHP SDK. Hvis du ønsker å finjustere koden til et annet språk, er det en stor ressurs for SDK her .
Start med å sørge for at du har en prosjektmappe satt opp på din lokale eller eksterne server. Hvis du ikke allerede har det, få komponist og installer på prosjektmappen din. Du kan ha komponist allerede installert globalt, og det er bra også.
Kjør Følgende komponistkommando for å installere leverandørfilene til prosjektet ditt:
php -r "Kopier (" https://getcomposer.org/Installer "," komponist-setup.php ");"
php -r "if (hash_file ( 'SHA384', 'Oser-setup.php') === '93b54496392c06277467 0ac18b134c3b3a95e5a5e5 c8f1a9f115f203b75bf9a129d5 daa8ba6a13e2cc8a1da080 6388a8') {echo 'installasjons bekreftet';} else {echo 'installasjons fordervet'; unlink (' komponist-setup.php ');} ekko php_eol; "
php komponist-setup.php
php -r "unlink (" komponist-setup.php ");"
PHP Composer.phar krever Google / Cloud-Language Komponist gjør en leverandørmappe i prosjektmappen din og installerer alle avhengighetene for deg.
Hvis du sitter fast, og vil bruke PHP, kan du sjekke ut denne ressursen på installere komponist .
08. Opprett en ny fil
Hvis du følger med i PHP, opprett en ny PHP-fil i prosjektmappen din. Sett den opp, men du liker, men ta med et enkelt HTML-skjema for raskt å sende inn tekst gjennom.
Her er et eksempel PHP-fil med skjemaet:
& lt;! DOCTYPE HTML & GT;
& lt; html & gt;
& lt; head & gt;
& lt; title & gt; Net - NLP Tutorial & lt; / title & gt;
& lt; / head & gt;
& lt; body & gt;
& lt; form & gt;
& lt; p & gt; & lt; input type = 'Text' id = "innhold" navn = "innhold" plassholder = "Hva kan jeg analysere?" / & gt; & lt; / p & gt;
& lt; P & GT; 'noT; Input Type =' Send 'Name =' Send 'ID =' Send 'Value =' Analyser '> & GT;
& lt; / form & gt;
& lt; div class = "resultater" & gt;
& lt;? php
// PHP-koden går her //
hvis (tomt ($ _ får ['innhold'])) {die (); }
$ Content = $ _get ['innhold'];
? & gt;
& lt; / div & gt;
& lt; / body & gt;
& lt; / html & gt; Koden inneholder en grunnleggende HTML-fil med et skjema, sammen med en plassholder for din PHP-kode. Koden starter ved å bare sjekke for eksistensen av innholdsvariabelen (sendt fra skjemaet). Hvis det ikke er sendt ennå, går det bare og gjør ingenting.
09. Gjør miljøvariabelen
I likhet med trinnet vi tidligere gjorde når du bruker kommandolinjens krølleanrop, må vi sette Google_application_credentials. variabel. Dette er viktig for å få det til å autentisere.
I PHP bruker vi Putenv. kommandoen for å angi en miljøvariabel. Autentiseringen opprettet av SDK utløper, så du må inkludere dette i koden din for at den skal grip den og sette den hver gang.
Legg til denne koden neste i PHP-koden din:
PutenV ('Google_application_credentials = / Brukere / Richardmattka / Nedlastinger / NLP Tutorial 1-1027228343dc.json'); Bytt ut banen og filnavnet som du gjorde før med din egen.
10. Initialiser biblioteket
Deretter legger du til biblioteket og initialiserer LanguageClient. klasse i koden din. Legg til denne koden ved siden av PHP-koden din:
krever __dir__. '/Vendor/autoload.php';
Bruk Google \ Cloud \ Language \ LanguageClient;
$ ProjectId = 'NLP-Tutorial-1-1543506531329';
$ Language = Ny LanguageClient ([
'prosjektid' = & gt; $ Prosjektid
]); Start med å kreve leverandøren Autoload. Dette er lik i Python eller node hvis du trenger avhengigheter. Importere LanguageClient. neste, for å gjøre bruk av klassen. Definer din Prosjektet . Hvis du ikke er sikker på hva dette er, kan du se opp i din GCP-konsoll, hvor du opprinnelig setter opp prosjektet. Til slutt, opprett en ny LanguageClient. objekt ved hjelp av din Prosjektet og tilordne det til $ språk variabel.
11. Analyser enhetene
Nå er du klar til å begynne å bruke NLP API i koden din. Du kan sende innholdet fra skjemaet til API og få resultatet. For nå vil du bare vise resultatet som JSON til skjermen. I praksis kan du vurdere resultatene og bruke dem på en måte du ønsker. Du kan svare på brukeren basert på resultatene, se opp mer informasjon eller utfør oppgaver.
For å gjenoppta, vil Entity-analysen returnere informasjon om "hva" eller "tingene som finnes i teksten.
$ resultat = $ språk- & gt; analyse ($ innhold);
foreach ($ resultat- & gt; enheter () som $ e) {
ekko "& lt; div klasse =" resultat "& gt;";
$ resultat = json_encode ($ E, json_pretty_print);
ekko $ resultat;
ekko "& lt; / div & gt;";
} Denne koden sender innholdet fra det innleverte skjemaet til analyse sluttpunkt og lagrer resultatet i $ resultat variabel. Deretter itererer du over listen over enheter returnert fra $ resultat- & gt; enheter () . For å gjøre det litt mer lesbart, kan du formatere det som JSON før du skriver ut på skjermen. Igjen, dette er bare et eksempel for å vise deg hvordan du bruker den. Du kan behandle det og reagere på resultatene, men du trenger.
12. Analyser følelsen
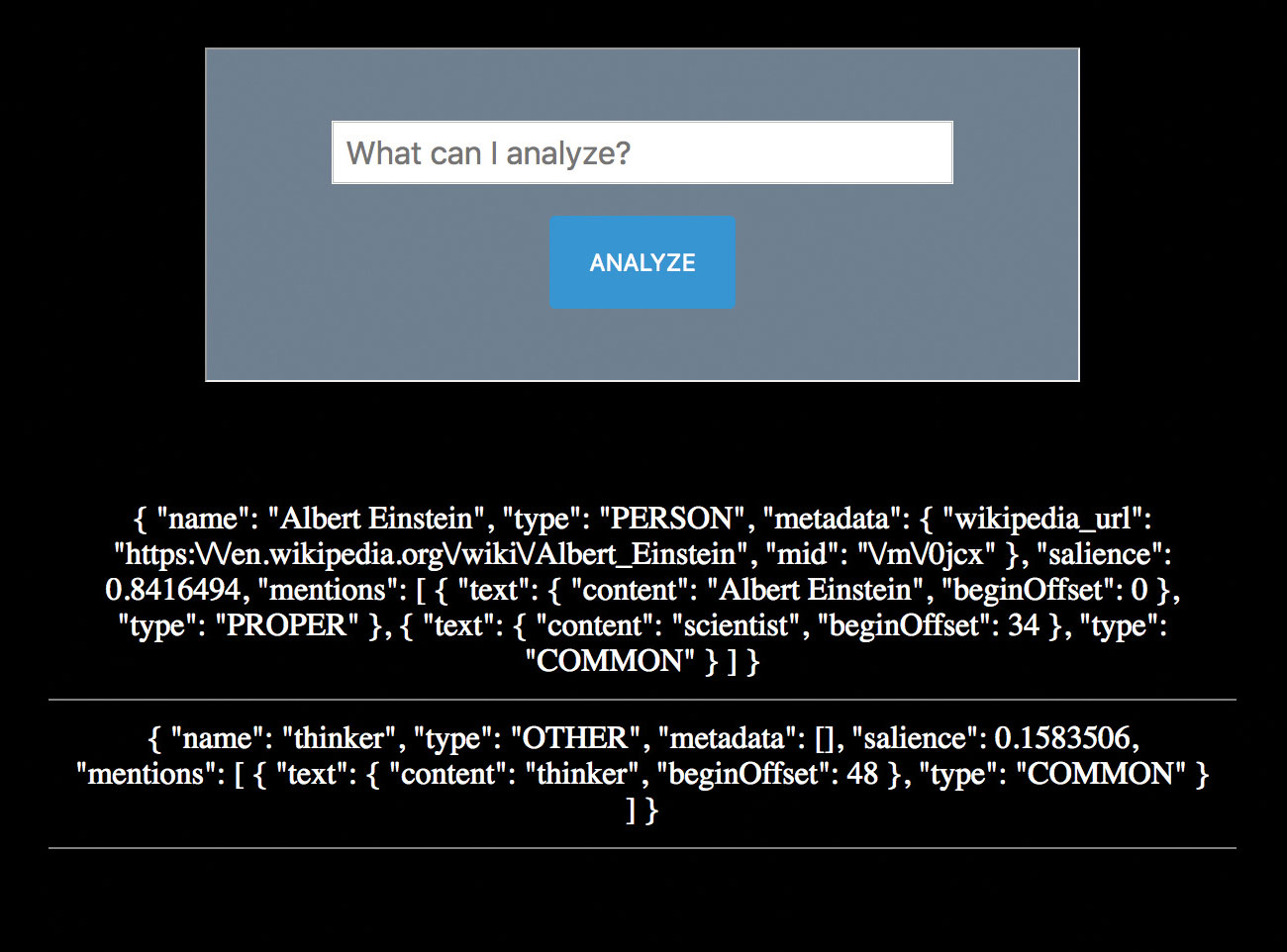
I stedet for å vite "hva" av innholdet, kan det også være verdifullt å kjenne følelsen. Hvordan føler brukeren? Hvordan føler de seg om enhetene i deres kommunikasjon?
Oppdater koden for å bruke analyseTriceSentiment. endepunkt. Dette vil vurdere både enhetene som før, men også returnere en sentimentpoeng for hver enkelt.
$ resultat = $ språk- & gt; analyseTitysentiment ($ innhold);
foreach ($ resultat- & gt; enheter () som $ e) {
ekko "& lt; div klasse =" resultat "& gt;";
$ resultat = json_encode ($ E, json_pretty_print);
ekko $ resultat;
ekko "& lt; / div & gt;";
} Testing med innholdet via skjemaet, "Star Wars er den beste filmen av all tid.", Du vil se et resultat som ligner på dette:
{"Navn": "Star Wars", "Type": "Work_of_Art", "Metadata": {"midt": "\ / m \ / 06mmr", "wikipedia_url": "https: \ / \ / en.wikipedia.org \ / wiki \ / star_wars "}," Salience ": 0.63493526," nevner ": [{" Text ": {" Content ":" Star Wars "," BeginToffset ": 0}," Type " : "Riktig", "Sentiment": {"Magnitude": 0,6, "Score": 0,6}}], "Sentiment": {"Magnitude": 0.6, "Score": 0.6}}
{"Navn": "Movie", "Type": "Work_of_Art", "Metadata": [], "Salience": 0.36506474, "Nevner": [{"Text": {"Content": "Movie", " BeginToffset ": 22}," Type ":" Vanlig "," Sentiment ": {" Magnitude ": 0,9," Score ": 0,9}}]," Sentiment ": {" Magnitude ": 0.9," Score ": 0,9 }} Dette viser en positiv følsomhetspoeng av betydelig verdi. Ikke bare vet du nå nøkkelordene brukeren kommuniserer, men også hvordan de føler seg om det. Appen din kan reagere riktig basert på disse dataene. Du har en klar identifisering av "Star Wars" som det primære emnet med høy salience. Du har en Wikipedia-lenke for å få mer informasjon hvis du vil kjøre den nettadressen tilbake gjennom samme API-anrop. Du vet også at brukeren føler seg positiv om det. Du kan til og med se uttalelsen vekter den positive følelsen på kvaliteten på den som en film. Veldig kult.
Avskjeds tanker
Prøv å eksperimentere med andre endepunkter. Spesifikt, sjekk ut analyseresyntax. og ClassifyText. endepunkter. Disse gir deg enda flere deler av taledata og klassifisering av innholds-enhetene.
Denne artikkelen ble opprinnelig publisert i utgave 315 av nett , verdens bestselgende magasin for webdesignere og utviklere. Kjøp problem 315 her eller Abonner her .
Relaterte artikler:
- 7 store tekniske trender som designere trenger å vite akkurat nå
- Slik designer du en chatbot-opplevelse
- 5 counterintuitive konverterings triks
hvordan - Mest populære artikler

Bruk WordPress som en hodeløs CMS
hvordan Feb 3, 2026[1. 3] Jeg hørte først om den hodeløse CMS-tilnærmingen i en snakk jeg så fra Twin Cities Drupal. Jeg likte ideen om en adski..

Hvordan lage en fotorealistisk romscene
hvordan Feb 3, 2026[1. 3] Vil du vite hvordan du lager en realistisk 3D-arkitektonisk fly gjennom, men er ikke sikker på hvor du skal fokusere på d..

Lag et fliser materiale i stoffdesigner
hvordan Feb 3, 2026[1. 3] Stoffdesigner er et utmerket verktøy for å skape alle slags materialer for din 3D Art. . Her skal jeg fork..

Slik bygger du et chatbotgrensesnitt
hvordan Feb 3, 2026[1. 3] I midten av 2000-tallet fikk virtuelle agenter og kundeservice chatbots mye adulation, selv om de ikke var veldig konversas..

Slå bilder til 3D-animasjoner med Photoshop
hvordan Feb 3, 2026[1. 3] Vi har alle en stor butikk med minner tatt som bilder, og det er flott å være i stand til å reminisce. Men hva om du kun..

Lag utsmykkede fliser i substansdesigner
hvordan Feb 3, 2026[1. 3] Side 1 av 2: Design og tekstur 3D Gulvfliser Design og tekstur 3D G..

Hvordan forbedre ytelsen til e-handelsplasser
hvordan Feb 3, 2026[1. 3] Tammy Everts. vil gi en presentasjon om sammenhengen mellom design, ytelse og konverteringsfrek..

Bygg komplekse layouter med postcss-flexbox
hvordan Feb 3, 2026[1. 3] FlexBox er et flott verktøy for å redusere CSS-oppblåst, og har litt sukker bygget inn for å håndtere ting som kildeor..
Kategorier
- AI Og Maskinlæring
- AirPods
- Amazon
- Amazon Alexa & Amazon Echo
- Amazon Alexa & Amazon Echo
- Amazon Brann TV
- Amazon Prime Video
- Android
- Android Telefoner Og Tavle
- Android -telefoner Og Nettbrett
- Android TV
- Apple
- Apple App Store
- Apple HomeKit & Apple HomePod
- Apple Music
- Apple TV
- Apple Watch
- Apps & Web Apps
- Apper Og Webapper
- Lyd
- Chrome & Chrome OS
- Chromebook & Chrome OS
- Chrome
- Cloud & Internet
- Sky Og Internett
- Sky Og Internett
- Datamaskiner
- Computer History
- Ledningen Cutting & Streaming
- Ledning Og Streaming
- Splid
- Disney +
- DIY
- Elektriske Kjøretøyer
- Lesebrett
- Essentials
- Forklarere
- Spill
- Generelt
- Gmail
- Google Assistant Og Google Nest
- Google Assistant & Google Nest
- Google Chrome
- Google Docs
- Google Disk
- Google Maps
- Google Play-butikken
- Google Blad
- Google Slides
- Google TV
- Maskinvare
- HBO Maks
- Hvordan
- Hulu
- Internet Slang Og Forkortelser
- IPhone Og IPad
- Tenne
- Linux
- Mac
- Vedlikehold Og Optimalisering
- Microsoft Edge
- Microsoft Excel
- Microsoft Office
- Microsoft Outlook
- Microsoft PowerPoint
- Microsoft Lag
- Microsoft Word
- Mozilla Firefox
- Netflix
- Nintendo Switch
- Paramount +
- PC Gaming
- Peacock
- Foto
- Photoshop
- PlayStation
- Personvern Og Sikkerhet
- Personvern Og Sikkerhet
- Personvern Og Sikkerhet
- Product Roundups
- Programmering
- Bringebær Pi
- Roku
- Safari
- Samsung-telefoner Og Tavle
- Samsung -telefoner Og Nettbrett
- Slack
- Smart Home
- Snapchat
- Sosiale Medier
- Rom
- Spotify
- Tinder
- Feilsøking
- TV
- Video Games
- Virtuell Virkelighet
- VPN
- Nettlesere
- Wifi Og Routere
- Wifi & Ruters
- Windows
- Windows 10
- Windows 11
- Windows 7
- Xbox
- YouTube Og YouTube TV
- YouTube Og YouTube TV
- Zoom
- Explainers