Înțelegerea procesării limbii naturale

Site-urile web și aplicații pot avea diferite părți în mișcare, inclusiv creativul frontal, procesarea serverului, API-uri și stocarea datelor. AI poate conecta oricare dintre aceste componente.
Pe capătul frontal, puteți conecta comenzi vocale, interfețe chatbot sau elemente creative WebGL reactive. Pe partea din spate, bazele de date utilizează algoritmi inteligenți pentru a maximiza viteza și analiza. API-urile pot oferi un strat de abstractizare dintr-o gamă largă de funcții AI, de la previziuni la formarea colectivă.
Dacă începeți doar ca un dezvoltator și aveți nevoie de niște indicii, aflați Cum se face o aplicație , sau vă putem ajuta să alegeți care Builder de site-uri web , web hosting serviciu și Stocare in cloud a folosi.
- Chatbots: Ce trebuie să știți.
Limba naturală
Prelucrarea limbajului natural (NLP) se concentrează asupra interacțiunilor dintre mașini și limbile umane. Este obiectivul NLP de a procesa și de a analiza cantități mari de date lingvistice pentru a îmbunătăți comunicarea naturală între oameni și mașini. Acest câmp al AI include recunoașterea vorbirii, înțelegerea limbajului și generarea limbajului natural. Accentul nostru va fi în înțelegerea limbii naturale, procesul de analiză și determinare a semnificației sau intenției unui text.
Există mai multe concepte comune NLP:
- Detectarea limbajului - înțelegerea care limba este utilizată în text este fundamentală pentru a cunoaște dicționarele, sintaxa și regulile de gramatică în analiză.
- Extracția entității - Identificarea cuvintelor cheie în fraze, cât de relevante sau importante sunt la textul general și determinând ceea ce entitățile sunt, pe baza bazelor de formare sau de cunoștințe.
- Analiza sentimentelor - evaluarea nivelului general de "sentiment" într-un text. Este, în general, pozitiv sau negativ? De asemenea, sentimentul legat de fiecare entitate. Declarația reflectă sentimentele pozitive sau cele negative despre "subiect"?
- Analiza sintactică - Înțelegerea structurii textului. Identificați atribute precum propozițiile, părțile de vorbire (de exemplu, substantiv, verb), voce, sex, starea de spirit și tensionat.
- Clasificarea conținutului sau clasificarea conținutului - organizarea conținutului textului în categorii comune pentru a le procesa mai eficient. De exemplu, New York, Londra, Paris, München sunt toate "locațiile" sau "orașele".
Există numeroase abordări tehnice la parsare și prelucrare a datelor. Indiferent de instrumentul NLP pe care îl utilizați, va trebui să abordă pașii obișnuiți de parsare și analiză. În mod obișnuit, textul este separat în bucăți logice. Aceste bucăți sunt analizate împotriva datelor instruite sau baze de cunoștințe și valori atribuite, de obicei de la 0,0 la 1.0 pentru a reflecta nivelul de încredere în analiză.
Limbajul natural al Google API
Vom folosi noul API de limbă naturală dezvoltat de Google pentru acest tutorial. Există numeroase API-uri disponibile, dar Google are unele avantaje frumoase, inclusiv cloud computing, viteză, o bază de utilizatori incredibil de mare și învățare la mașină. Motoarele și instrumentele de căutare ale Google au folosit AI de ani de zile. Deci, acționați toată experiența și învățarea prin utilizarea serviciilor sale cu fața în mod public.
API-urile încorporează cu ușurință în orice proiect. Acest lucru economisește mult timp versus codarea mâinilor dvs. NLP. API-ul de odihnă abstracționat vă permite să vă integrați cu aproape orice limbă pe care doriți să o utilizați prin apeluri comune CURL sau unul dintre numeroasele SDK-uri disponibile. Există câteva trucuri pentru a se înființa, dar vom lucra printr-un pas la un pas la un moment dat.
Faceți clic pe pictograma din partea dreaptă de sus a imaginii pentru ao mări.
01. Creați un nou proiect Google Cloud
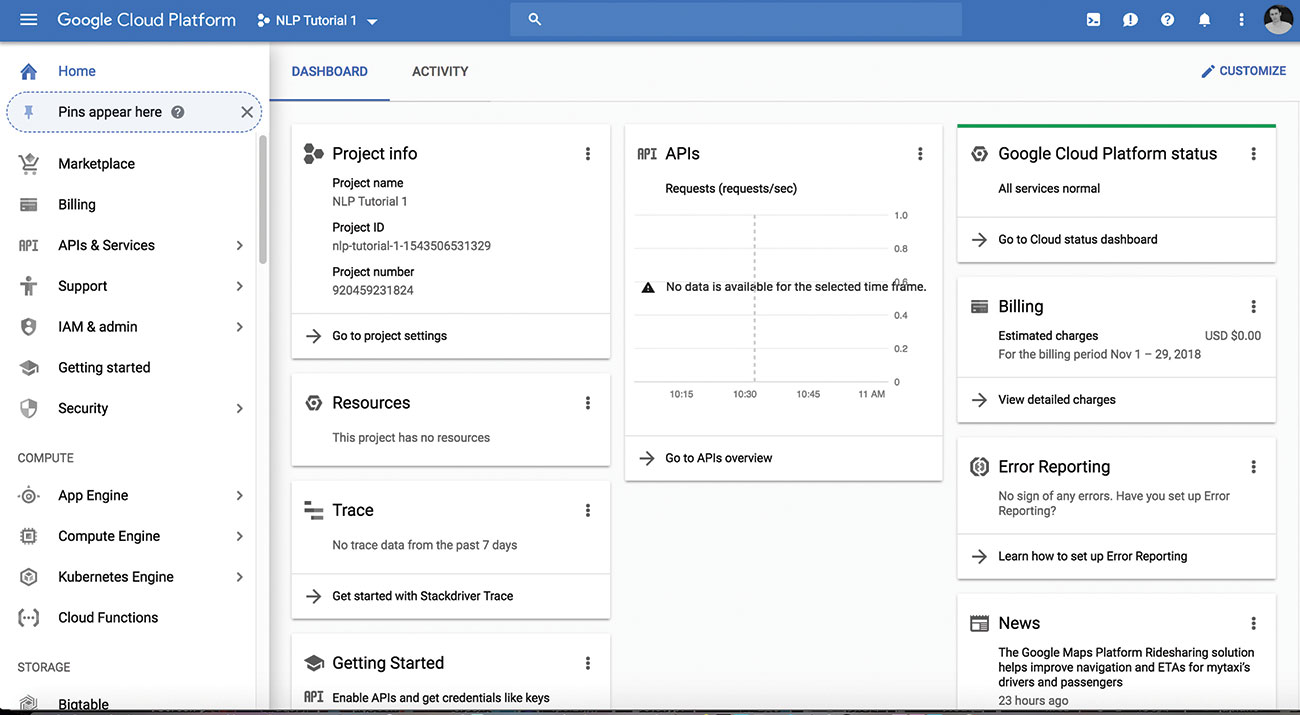
Du-te la. Consola de platformă Google Cloud și creați un nou proiect sau selectați unul existent cu care lucrați. Serviciul este liber să se utilizeze până când începeți să efectuați un volum mare de solicitări API. Este posibil să aveți nevoie să asociați informațiile de facturare cu contul atunci când activați API, dar acest lucru nu este încărcat la volum redus și puteți elimina serviciile după ce ați terminat testarea dacă doriți.
02. Activați nl nl
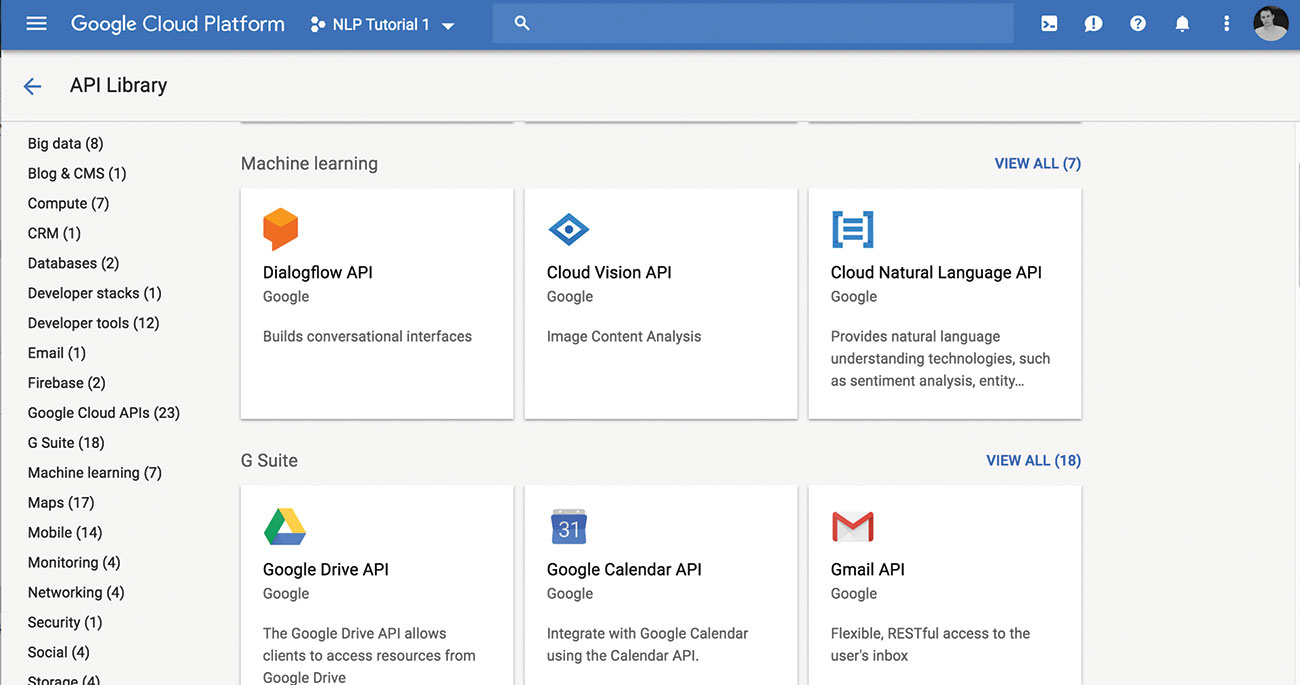
Răsfoiți la. Biblioteca API și selectați API NL. Odată activată, ar trebui să vedeți un mic verificare verde și mesajul "API-ul a permis" de lângă el.
03. Creați un cont de servicii
Va trebui să configurați a Contul de serviciu pentru acest serviciu. Din moment ce vom configura o utilizare ca un serviciu tipic, aceasta este cea mai bună practică. De asemenea, funcționează cel mai bine cu fluxul de autentificare.
04. Descărcați cheia privată
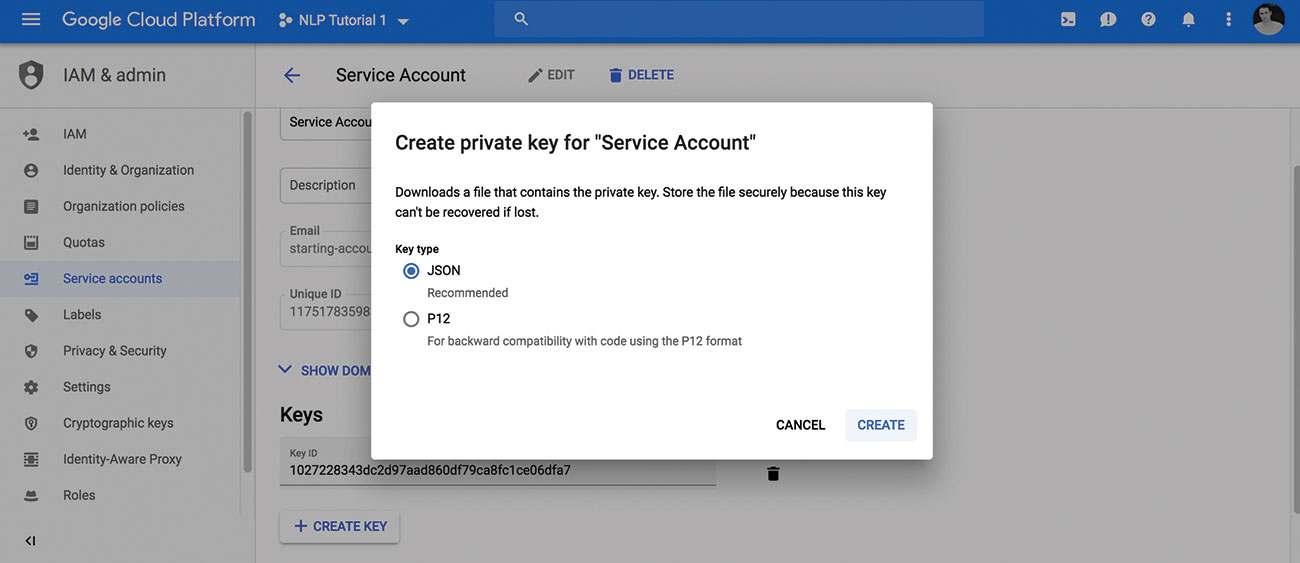
Odată ce aveți un proiect cu API activat și un cont de servicii, puteți descărca cheia dvs. privată ca fișier JSON. Luați notă de locația fișierului, astfel încât să o puteți utiliza în pașii următori.
Dacă aveți probleme cu primii câțiva pași, există un ghid Aici Asta ajută, care se termină cu descărcarea cheii JSON.
05. Setați variabila de mediu
Apoi, trebuie să setați Google_application_redențiales. Variabila de mediu, astfel încât aceasta poate fi accesată prin apelurile noastre API. Acest lucru indică fișierul JSON pe care tocmai l-ați descărcat și vă salvează că trebuie să introduceți calea de fiecare dată. Deschideți o nouă fereastră terminală și utilizați comanda de export, cum ar fi:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/username/Downloads/[file name].json"Inlocuieste [nume de fișier] Cu fișierul dvs. cheie privat și utilizați calea către fișierul dvs.
Pe Windows puteți face același lucru prin linia de comandă, astfel:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].json"NOTĂ: Dacă închideți fereastra terminalului sau a consolei, este posibil să fie necesar să rulați din nou pentru a seta variabila.
06. Faceți un apel către API
Acum sunteți gata să vă saprați să utilizați API-ul și să vedeți NLP în acțiune. Veți folosi curl pentru a efectua teste rapide ale API-ului. De asemenea, puteți utiliza această metodă din codul dvs.
Cererile de curl pot fi făcute în cele mai multe limbi, ceea ce înseamnă că puteți efectua apelurile direct în linia de comandă sau puteți atribui rezultatul unei variabile în limba dorită. Uite aici Pentru câteva sfaturi rapide despre utilizarea curlului.
Să încercăm o cerere de test, cu o propoziție simplă. O vom conduce prin Analinozități punct final.
În interfața de linie terminală sau de comandă, introduceți următoarea comandă:
curl -x post \
-H "Autorizare: Purtător" $ (GCLOUD Auth Application-implicit Imprimare-token) \
-H "tip de conținut: aplicație / json; charset = utf-8" \
--date "{
'document':{
"Tip": "simplu_text",
"Conținut": "John McCarthy este unul dintre părinții fondatori ai inteligenței artificiale".
},
"EncodingType": "UTF8"
} "" https://language.googleapis.com/v1/documents:analyzeententitatile"Ar trebui să vedeți un rezultat JSON după executarea. Puteți fi solicitat prima dată când utilizați acest lucru pentru a activa API-ul sau permite accesul. Puteți răspunde "da" sau "y" la acel prompt și ar trebui să returneze JSON după aceea.
Acesta va returna o gamă de intrări, similare cu cele de ca aceasta prima pentru intrarea "John McCarthy".
{{{{{
"Nume": "John McCarthy",
"Tip": "persoană",
"metadate": {
"wikipedia_url": "https://ro.wikipedia.org/wiki/john_mccarthy_(computer_scientist)",
"MID": "/ m / 01SVFJ"
},
"Salience": 0.40979216,
"Mențiuni":
{
"text": {
"Conținut": "John McCarthy",
"Începător": 0
},
"Tip": "Potrivit"
}
]
}, Notă: Ați putea utiliza o adresă URL în loc de text de conținut în parametrul de conținut al instrucțiunii CURL.
Puteți vedea în lista entității de probă, Nume identificate și tip , pe care a determinat AI este a PERSOANĂ . De asemenea, a găsit un meci Wikipedia pentru Nume și a revenit asta. Acest lucru poate fi util, deoarece ați putea folosi acea adresă URL ca fiind conținutul pentru oa doua solicitare către API și obțineți și mai multe entități și informații despre acest lucru. De asemenea, puteți vedea salienarea Valoarea la 0,4, ceea ce indică o importanță relativă semnificativă a entității în contextul textului pe care l-am furnizat. De asemenea, puteți vedea că este corect identificată ca În mod corespunzător , care se referă la tipul substantivului (un substantiv adecvat), precum și cât de multe apariții (mențiuni) ale entității din text.
API-ul va returna valorile pentru toate entitățile cheie din textul pe care îl trimiteți. Numai acest lucru poate fi extrem de util pentru procesarea a ceea ce un utilizator poate fi comunicat cu aplicația dvs. Indiferent de ceea ce conținea propoziția, există o șansă bună în care este vorba despre persoana, John McCarthy, și am putea căuta câteva informații pentru utilizatorul pe baza acestui lucru singur. Putem să răspundem, de asemenea, într-un mod care să reflecte înțelegerea noastră Această afirmație se referă la o persoană.
Puteți continua să utilizați această metodă pentru a testa apelurile pe care le vom utiliza. De asemenea, puteți configura SDK local într-o limbă pe care o preferați și întregi în aplicația dvs.
07. Instalați biblioteca clientului
Este timpul să faceți o aplicație simplă bazată pe web pentru a demonstra modul de integrare a API în proiecte.
Pentru aplicațiile NLP este obișnuit să utilizați Python sau Nod. Pentru a arăta versatilitatea utilizării API-urilor, vom folosi SDK-ul PHP. Dacă doriți să modificați codul într-o altă limbă, există o mare resursă a SDKS Aici .
Începeți prin asigurarea că aveți un folder de proiect configurat pe serverul local sau la distanță. Dacă nu aveți deja, obțineți compozitor și instalați în dosarul dvs. de proiect. Este posibil să aveți deja compozitor deja instalat la nivel global și și asta este bine.
Rulați următoarea comandă compozitor pentru a instala fișierele furnizorului în proiectul dvs.:
PHP-R "Copie (" https://getocposer.org/installer "," compozitor-setup.php ");"
php -r „if (hash_file ( 'sha384', 'compozitor-setup.php') === '93b54496392c06277467 0ac18b134c3b3a95e5a5e5 c8f1a9f115f203b75bf9a129d5 daa8ba6a13e2cc8a1da080 6388a8') {echo 'Installer verificat';} else {echo 'Installer corupt'; unlink (“ compozitor-setup.php ');} Echo php_eol; "
PHP compozitor-setup.php
PHP -R "Unlink (" compozitor-setup.php ");"
PHP compozitor.phar necesită Limba Google / Cloud Compozitorul face un dosar furnizor în dosarul proiectului și instalează toate dependențele pentru dvs.
Dacă vă blocați să setați acest lucru și doriți să utilizați PHP, puteți verifica această resursă Instalarea compozitorului .
08. Creați un fișier nou
Dacă urmați în PHP, creați un nou fișier PHP din dosarul proiectului. Setați-o cu toate acestea doriți, dar includeți un formular HTML simplu pentru a trimite rapid textul.
Aici este un exemplu de fișier PHP cu forma:
& lt;! Doctype html & gt;
& lt; html & gt;
& lt; head & gt;
& lt; title & gt; NLP Tutorial & Lt; / Titlu & GT;
& lt; / head & gt;
& lt; corp & gt;
& Form & GT;
& Lt; P & gt; & Lt; Intrare Tip = 'Text' ID = "Conținut" Nume = "Conținut" Placeholder = "Ce pot analiza?" / & gt; / lt; / p & gt;
& lt; P & gt; & lt; Intrare Tip = 'Trimiteți "NAME =' Trimiteți" ID = "Trimiteți" valoarea = "analiza '& GT; / lt; / p & gt;
& lt; / form & gt;
& Lt; Div clasa = "rezultate" & gt;
& lt;? php
// Codul PHP merge aici //
dacă (gol ($ _ obține ["conținut"])) {Die (); }
$ content = $ _get ['content'];
? & gt;
& lt; / div & gt;
& lt; / corp & gt;
& lt; / html & gt; Codul include un fișier HTML de bază cu un formular, împreună cu un substituent pentru codul PHP. Codul începe prin verificarea simplă a existenței variabilei de conținut (trimisă din formular). Dacă nu se depune încă, iese doar și nu face nimic.
09. Faceți variabila de mediu
Similar cu pasul pe care l-am făcut anterior atunci când folosim apelul de linie de comandă, trebuie să stabilim Google_application_redențiales. variabil. Acest lucru este esențial pentru ao autentifica.
În PHP folosim putenv. pentru a seta o variabilă de mediu. Autentificarea creată de SDK expiră, deci trebuie să includeți acest lucru în codul dvs. pentru ao apuca și a seta de fiecare dată.
Adăugați acest cod în continuare în codul PHP:
Putenv ("Google_Application_Credentials = / Utilizatori / Richardttka / Downloads / NLP Tutorial 1-1027228343dc.json '); Înlocuiți calea și numele fișierului așa cum ați făcut înainte cu dvs..
10. Inițializați biblioteca
Apoi, adăugați biblioteca și inițializați-le Languagelient clasa din codul dvs. Adăugați acest cod de lângă secțiunea de cod PHP:
necesită __dir__. "/vendor/autolod.php";
Utilizați Google \ Cloud \ Limba \ LanguageClient;
$ proiectid = 'nlp-tutorial-1-1543506531329';
$ Limba = Noua limbă ([
"proiectid" = & gt; $ proiectid.
]); Începeți prin solicitarea vânzătorului Autoload. Acest lucru este similar în Python sau nod dacă aveți nevoie de dependențele dvs. Importați. Languagelient Apoi, pentru a utiliza clasa. Definiți-vă proiectid . Dacă nu sunteți sigur ce este, puteți să-l căutați în consola GCP, unde ați stabilit inițial proiectul. În cele din urmă, creați un nou Languagelient obiect folosind dvs. proiectid și atribuiți-o $ Limba variabil.
11. Analizați entitățile
Acum sunteți gata să începeți să utilizați API-ul NLP în codul dvs. Puteți trimite conținutul din formular la API și obțineți rezultatul. Deocamdată, veți afișa doar rezultatul ca JSON pe ecran. În practică, ați putea evalua rezultatele și le puteți folosi în orice fel doriți. Puteți răspunde utilizatorului pe baza rezultatelor, căutați mai multe informații sau executați sarcini.
Pentru a recapida, analiza entității va returna informații despre "ceea ce" sau "lucrurile" găsite în text.
$ rezultat = $ Limbă- & GT; Analuzele (conținut de $);
FOREAH ($ rezultat- & GT; entități () ca $ e) {
ECHO "& LT; DIV CLASS = 'REZULTAT" & GT;
$ rezultat = json_encode ($ e, json_pretty_print);
Echo $ rezultat;
ECHO "& LT; / DIV & GT;";
} Acest cod prezintă conținutul din formularul trimis la Analinozități punct final și stochează rezultatul în $ rezultat variabil. Apoi, iterați pe lista entităților returnate de la $ rezultat- & gt; entități () . Pentru a face puțin mai lizibil, îl puteți forma ca JSON înainte de a ieși pe ecran. Din nou, acesta este doar un exemplu pentru a vă arăta cum să îl utilizați. Ați putea procesa și reacționa la rezultatele totuși aveți nevoie.
12. Analizați sentimentul
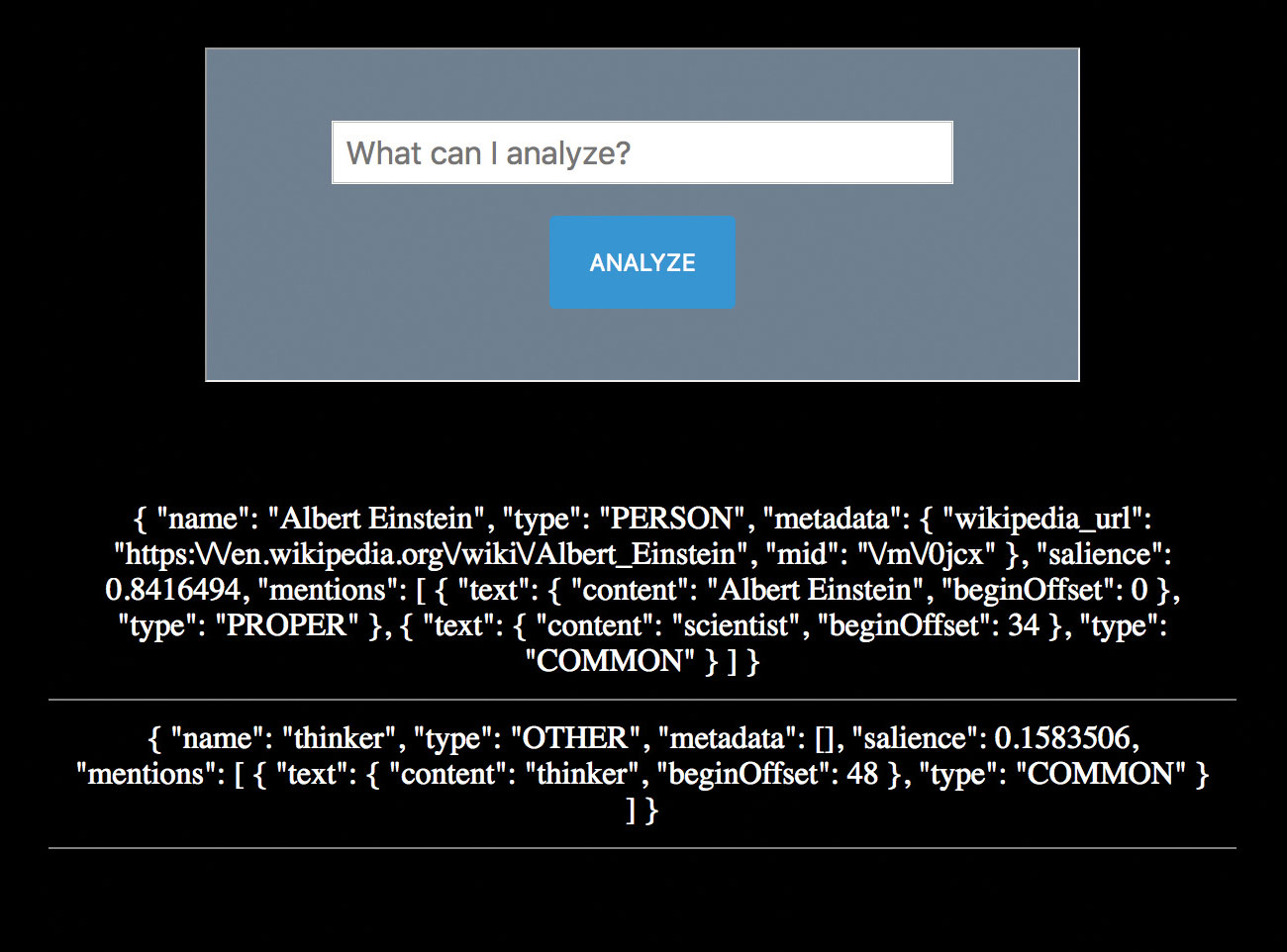
În loc să cunoașteți "ceea ce" al conținutului, poate fi, de asemenea, valoros să cunoaștem sentimentul. Cum se simte utilizatorul? Cum se simt despre entitățile din comunicarea lor?
Actualizați codul pentru a utiliza AnalinozenitySentitiment punct final. Acest lucru va evalua atât entitățile ca înainte, dar, de asemenea, returnează un scor de sentiment pentru fiecare.
$ rezultat = $ Limbă- & GT; AnalyzeenTitySentitiment ($ Conținut);
FOREAH ($ rezultat- & GT; entități () ca $ e) {
ECHO "& LT; DIV CLASS = 'REZULTAT" & GT;
$ rezultat = json_encode ($ e, json_pretty_print);
Echo $ rezultat;
ECHO "& LT; / DIV & GT;";
} Testarea cu conținutul prin formularul "Star Wars este cel mai bun film al tuturor timpurilor", veți vedea un rezultat similar cu acesta:
{"Nume": "Star Wars", "Tipul": "Work_of_art", "Metadate": {"MID": "Wikipedia_url": "HTTPS: \ / \ / en.wikipedia.org \ / wiki \ / star_wars "}," salience ": 0.63493526," mențiuni ": [" text ": {conținut": "Star Wars", "Beginoffset": 0}, "Tip" : "Potrivit", "Sentiment": {"Magnitudine": 0.6, "Scorul": 0.6}}], "Sentimentul": "Magnitudinea": 0.6, "Scorul": 0.6}}
{"Nume": "film", "tip": "work_of_art", "metadate": [], "salience": 0.36506474, "mențiuni": [text ": {" conținut ":" film " BEGOFFFSET ": 22}," Tip ":" Common "," Sentiment ": {" Magnitudine ": 0.9," Scor ": 0.9}}]," Sentiment ": {" Magnitudine ": 0.9," Scor ": 0.9 }} Acest lucru arată un scor pozitiv al sentimentului de valoare semnificativă. Nu numai că știți acum cuvintele cheie pe care utilizatorul le comunică, dar și cum se simt despre asta. Aplicația dvs. poate răspunde în mod corespunzător pe baza acestor date. Aveți o identificare clară a "războaielor star" ca subiectul primar cu salienare ridicată. Aveți un link Wikipedia pentru a apuca mai multe informații dacă doriți să rulați acea adresă URL înapoi prin același apel API. De asemenea, știți că utilizatorul se simte pozitiv despre el. Puteți vedea chiar și declarația ponderată sentimentului pozitiv asupra calității acestuia ca film. Foarte tare.
Gânduri despărțitoare
Încercați să experimentați alte obiective finale. În mod specific, verificați Analyzyntax. și ClasificaText. puncte finale. Acestea vă oferă și mai multe părți ale datelor de vorbire și clasificarea entităților de conținut.
Acest articol a fost publicat inițial în numărul 315 din net , cea mai bună revistă din lume pentru designeri și dezvoltatori web. Cumpărați problema 315 aici sau Abonați-vă aici .
Articole similare:
- 7 tendințe uriașe de tehnologie pe care designerii trebuie să le cunoască chiar acum
- Cum de a proiecta o experiență chatbot
- 5 trucuri de conversie contraintuitive
să - Cele mai populare articole

Construiți un chat-chat alimentat cu AI
să Jan 29, 2026Inteligența artificială (AI) ne permite să creăm noi modalități de a privi problemele existente, de la regândirea strategi..

Începeți cu Redux Thunk
să Jan 29, 2026Statul este o mare parte a unei aplicații reactive, motiv pentru care Redux este asociată cu ea. Aceste date provin adesea dint..

Construiți o pagină animată de aterizare a ecranului
să Jan 29, 2026Pagina dvs. de aterizare este un element crucial în dvs. Layout-ul site-ului . Este prima ocazie reală pe care t..

Iluminează lucrul 3D cu lumini de cupolă
să Jan 29, 2026Utilizarea luminilor Dome a fost una dintre cele mai mari progrese în crearea CGI în ultimul deceniu. Baie o scenă din fiecare..

Cum se adaugă fundaluri CSS fun la site-urile dvs.
să Jan 29, 2026Timpul a fost un fundal al paginii web a fost o imagine minusca a tigla - si adesea hideous, asaltati ochelari de vedere al fiec�..

Cum se adaugă video la PDF-uri interactive
să Jan 29, 2026O imagine este în valoare de o mie de cuvinte, iar un videoclip merită un milion. Video poate transmite mai multe informații mai rapide decât imaginile tipărite sau statice. Poate face c..

Creați un cinematografie cu Photoshop în 60 de secunde
să Jan 29, 2026Vrei să poți ridica o nouă abilitate, dar nu pare să găsești timpul să stai jos și să înveți? Adobe's. Face acum playlist ar putea fi exact ceea ce faceți după. Um..

Cum se face 3D litere în Illustrator
să Jan 29, 2026Săptămâna trecută, Adobe a lansat mai multe videoclipuri în cele mai utile să fie acum playlist, oferind creatorilor șansa de a ridica o serie de abilități practice în doar 60 de se..
Categorii
- AI și învățare Automată
- Airpods
- Amazon
- Amazon Alexa și Amazon Echo
- Amazon Alexa & Amazon Echo
- Amazon Fire TV
- Amazon Prime Video
- Android
- Telefoane și Comprimate Android
- Telefoane și Tablete Android
- Android TV
- Apple
- Apple App Store
- Apple HomeKit & Apple Homepod
- Muzică Apple
- Apple TV
- Ceasul Apple
- Apps & Web Apps
- Aplicații și Aplicații Web
- Audio
- Chromebook & Chrome OS
- Chromebook & Chrome OS
- Chromcast
- Cloud & Internet
- Cloud și Internet
- Cloud și Internet
- Hardware De Calculator
- Istoricul Calculatorului
- Cutând Cordon & Streaming
- Tăierea și Fluxul De Cabluri
- Discord
- Disney +
- DIY
- Vehicule Electrice
- EReaders
- Elementele Esențiale
- Explicatori
- Jocuri
- General
- Gmail
- Asistent Google & Google Nest
- Google Assistant și Google Nest
- Google Chrome
- Google Docs
- Google Drive
- Google Maps
- Magazin Google Play
- Google Foile
- Google Diapozitive
- Google TV
- Hardware
- HBO MAX
- Să
- Hulu
- Slang De Internet și Abrevieri
- IPhone & IPad
- Kindle
- Linux
- Mac
- Întreținere și Optimizare
- Microsoft Edge
- Microsoft Excel
- Oficiul Microsoft
- Microsoft Outlook
- Microsoft PowerPoint
- Echipe Microsoft
- Microsoft Word
- Mozilla Firefox
- Netflix
- Comutator Nintendo
- Paramount +
- Gaming PC
- Peacock
- Fotografie
- Photoshop
- PlayStation
- Confidențialitate și Securitate
- Confidențialitate și Securitate
- Confidențialitate și Securitate
- Roundup-uri De Produs
- Programare
- Raspberry Pi
- ROKU
- Safari
- Telefoane și Comprimate Samsung
- Telefoane și Tablete Samsung
- Slack
- Smart Home
- Snapchat
- Media Socială
- Spaţiu
- Spotify
- TINDIND
- Depanare
- TV
- Jocuri Video
- Realitate Virtuala
- VPN
- Browsere Web
- Wi-Fi & Routere
- WiFi & Routers
- Ferestre
- Windows 10
- Windows 11
- Windows 7
- Xbox
- YouTube & YouTube TV
- YouTube și YouTube TV
- Zoom
- Explicații