Understand natural language processing

वेबसाइटों और ऐप्स में फ्रंट एंड रचनात्मक, सर्वर-साइड प्रोसेसिंग, एपीआई और डेटा स्टोरेज सहित विभिन्न चलती भागों हो सकते हैं। एआई इनमें से किसी भी घटकों में प्लग कर सकते हैं।
सामने के अंत में, आप वॉयस कमांड, चैटबॉट इंटरफेस या प्रतिक्रियाशील वेबजीएल रचनात्मक तत्वों को जोड़ सकते हैं। बैक एंड पर, डेटाबेस गति और विश्लेषण को अधिकतम करने के लिए बुद्धिमान एल्गोरिदम का उपयोग करते हैं। एपीआई भविष्यवाणियों से सामूहिक प्रशिक्षण तक, एआई कार्यों की एक विस्तृत श्रृंखला से अमूर्तता की एक परत प्रदान कर सकता है।
यदि आप एक डेवलपर के रूप में शुरू कर रहे हैं और कुछ पॉइंटर्स की आवश्यकता है, तो पता लगाएं [2 9] एक ऐप कैसे बनाएं
-
[3 9]
[2 9]
चैटबॉट्स: आपको क्या पता होना चाहिए।
प्राकृतिक भाषा
प्राकृतिक भाषा प्रसंस्करण (एनएलपी) मशीनों और मानव भाषाओं के बीच बातचीत पर केंद्रित है। मनुष्यों और मशीनों के बीच प्राकृतिक संचार में सुधार के लिए भाषा डेटा की विशाल मात्रा की प्रक्रिया और विश्लेषण करने के लिए एनएलपी का उद्देश्य है। एआई के इस क्षेत्र में भाषण मान्यता, भाषा को समझना और प्राकृतिक भाषा उत्पन्न करना शामिल है। हमारा ध्यान प्राकृतिक भाषा को समझने, किसी पाठ के अर्थ या इरादे का विश्लेषण करने और निर्धारित करने की प्रक्रिया पर होगा।
एनएलपी के लिए कई अवधारणाएं आम हैं:
-
[3 9]
भाषा का पता लगाने
- पाठ में कौन सी भाषा का उपयोग यह जानना मौलिक है यह जानने के लिए कि कौन से शब्दकोश, वाक्यविन्यास और व्याकरण नियम विश्लेषण में उपयोग करने के लिए हैं।
डेटा को पार्स करने और संसाधित करने के लिए कई तकनीकी दृष्टिकोण हैं। भले ही आप किस एनएलपी उपकरण का उपयोग करते हैं, आपको पार्सिंग और विश्लेषण के सामान्य चरणों से निपटना होगा। आम तौर पर पाठ को तार्किक टुकड़ों में अलग किया जाता है। इन हिस्सों का विश्लेषण प्रशिक्षित डेटा या ज्ञान के आधार और असाइन किए गए मूल्यों के खिलाफ किया जाता है, आमतौर पर 0.0 से 1.0 तक विश्लेषण में विश्वास के स्तर को प्रतिबिंबित करने के लिए।
Google की प्राकृतिक भाषा एपीआई
हम इस ट्यूटोरियल के लिए Google द्वारा विकसित नई प्राकृतिक भाषा एपीआई का उपयोग करेंगे। कई एपीआई उपलब्ध हैं लेकिन क्लाउड कंप्यूटिंग, गति, एक अविश्वसनीय रूप से बड़े उपयोगकर्ता आधार और मशीन सीखने सहित Google के कुछ अच्छे फायदे हैं। Google के खोज इंजन और उपकरण वर्षों से एआई का उपयोग कर रहे हैं। तो आप अपनी सार्वजनिक-सामना करने वाली सेवाओं का उपयोग करके उस अनुभव और सीखने का उपयोग कर रहे हैं।
एपीआई किसी भी परियोजना में आसानी से शामिल हो। यह आपके स्वयं के एनएलपी को हाथ से कोडिंग बनाम बहुत समय बचाता है। इसका अमूर्त आरामदायक एपीआई आपको सामान्य कर्ल कॉल या उपलब्ध कई एसडीके के माध्यम से लगभग किसी भी भाषा के साथ एकीकृत करने में सक्षम बनाता है। सेट अप करने के लिए कुछ चाल हैं लेकिन हम एक समय में एक कदम के माध्यम से काम करेंगे।
इसे बढ़ाने के लिए छवि के ऊपरी दाएं भाग पर आइकन पर क्लिक करें।
01. नया Google क्लाउड प्रोजेक्ट बनाएं
[8 9]
पर जाना Google क्लाउड प्लेटफार्म कंसोल और एक नई परियोजना बनाएं या काम करने के लिए मौजूदा एक का चयन करें। यह सेवा तब तक निःशुल्क है जब तक आप एपीआई अनुरोधों की एक बड़ी मात्रा शुरू नहीं करते हैं। जब आप एपीआई को सक्रिय करते हैं तो आपको बिलिंग जानकारी को खाते से जोड़ने की आवश्यकता हो सकती है लेकिन यह कम मात्रा में चार्ज नहीं किया जाता है और यदि आप चाहें तो परीक्षण करने के बाद आप सेवाओं को हटा सकते हैं।
02. क्लाउड एनएल को सक्षम करें
[8 9]
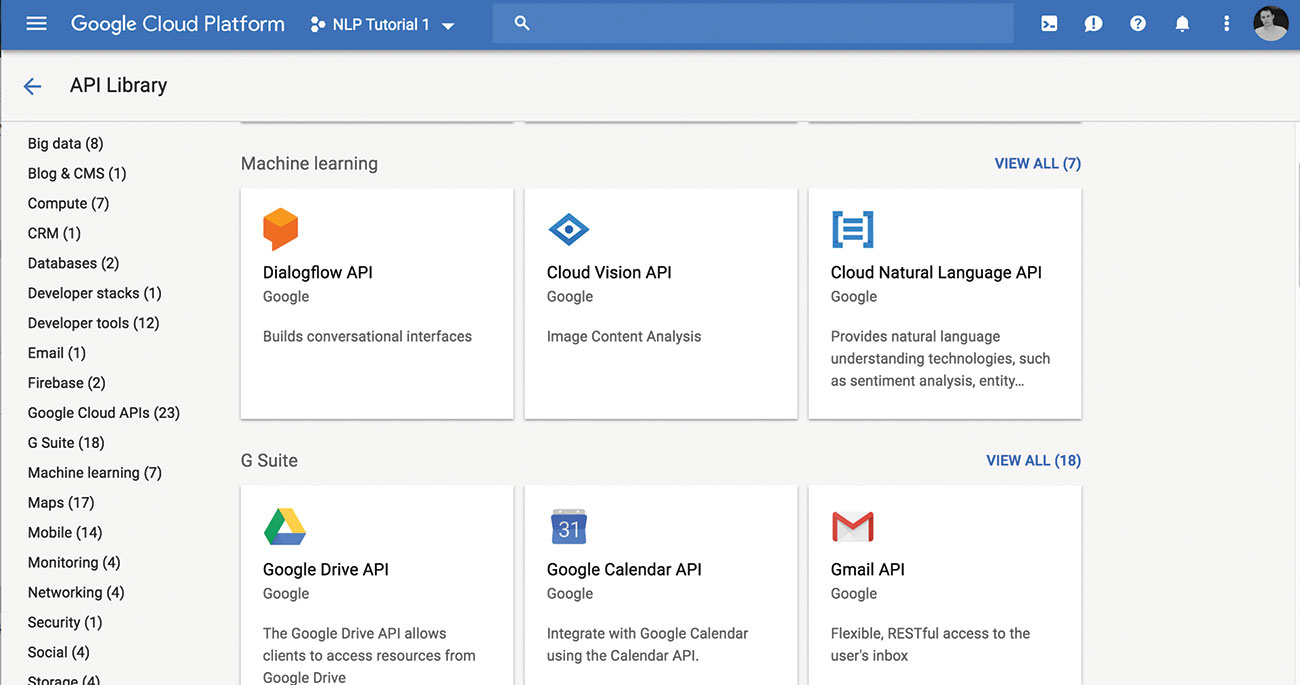
को ब्राउज़ करें एपीआई पुस्तकालय और एनएल एपीआई का चयन करें। एक बार सक्षम होने के बाद आपको थोड़ा हरा चेक और संदेश 'एपीआई सक्षम' देखना चाहिए।
03. एक सेवा खाता बनाएँ
आपको एक स्थापित करने की आवश्यकता होगी [13 9] सेवा लेखा
इस सेवा के लिए। चूंकि हम एक सामान्य सेवा की तरह उपयोग स्थापित करने जा रहे हैं, यह सबसे अच्छा अभ्यास है। यह प्रमाणीकरण प्रवाह के साथ भी सबसे अच्छा काम करता है।04. निजी कुंजी डाउनलोड करें
[8 9]
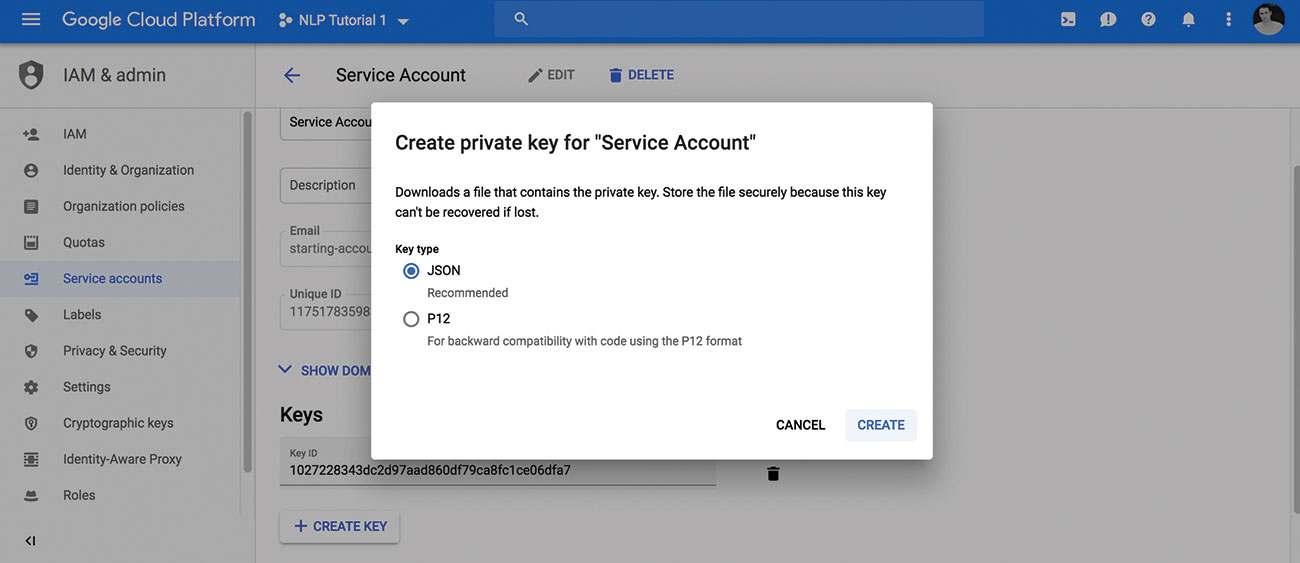
एक बार आपके पास एपीआई सक्षम और एक सेवा खाते के साथ एक प्रोजेक्ट हो जाने के बाद आप जेसन फ़ाइल के रूप में अपनी निजी कुंजी डाउनलोड कर सकते हैं। फ़ाइल के स्थान पर ध्यान दें, ताकि आप इसे अगले चरणों में उपयोग कर सकें।
यदि आपको पहले कुछ चरणों में कोई समस्या है तो एक गाइड है यहां यह मदद करता है, जो JSON कुंजी के डाउनलोड के साथ समाप्त होता है।
05. पर्यावरण चर सेट करें
इसके बाद, आपको सेट करने की आवश्यकता है Google_application_credentials पर्यावरण चर, इसलिए इसे हमारे एपीआई कॉल द्वारा पहुंचा जा सकता है। यह आपके JSON फ़ाइल को इंगित करता है जिसे आपने अभी डाउनलोड किया है और आपको हर बार पथ टाइप करने के लिए सहेजता है। एक नई टर्मिनल विंडो खोलें और निर्यात कमांड का उपयोग करें जैसे:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/username/Downloads/[file name].json"प्रतिस्थापित करें [फ़ाइल का नाम] अपनी निजी कुंजी फ़ाइल के साथ और अपनी फ़ाइल के पथ का उपयोग करें।
विंडोज़ पर आप इस तरह की कमांड लाइन के माध्यम से एक ही काम कर सकते हैं:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].json"नोट: यदि आप अपने टर्मिनल या कंसोल विंडो को बंद करते हैं, तो आपको वैरिएबल सेट करने के लिए फिर से चलाने की आवश्यकता हो सकती है।
06. एपीआई को कॉल करें
अब आप एपीआई का उपयोग करने और एनएलपी को कार्रवाई में देखने के लिए तैयार हैं। आप एपीआई के त्वरित परीक्षण करने के लिए कर्ल का उपयोग करेंगे। आप इस विधि का भी अपने कोड से उपयोग कर सकते हैं।
कर्ल अनुरोध अधिकांश भाषाओं में किए जा सकते हैं, जिसका अर्थ है कि आप कॉल कमांड लाइन में सीधे कर सकते हैं या परिणाम को अपनी पसंद की भाषा में एक चर को असाइन कर सकते हैं। इधर देखो कर्ल का उपयोग करने पर कुछ त्वरित युक्तियों के लिए।
आइए एक साधारण वाक्य के साथ परीक्षण अनुरोध का प्रयास करें। हम इसे चलाएंगे विश्लेषक समापन बिंदु।
अपने टर्मिनल या कमांड लाइन इंटरफ़ेस में, निम्न आदेश दर्ज करें:
[1 9 7] कर्ल -एक्स पोस्ट \ -एच "प्राधिकरण: बियरर" $ (gcloud ऑथ एप्लिकेशन-डिफ़ॉल्ट प्रिंट-टोकन) \ -एच "सामग्री-प्रकार: आवेदन / json; charset = utf-8" \ --डेटा "{ 'दस्तावेज़': { 'प्रकार': 'प्लेन_टेक्स्ट', 'सामग्री': 'जॉन मैककार्थी कृत्रिम बुद्धि के संस्थापक पिता में से एक है।' }, 'एन्कोडिंग टाइप': 'यूटीएफ 8' } "" https://language.googleapis.com/v1/documents:analyzeentities"आपको निष्पादित करने के बाद एक JSON परिणाम देखना चाहिए। आप एपीआई को सक्रिय करने या पहुंच की अनुमति देने के लिए पहली बार इसका उपयोग करने के लिए संकेत प्राप्त कर सकते हैं। आप उस संकेत के लिए 'हां' या 'वाई' का जवाब दे सकते हैं और इसके बाद इसे JSON वापस करना चाहिए।
यह प्रविष्टियों की एक सरणी वापस कर देगा, जो इस तरह के पहले की तरह "जॉन मैककार्थी" के लिए है।
{
"नाम": "जॉन मैककार्थी",
"प्रकार": "व्यक्ति",
"मेटाडाटा": {
"wikipedia_url": "https://en.wikipedia.org/wiki/john_mccarthy_(computer_scientist)",
"मिड": "/ एम / 01 एसवीएफजे"
},
"सल्यता": 0.40979216,
"उल्लेख": [
{
"पाठ": {
"सामग्री": "जॉन मैककार्थी",
"BEGINOFFSET": 0
},
"प्रकार": "उचित"
}
]
}, [1 9 8]
ध्यान दें:
आप कर्ल स्टेटमेंट के सामग्री पैरामीटर में सामग्री टेक्स्ट के बजाय यूआरएल का उपयोग कर सकते हैं।
आप नमूना इकाई सूची में देख सकते हैं,
नाम
पहचान की और
प्रकार
, जो एआई निर्धारित है एक है
व्यक्ति
। यह एक विकिपीडिया मैच भी पाया
नाम
और वह लौटा। यह उपयोगी हो सकता है, क्योंकि आप उस यूआरएल का उपयोग एपीआई के दूसरे अनुरोध के लिए सामग्री के रूप में कर सकते हैं और इस पर और भी अधिक संस्थाएं और जानकारी प्राप्त कर सकते हैं। आप भी देख सकते हैं
आगे निकला हुआ भाग
0.4 पर मूल्य, जो हमारे द्वारा प्रदान किए गए पाठ के संदर्भ में इकाई के महत्वपूर्ण सापेक्ष महत्व को इंगित करता है। आप यह भी देख सकते हैं कि यह सही ढंग से पहचाना गया है
उचित
, जो संज्ञा प्रकार (एक उचित संज्ञा) को संदर्भित करता है, साथ ही साथ पाठ में इकाई की कितनी घटनाएं (उल्लेख)।
एपीआई आपके द्वारा सबमिट किए गए पाठ में सभी प्रमुख इकाइयों के लिए मान वापस करेगा। यह अकेले प्रसंस्करण के लिए बेहद उपयोगी हो सकता है कि उपयोगकर्ता आपके ऐप में क्या संचार कर सकता है। निहित वाक्य के बावजूद, व्यक्ति, जॉन मैककार्थी के बारे में एक अच्छा मौका है, और हम अकेले इस पर आधारित उपयोगकर्ता के लिए कुछ जानकारी देख सकते हैं। हम इस तरह से भी प्रतिक्रिया दे सकते हैं जो हमारी समझ को दर्शाता है यह बयान किसी व्यक्ति को संदर्भित करता है।
आप जिस कॉल का उपयोग करेंगे, उसका परीक्षण करने के लिए इस विधि का उपयोग कर सकते हैं। आप एक भाषा में स्थानीय एसडीके भी सेट कर सकते हैं और अपने ऐप में पूर्णांक।
07. ग्राहक पुस्तकालय स्थापित करें
परियोजनाओं में एपीआई को एकीकृत करने के तरीके को प्रदर्शित करने के लिए एक साधारण वेब-आधारित ऐप बनाने का समय।
एनएलपी ऐप्स के लिए पायथन या नोड का उपयोग करना आम है। एपीआई का उपयोग करने की बहुमुखी प्रतिभा को दिखाने के लिए, हम PHP एसडीके का उपयोग करेंगे। यदि आप एक अलग भाषा में कोड को ट्विक करना चाहते हैं तो एसडीके का एक बड़ा संसाधन है
यहां
।
यह सुनिश्चित करके शुरू करें कि आपके पास अपने स्थानीय या दूरस्थ सर्वर पर एक प्रोजेक्ट फ़ोल्डर सेट अप है। यदि आपके पास पहले से नहीं है, तो संगीतकार प्राप्त करें और अपने प्रोजेक्ट फ़ोल्डर में इंस्टॉल करें। आपके पास पहले से ही वैश्विक स्तर पर स्थापित संगीतकार हो सकते हैं और यह भी ठीक है।
अपने प्रोजेक्ट में विक्रेता फ़ाइलों को स्थापित करने के लिए निम्न संगीतकार कमांड चलाएं:
[1 9 7] PHP -R "प्रतिलिपि ('https://getcomposer.org/installer', 'संगीतकार-सेटअप.पीएचपी');"
php -r "अगर (hash_file ( 'SHA384', 'संगीतकार-setup.php') ===" 93b54496392c06277467 0ac18b134c3b3a95e5a5e5 c8f1a9f115f203b75bf9a129d5 daa8ba6a13e2cc8a1da080 6388a8 ') {गूंज' इंस्टालर सत्यापित ';} else {गूंज' इंस्टालर भ्रष्ट '; अनलिंक (' संगीतकार-setup.php ');} echo php_eol; "
PHP संगीतकार-सेटअप.पीएचपी
PHP -R "अनलिंक ('संगीतकार-सेटअप.एफपी');"
PHP संगीतकार.पार को Google / क्लाउड-भाषा की आवश्यकता होती है [1 9 8]
संगीतकार आपके प्रोजेक्ट फ़ोल्डर में एक विक्रेता फ़ोल्डर बनाता है और आपके लिए सभी निर्भरताओं को स्थापित करता है।
यदि आप इसे सेट अप करने के लिए अटक जाते हैं और PHP का उपयोग करना चाहते हैं, तो आप इस संसाधन को देख सकते हैं
संगीतकार स्थापित करना
।
08. एक नई फाइल बनाएं
यदि आप PHP में साथ चल रहे हैं, तो अपने प्रोजेक्ट फ़ोल्डर में एक नई PHP फ़ाइल बनाएं। इसे सेट करें हालांकि आप पसंद करते हैं लेकिन टेक्स्ट को तुरंत सबमिट करने के लिए एक साधारण HTML फॉर्म शामिल करें।
फॉर्म के साथ एक उदाहरण PHP फ़ाइल यहां दी गई है:
& lt;! डॉक्टाइप एचटीएमएल और जीटी;
& lt; html & gt;
& lt; हेड और जीटी;
& lt; शीर्षक & gt; नेट - एनएलपी ट्यूटोरियल & lt; / शीर्षक & gt;
& lt; / सिर & gt;
& lt; शरीर & gt;
& lt; फॉर्म और जीटी;
& lt; p & gt; & lt; इनपुट प्रकार = 'टेक्स्ट' आईडी = "सामग्री" नाम = "सामग्री" प्लेसहोल्डर = "मैं विश्लेषण क्या कर सकता हूं?" / & gt; & lt; / p & gt;
& lt; p & gt; & lt; इनपुट प्रकार = 'सबमिट करें' नाम = 'सबमिट' आईडी = 'सबमिट' मान = 'विश्लेषण' & gt; & lt; / p & gt;
& lt; / फॉर्म & gt;
& lt; div class = "परिणाम" & gt;
& lt;? PHP
// PHP कोड यहाँ जाता है //
यदि (खाली ($ _ ['सामग्री']) {मर (); }
$ सामग्री = $ _get ['सामग्री'];
? & gt;
& lt; / div & gt;
& lt; / शरीर & gt;
& lt; / html & gt;
कोड में आपके PHP कोड के लिए प्लेसहोल्डर के साथ एक फॉर्म के साथ एक मूल HTML फ़ाइल शामिल है। कोड बस सामग्री चर (फॉर्म से सबमिट) के अस्तित्व की जांच करके शुरू होता है। यदि यह अभी तक सबमिट नहीं किया गया है, तो यह सिर्फ बाहर निकलता है और कुछ भी नहीं करता है।
09. पर्यावरण चर बनाते हैं
कमांड लाइन कर्ल कॉल का उपयोग करते समय हमने पहले किए गए चरण के समान, हमें सेट करने की आवश्यकता है
Google_application_credentials
चर। इसे प्रमाणित करने के लिए यह आवश्यक है।
PHP में हम उपयोग करते हैं
Putenv
एक पर्यावरण चर सेट करने के लिए आदेश। एसडीके द्वारा निर्मित प्रमाणीकरण समाप्त हो रहा है, इसलिए आपको इसे अपने कोड में इसे पकड़ने और इसे हर बार सेट करने की आवश्यकता है।
अपने PHP कोड में अगला इस कोड को जोड़ें:
Putenv ('google_application_credentials = / उपयोगकर्ता / रिचर्डमैटका / डाउनलोड / एनएलपी ट्यूटोरियल 1-1027228343DC.JSON'); [1 9 8]
पथ और फ़ाइल नाम को बदलें जैसा आपने पहले अपने साथ किया था।
10. पुस्तकालय को प्रारंभ करें
इसके बाद, पुस्तकालय जोड़ें और प्रारंभ करें
सुभाषित
आपके कोड में कक्षा। अपने PHP कोड अनुभाग के बगल में यह कोड जोड़ें:
__dir__ की आवश्यकता होती है। '/vendor/autoload.php';
Google \ क्लाउड \ भाषा \ LanguageClient का उपयोग करें;
$ प्रोजेक्टिड = 'एनएलपी-ट्यूटोरियल-1-154350653132 9';
$ भाषा = नया LanguageClient ([
'प्रोजेक्टिड' = & gt; $ प्रोजेक्टिड
]); [1 9 8]
विक्रेता को ऑटोलोड की आवश्यकता से शुरू करें। यदि आपको अपनी निर्भरता की आवश्यकता है तो यह पायथन या नोड में समान है। आयात करें
सुभाषित
अगला, कक्षा का उपयोग करने के लिए। अपने परिभाषित करें
प्रोजेक्टिड
। यदि आप सुनिश्चित नहीं हैं कि यह क्या है, तो आप इसे अपने जीसीपी कंसोल में देख सकते हैं, जहां आपने मूल रूप से परियोजना की स्थापना की है। अंत में, एक नया बनाएँ
सुभाषित
आप का उपयोग कर वस्तु
प्रोजेक्टिड
और इसे असाइन करें
$ भाषा
चर।
11. संस्थाओं का विश्लेषण करें
अब आप अपने कोड में एनएलपी एपीआई का उपयोग शुरू करने के लिए तैयार हैं। आप सामग्री को फॉर्म से एपीआई में जमा कर सकते हैं और परिणाम प्राप्त कर सकते हैं। अभी के लिए आप केवल JSON को स्क्रीन पर प्रदर्शित करेंगे। अभ्यास में आप परिणामों का आकलन कर सकते हैं और उन्हें किसी भी तरह से उपयोग कर सकते हैं। आप परिणामों के आधार पर उपयोगकर्ता का जवाब दे सकते हैं, अधिक जानकारी देख सकते हैं या कार्य निष्पादित कर सकते हैं।
पुनः प्राप्त करने के लिए, इकाई विश्लेषण पाठ में पाए गए 'क्या' या 'चीजें' के बारे में जानकारी वापस कर देगा।
$ परिणाम = $ भाषा- & gt; analyzeentities ($ सामग्री);
foreach ($ परिणाम- & gt; संस्थाएँ () $ e के रूप में) {
गूंज "& lt; div class = 'परिणाम' & gt;";
$ परिणाम = json_encode ($ ई, JSON_PRETTY_PRINT);
प्रतिध्वनि $ परिणाम;
गूंज "& lt; / div & gt;";
} [1 9 8]
यह कोड सामग्री को प्रस्तुत फॉर्म से प्रस्तुत करता है
विश्लेषक
एंडपॉइंट और परिणाम को स्टोर करता है
$ परिणाम
चर। फिर, आप वापस आने वाली संस्थाओं की सूची में पुनरावृत्ति करते हैं
$ परिणाम- & gt; संस्थाएँ ()
। इसे थोड़ा और पठनीय बनाने के लिए, आप स्क्रीन पर आउटपुट करने से पहले इसे जेसन के रूप में प्रारूपित कर सकते हैं। फिर, यह आपको यह दिखाने के लिए एक उदाहरण है कि इसका उपयोग कैसे करें। आप इसे संसाधित कर सकते हैं और परिणामों पर प्रतिक्रिया कर सकते हैं जिन्हें आपको चाहिए।
12. भावना का विश्लेषण करें
[8 9]

प्राकृतिक भाषा एपीआई के साथ पाठ को संसाधित करने के लिए एक साधारण रूप और सर्वर-साइड कोड का उपयोग करना
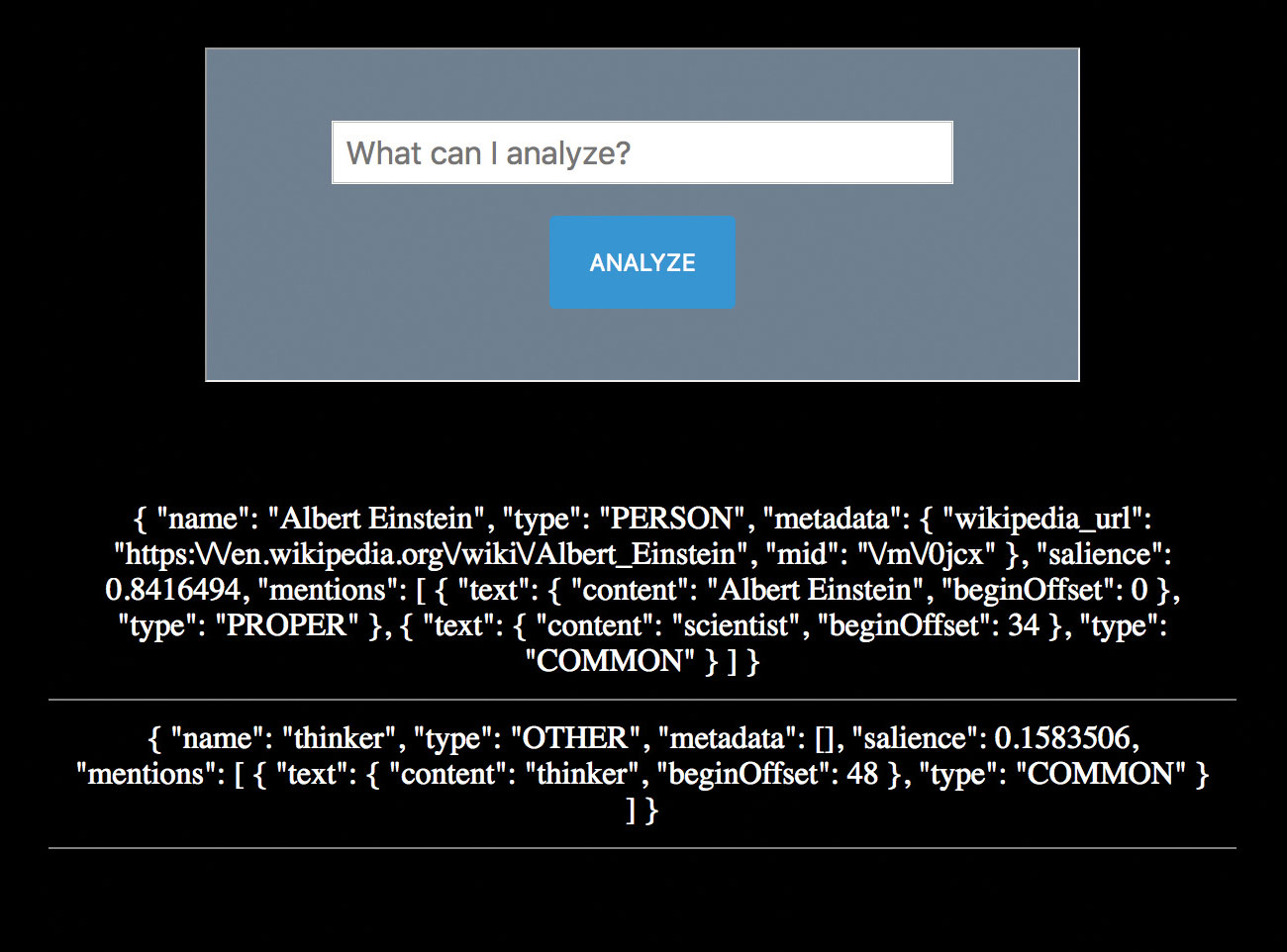
सामग्री के 'क्या' जानने के बजाय, यह भाव जानना भी मूल्यवान हो सकता है। उपयोगकर्ता कैसा महसूस करता है? वे अपने संचार में संस्थाओं के बारे में कैसा महसूस करते हैं?
उपयोग करने के लिए कोड को अपडेट करें analyjenentitysentiment समापन बिंदु। यह दोनों इकाइयों का आकलन करेगा, लेकिन प्रत्येक के लिए एक भावी स्कोर भी वापस कर देगा।
$ परिणाम = $ भाषा- & gt; analyzeentitysentiment ($ सामग्री);
foreach ($ परिणाम- & gt; संस्थाएँ () $ e के रूप में) {
गूंज "& lt; div class = 'परिणाम' & gt;";
$ परिणाम = json_encode ($ ई, JSON_PRETTY_PRINT);
प्रतिध्वनि $ परिणाम;
गूंज "& lt; / div & gt;";
} [1 9 8]
फॉर्म के माध्यम से सामग्री के साथ परीक्षण, "स्टार वार्स सभी समय की सबसे अच्छी फिल्म है।", आप इस तरह के परिणाम देखेंगे:
{"नाम": "स्टार वार्स", "टाइप": "Work_Of_Art", "मेटाडेटा": {"mid": "\ / m \ / 06mmr", "wikipedia_url": "https: \ / \ / en.wikipedia.org \ / wiki \ / star_wars "}," नमकीन ": 0.63493526," उल्लेख ": [{" टेक्स्ट ": {" सामग्री ":" स्टार वार्स "," BEGINOFFSET ": 0}," टाइप " : "उचित", "भावना": {"परिमाण": 0.6, "स्कोर": 0.6}}], "भावना": {"परिमाण": 0.6, "स्कोर": 0.6}}
{"नाम": "मूवी", "टाइप": "Work_Of_Art", "मेटाडाटा": [], "लारियंस": 0.36506474, "उल्लेख": [{"टेक्स्ट": {"सामग्री": "मूवी", " BEGINOFFSET ": 22}," टाइप ":" सामान्य "," भावना ": {" परिमाण ": 0.9," स्कोर ": 0.9}}]," भावना ": {" परिमाण ": 0.9," स्कोर ": 0.9 }} [1 9 8]
यह महत्वपूर्ण मूल्य का एक सकारात्मक भावना स्कोर दिखाता है। न केवल अब आप उन महत्वपूर्ण शब्दों को जानते हैं जो उपयोगकर्ता संचार कर रहा है, लेकिन यह भी कि वे इसके बारे में कैसा महसूस करते हैं। आपका ऐप इस डेटा के आधार पर उचित प्रतिक्रिया दे सकता है। आपको उच्च नम्रता वाले प्राथमिक विषय के रूप में "स्टार वार्स" की स्पष्ट पहचान मिली है। यदि आप एक ही एपीआई कॉल के माध्यम से उस यूआरएल को वापस चलाने के लिए चाहते हैं तो आपको अधिक जानकारी प्राप्त करने के लिए एक विकिपीडिया लिंक मिला है। आप यह भी जानते हैं कि उपयोगकर्ता इसके बारे में सकारात्मक महसूस कर रहा है। आप एक फिल्म के रूप में इसकी गुणवत्ता पर सकारात्मक भावना को वक्तव्य भी देख सकते हैं। बहुत ही शांत।
विभाजन विचार
अन्य एंडपॉइंट्स के साथ प्रयोग करने का प्रयास करें। विशेष रूप से, देखें
Analyzesyntax
तथा
वर्गीकरण
समापन बिंदु। ये आपको भाषण डेटा और सामग्री संस्थाओं के वर्गीकरण के अधिक भागों और वर्गीकरण देते हैं।
यह लेख मूल रूप से अंक 315 में प्रकाशित किया गया था
[2 9]
जाल
संबंधित आलेख:
-
[3 9]
[2 9]
7 विशाल तकनीकी रुझान जो डिजाइनरों को अभी जानने की जरूरत है
कैसे करना है - सर्वाधिक लोकप्रिय लेख

Create your own Calligraphic brush in Illustrator
कैसे करना है Feb 6, 2026इलस्ट्रेटर के बारे में सबसे अच्छी चीजों में से एक..


How to draw a character in pen and ink
कैसे करना है Feb 6, 2026एक गेम स्टूडियो में एक कलाकार के रूप में मैं सबसे �..

How to design believable fantasy beasts
कैसे करना है Feb 6, 2026प्राणी और दृष्टिकोण के कई तरीके हैं चरित्र पर�..

Jump start React Native with Expo
कैसे करना है Feb 6, 2026मूल निवासी एक ऐसा मंच है जो आपको जावास्क्रिप�..

Learn to grow foliage with X-Particles
कैसे करना है Feb 6, 2026एक स्थिर संयंत्र को मॉडलिंग जिसमें सीटू में उगाए ..

तीन.जेएस के साथ एक 3 डी ऑब्जेक्ट को कैसे पिघलाएं
कैसे करना है Feb 6, 2026वेब जैसा कि हम इसे जानते हैं, लगातार बदल रहा है और �..

Make a poster from a template in Photoshop
कैसे करना है Feb 6, 2026एडोब आज वीडियो ट्यूटोरियल की एक नई श्रृंखला लॉन्च कर रहा है जिसे इसे अब ब�..
श्रेणियाँ
- एआई और मशीन लर्निंग
- AirPods
- वीरांगना
- अमेज़ॅन एलेक्सा और अमेज़ॅन इको
- अमेज़न एलेक्सा और अमेज़न इको
- अमेज़न आग टीवी
- अमेज़न प्रधानमंत्री वीडियो
- एंड्रॉयड
- Android फ़ोन और टेबलेट
- Android फोन और टैबलेट
- Android टीवी
- एप्पल
- Apple App स्टोर
- एप्पल HomeKit और एप्पल HomePod
- एप्पल संगीत
- एप्पल टीवी
- एप्पल घड़ी
- एप्लिकेशन और वेब Apps
- ऐप्स और वेब ऐप्स
- ऑडियो
- Chrome बुक और क्रोम ओएस
- क्रोमबुक और क्रोम ओएस
- Chromecast
- बादल और इंटरनेट
- बादल और इंटरनेट
- क्लाउड और इंटरनेट
- कंप्यूटर हार्डवेयर
- कंप्यूटर इतिहास
- गर्भनाल काटने और स्ट्रीमिंग
- कॉर्ड कटिंग और स्ट्रीमिंग
- कलह
- डिज्नी +
- DIY
- बिजली के वाहन
- EReaders
- अनिवार्य
- व्याख्यार
- फेसबुक
- जुआ
- जनरल
- Gmail
- गूगल
- गूगल सहायक और गूगल नेस्ट
- Google सहायक और Google नेस्ट
- गूगल क्रोम
- गूगल डॉक्स
- को Google डिस्क
- गूगल मैप्स
- गूगल प्ले स्टोर
- Google शीट
- Google स्लाइड
- गूगल टीवी
- हार्डवेयर
- एचबीओ मैक्स
- कैसे करना है
- Hulu
- इंटरनेट स्लैंग और लघुरूप
- IPhone और IPad
- Kindle
- लिनक्स
- मैक
- रखरखाव और अनुकूलन
- माइक्रोसॉफ्ट एज
- माइक्रोसॉफ्ट एक्सेल
- माइक्रोसॉफ्ट ऑफिस
- माइक्रोसॉफ्ट आउटलुक
- Microsoft PowerPoint
- माइक्रोसॉफ्ट टीमें
- माइक्रोसॉफ्ट वर्ड
- मोज़िला फ़ायरफ़ॉक्स
- Netflix
- Nintendo स्विच
- पैरामाउंट +
- पीसी गेमिंग
- मयूर
- फोटोग्राफी
- फ़ोटोशॉप
- प्लेस्टेशन
- गोपनीयता और सुरक्षा
- निजता एवं सुरक्षा
- गोपनीयता और सुरक्षा
- उत्पाद मवेशियों को इकट्ठा
- प्रोग्रामिंग
- रास्पबेरी Pi
- Roku
- सफारी
- सैमसंग फ़ोन और टेबलेट
- सैमसंग फोन और टैबलेट
- स्लैक
- स्मार्ट होम
- Snapchat
- सामाजिक मीडिया
- अंतरिक्ष
- Spotify
- Tinder
- समस्या निवारण
- टीवी
- ट्विटर
- वीडियो गेम
- आभासी वास्तविकता
- के VPN
- वेब ब्राउज़र
- वाईफ़ाई और रूटर
- वाईफाई और राउटर
- विंडोज
- Windows 10
- विंडोज 11
- विंडोज 7
- एक्सबॉक्स
- यू ट्यूब के यूट्यूब टीवी
- YouTube और YouTube टीवी
- ज़ूम
- Explainers