Reddit ofrece feeds JSON para cada subreddit. A continuación, se explica cómo crear un script Bash que descargue y analice una lista de publicaciones de cualquier subreddit que desee. Esto es solo una de las cosas que puede hacer con los feeds JSON de Reddit.
Instalación de Curl y JQ
Vamos a utilizar
rizo
para obtener el feed JSON de Reddit y
jq
para analizar los datos JSON y extraer los campos que queremos de los resultados. Instale estas dos dependencias usando
apt-get
en Ubuntu y otras distribuciones de Linux basadas en Debian. En otras distribuciones de Linux, utilice la herramienta de administración de paquetes de su distribución.
sudo apt-get install curl jq
Obtener algunos datos JSON de Reddit
Veamos cómo se ve el feed de datos. Utilizar
rizo
para obtener las últimas publicaciones del
Levemente interesante
subreddit:
curl -s -Un "ejemplo de raspador de reddit" https://www.reddit.com/r/MildlyInteresting.json
Tenga en cuenta cómo se utilizan las opciones antes de la URL:
-s
obliga a curl a ejecutarse en modo silencioso para que no veamos ningún resultado, excepto los datos de los servidores de Reddit. La siguiente opción y el parámetro que sigue,
-Un "ejemplo de raspador de reddit"
, establece una cadena de agente de usuario personalizada que ayuda a Reddit a identificar el servicio que accede a sus datos. Los servidores de la API de Reddit aplican límites de velocidad según la cadena del agente de usuario. Establecer un valor personalizado hará que Reddit segmente nuestro límite de velocidad lejos de otras personas que llaman y reducirá la posibilidad de que obtengamos un error HTTP 429 Rate Limit Exceeded.
La salida debería llenar la ventana de la terminal y verse así:
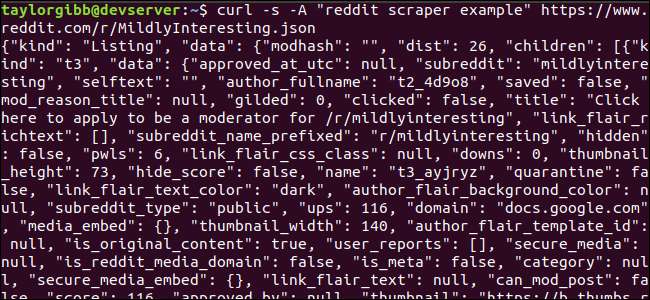
Hay muchos campos en los datos de salida, pero lo único que nos interesa son el título, el enlace permanente y la URL. Puede ver una lista exhaustiva de tipos y sus campos en la página de documentación de la API de Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Extraer datos de la salida JSON
Queremos extraer el título, el enlace permanente y la URL de los datos de salida y guardarlos en un archivo delimitado por tabulaciones. Podemos utilizar herramientas de procesamiento de texto como
y
y
apretón
, pero tenemos otra herramienta a nuestra disposición que comprende las estructuras de datos JSON, llamada
jq
. Para nuestro primer intento, usémoslo para imprimir con estilo y codificar con colores la salida. Usaremos la misma llamada que antes, pero esta vez, canalizaremos el resultado a través de
jq
e indicarle que analice e imprima los datos JSON.
curl -s -Un "ejemplo de raspador de reddit" https://www.reddit.com/r/MildlyInteresting.json | jq.
Tenga en cuenta el período que sigue al comando. Esta expresión simplemente analiza la entrada y la imprime como está. La salida se ve muy bien formateada y codificada por colores:
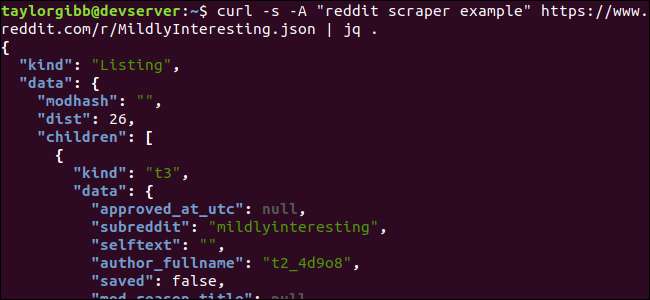
Examinemos la estructura de los datos JSON que obtenemos de Reddit. El resultado raíz es un objeto que contiene dos propiedades: tipo y datos. Este último posee una propiedad llamada
niños
, que incluye una serie de publicaciones en este subreddit.
Cada elemento de la matriz es un objeto que también contiene dos campos llamados tipo y datos. Las propiedades que queremos tomar están en el objeto de datos.
jq
espera una expresión que se pueda aplicar a los datos de entrada y produzca la salida deseada. Debe describir el contenido en términos de su jerarquía y pertenencia a una matriz, así como también cómo se deben transformar los datos. Ejecutemos todo el comando nuevamente con la expresión correcta:
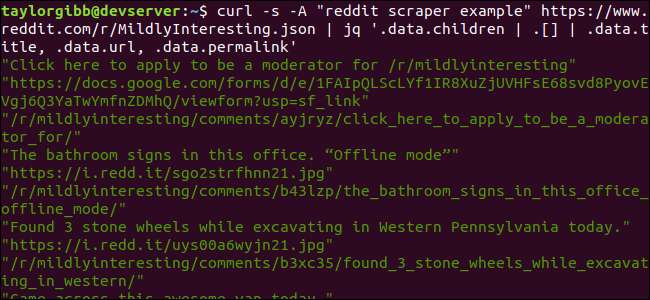
curl -s -Un "ejemplo de raspador de reddit" https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | . [] | .data.title, .data.url, .data.permalink "
La salida muestra el título, la URL y el enlace permanente, cada uno en su propia línea:
Vamos a sumergirnos en el
jq
comando que llamamos:
jq '.data.children | . [] | .data.title, .data.url, .data.permalink "
Hay tres expresiones en este comando separadas por dos símbolos de tubería. Los resultados de cada expresión se pasan a la siguiente para su posterior evaluación. La primera expresión filtra todo excepto la matriz de listados de Reddit. Esta salida se canaliza a la segunda expresión y se fuerza a una matriz. La tercera expresión actúa sobre cada elemento de la matriz y extrae tres propiedades. Más información sobre
jq
y su sintaxis de expresión se puede encontrar en
manual oficial de jq
.
Poniéndolo todo junto en un guión
Juntemos la llamada a la API y el posprocesamiento JSON en un script que generará un archivo con las publicaciones que queremos. Agregaremos soporte para buscar publicaciones de cualquier subreddit, no solo / r / MildlyInteresting.
Abra su editor y copie el contenido de este fragmento en un archivo llamado scrape-reddit.sh
#! / bin / bash
si [ -z "$1" ]
luego
echo "Especifica un subreddit"
salida 1
fi
SUBREDDIT = $ 1
AHORA = $ (fecha + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.children | . [] | .data.title, .data.url, .data.permalink '| \
while read -r TITLE; hacer
leer -r URL
leer -r PERMALINK
echo -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> $ {OUTPUT_FILE}
hecho
Este script primero verificará si el usuario ha proporcionado un nombre de subreddit. De lo contrario, sale con un mensaje de error y un código de retorno distinto de cero.
A continuación, almacenará el primer argumento como el nombre del subreddit y creará un nombre de archivo con el sello de fecha donde se guardará la salida.
La acción comienza cuando
rizo
se llama con un encabezado personalizado y la URL del subreddit para raspar. La salida se canaliza a
jq
donde se analiza y se reduce a tres campos: Título, URL y Enlace permanente. Estas líneas se leen, una a la vez, y se guardan en una variable usando el comando de lectura, todo dentro de un ciclo while, que continuará hasta que no haya más líneas para leer. La última línea del bloque while interno hace eco de los tres campos, delimitados por un carácter de tabulación, y luego lo canaliza a través del
tr
comando para que las comillas dobles se puedan eliminar. Luego, la salida se agrega a un archivo.
Antes de que podamos ejecutar este script, debemos asegurarnos de que se le hayan otorgado permisos de ejecución. Utilizar el
chmod
comando para aplicar estos permisos al archivo:
chmod u + x scrape-reddit.sh
Y, por último, ejecute el script con un nombre subreddit:
./scrape-reddit.sh Suavemente interesante
Se genera un archivo de salida en el mismo directorio y su contenido se verá así:

Cada línea contiene los tres campos que buscamos, separados mediante un carácter de tabulación.
Ir más lejos
Reddit es una mina de oro de contenido y medios interesantes, y se puede acceder a todos fácilmente mediante su API JSON. Ahora que tiene una forma de acceder a estos datos y procesar los resultados, puede hacer cosas como:
- Obtenga los últimos titulares de / r / WorldNews y envíelos a su escritorio usando notificar-enviar
- Integre los mejores chistes de / r / DadJokes en el mensaje del día de su sistema
- Obtenga la mejor imagen de hoy de / r / aww y conviértala en su fondo de escritorio
Todo esto es posible utilizando los datos proporcionados y las herramientas que tiene en su sistema. ¡Feliz piratería!







