Reddit bietet JSON-Feeds für jeden Subreddit an. Hier erfahren Sie, wie Sie ein Bash-Skript erstellen, das eine Liste von Posts von einem beliebigen Subreddit herunterlädt und analysiert. Dies ist nur eine Sache, die Sie mit den JSON-Feeds von Reddit tun können.
Curl und JQ installieren
Wir werden verwenden
locken
um den JSON-Feed von Reddit und abzurufen
jq
um die JSON-Daten zu analysieren und die gewünschten Felder aus den Ergebnissen zu extrahieren. Installieren Sie diese beiden Abhängigkeiten mit
apt-get
auf Ubuntu und anderen Debian-basierten Linux-Distributionen. Verwenden Sie bei anderen Linux-Distributionen stattdessen das Paketverwaltungstool Ihrer Distribution.
sudo apt-get install curl jq
Rufen Sie einige JSON-Daten von Reddit ab
Mal sehen, wie der Datenfeed aussieht. Verwenden
locken
um die neuesten Beiträge aus dem zu holen
MildlyInteresting
subreddit:
curl -s - Ein "Reddit Scraper-Beispiel" https://www.reddit.com/r/MildlyInteresting.json
Beachten Sie, wie die Optionen vor der URL verwendet werden:
-s
Erzwingt, dass Curl im unbeaufsichtigten Modus ausgeführt wird, sodass außer den Daten von Reddits Servern keine Ausgabe angezeigt wird. Die nächste Option und der folgende Parameter:
-Ein "Reddit Scraper Beispiel"
, legt eine benutzerdefinierte Benutzeragentenzeichenfolge fest, mit deren Hilfe Reddit den Dienst identifiziert, der auf seine Daten zugreift. Die Reddit-API-Server wenden Ratenbeschränkungen basierend auf der Benutzeragentenzeichenfolge an. Durch das Festlegen eines benutzerdefinierten Werts wird Reddit unser Tariflimit von anderen Anrufern trennen und die Wahrscheinlichkeit verringern, dass der Fehler "HTTP 429-Tariflimit überschritten" angezeigt wird.
Die Ausgabe sollte das Terminalfenster ausfüllen und ungefähr so aussehen:
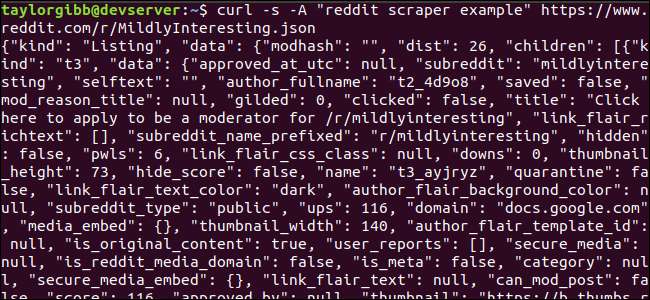
Die Ausgabedaten enthalten viele Felder, aber wir interessieren uns nur für Titel, Permalink und URL. Eine vollständige Liste der Typen und ihrer Felder finden Sie auf der API-Dokumentationsseite von Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Extrahieren von Daten aus der JSON-Ausgabe
Wir möchten Titel, Permalink und URL aus den Ausgabedaten extrahieren und in einer durch Tabulatoren getrennten Datei speichern. Wir können Textverarbeitungswerkzeuge wie verwenden
und
und
Griff
Wir haben jedoch ein anderes Tool zur Verfügung, das JSON-Datenstrukturen versteht
jq
. Verwenden Sie es für unseren ersten Versuch, um die Ausgabe hübsch auszudrucken und farblich zu kennzeichnen. Wir verwenden denselben Aufruf wie zuvor, leiten diesmal jedoch die Ausgabe durch
jq
und weisen Sie es an, die JSON-Daten zu analysieren und zu drucken.
curl -s - Ein "Reddit Scraper-Beispiel" https://www.reddit.com/r/MildlyInteresting.json | jq.
Beachten Sie den Zeitraum nach dem Befehl. Dieser Ausdruck analysiert einfach die Eingabe und druckt sie so wie sie ist. Die Ausgabe sieht gut formatiert und farbcodiert aus:
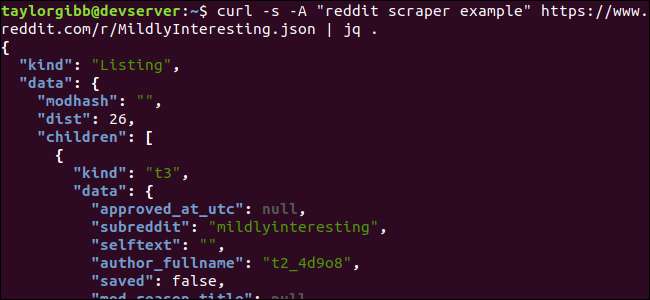
Lassen Sie uns die Struktur der JSON-Daten untersuchen, die wir von Reddit erhalten. Das Stammergebnis ist ein Objekt, das zwei Eigenschaften enthält: Art und Daten. Letzterer hält eine Eigenschaft namens
Kinder
, die eine Reihe von Beiträgen zu diesem Subreddit enthält.
Jedes Element im Array ist ein Objekt, das auch zwei Felder enthält, die als Art und Daten bezeichnet werden. Die Eigenschaften, die wir erfassen möchten, befinden sich im Datenobjekt.
jq
erwartet einen Ausdruck, der auf die Eingabedaten angewendet werden kann und die gewünschte Ausgabe erzeugt. Es muss den Inhalt in Bezug auf seine Hierarchie und Zugehörigkeit zu einem Array sowie die Art und Weise beschreiben, wie die Daten transformiert werden sollen. Führen Sie den gesamten Befehl erneut mit dem richtigen Ausdruck aus:
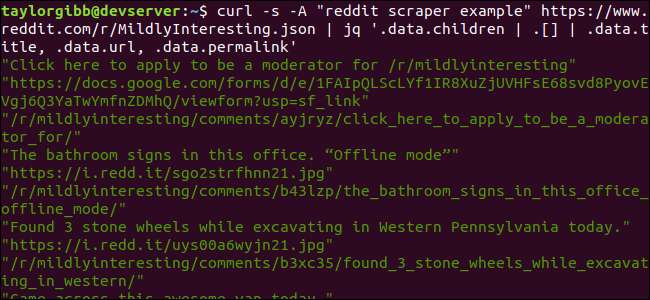
curl -s - Ein "Reddit Scraper-Beispiel" https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | . [] | .data.title, .data.url, .data.permalink ’
Die Ausgabe zeigt Titel, URL und Permalink jeweils in einer eigenen Zeile:
Tauchen wir ein in die
jq
Befehl, den wir genannt haben:
jq ‘.data.children | . [] | .data.title, .data.url, .data.permalink ’
Dieser Befehl enthält drei Ausdrücke, die durch zwei Pipe-Symbole getrennt sind. Die Ergebnisse jedes Ausdrucks werden zur weiteren Bewertung an den nächsten übergeben. Der erste Ausdruck filtert alles außer dem Array von Reddit-Listen heraus. Diese Ausgabe wird in den zweiten Ausdruck geleitet und in ein Array gezwungen. Der dritte Ausdruck wirkt auf jedes Element im Array und extrahiert drei Eigenschaften. Weitere Informationen zu
jq
und seine Ausdruckssyntax finden Sie in
jqs offizielles Handbuch
.
Alles in einem Skript zusammenfassen
Lassen Sie uns den API-Aufruf und die JSON-Nachbearbeitung in einem Skript zusammenfassen, das eine Datei mit den gewünschten Beiträgen generiert. Wir werden Unterstützung für das Abrufen von Posts von jedem Subreddit hinzufügen, nicht nur von / r / MildlyInteresting.
Öffnen Sie Ihren Editor und kopieren Sie den Inhalt dieses Snippets in eine Datei namens scrape-reddit.sh
#! / bin / bash
wenn [ -z "$1" ]
dann
echo "Bitte geben Sie einen Subreddit an"
Ausfahrt 1
fi
SUBREDDIT = $ 1
JETZT = $ (Datum + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
curl -s -A "Bash-Scrape-Themen" https://www.reddit.com/r/${SUBREDDIT}.json | \.
jq '.data.children | . [] | .data.title, .data.url, .data.permalink '| \.
während gelesen -r TITEL; tun
-r URL lesen
Lesen Sie -r PERMALINK
echo -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> $ {OUTPUT_FILE}
erledigt
Dieses Skript prüft zunächst, ob der Benutzer einen Subreddit-Namen angegeben hat. Wenn nicht, wird es mit einer Fehlermeldung und einem Rückkehrcode ungleich Null beendet.
Als Nächstes wird das erste Argument als Subreddit-Name gespeichert und ein Datumsname mit Datumsstempel erstellt, in dem die Ausgabe gespeichert wird.
Die Aktion beginnt wann
locken
wird mit einem benutzerdefinierten Header und der URL des zu kratzenden Subreddits aufgerufen. Der Ausgang wird an weitergeleitet
jq
Hier wird es analysiert und auf drei Felder reduziert: Titel, URL und Permalink. Diese Zeilen werden einzeln gelesen und mit dem Befehl read in einer while-Schleife in einer Variablen gespeichert, die so lange fortgesetzt wird, bis keine Zeilen mehr zu lesen sind. Die letzte Zeile des inneren while-Blocks gibt die drei Felder wieder, die durch ein Tabulatorzeichen begrenzt sind, und leitet sie dann durch das Feld
tr
Befehl, damit die doppelten Anführungszeichen entfernt werden können. Die Ausgabe wird dann an eine Datei angehängt.
Bevor wir dieses Skript ausführen können, müssen wir sicherstellen, dass ihm Ausführungsberechtigungen erteilt wurden. Verwenden Sie die
chmod
Befehl zum Anwenden dieser Berechtigungen auf die Datei:
chmod u + x scrape-reddit.sh
Führen Sie zum Schluss das Skript mit einem Subreddit-Namen aus:
./scrape-reddit.sh MildlyInteresting
Eine Ausgabedatei wird im selben Verzeichnis generiert und ihr Inhalt sieht ungefähr so aus:

Jede Zeile enthält die drei Felder, nach denen wir suchen, getrennt durch ein Tabulatorzeichen.
Weitergehen
Reddit ist eine Goldmine interessanter Inhalte und Medien, auf die über die JSON-API problemlos zugegriffen werden kann. Nachdem Sie nun die Möglichkeit haben, auf diese Daten zuzugreifen und die Ergebnisse zu verarbeiten, können Sie Folgendes tun:
- Holen Sie sich die neuesten Schlagzeilen aus / r / WorldNews und senden Sie sie mit an Ihren Desktop benachrichtigen-senden
- Integrieren Sie die besten Witze von / r / DadJokes in die Message-Of-The-Day Ihres Systems
- Holen Sie sich das beste Bild von heute aus / r / aww und machen Sie es zu Ihrem Desktop-Hintergrund
All dies ist mit den bereitgestellten Daten und den Tools möglich, die Sie auf Ihrem System haben. Viel Spaß beim Hacken!





 für Mac OS X hinzu")

