Reddit menawarkan umpan JSON untuk setiap subreddit. Berikut cara membuat skrip Bash yang mendownload dan mengurai daftar postingan dari subreddit apa pun yang Anda suka. Ini hanya satu hal yang dapat Anda lakukan dengan umpan JSON Reddit.
Menginstal Curl dan JQ
Kami akan menggunakan
keriting
untuk mengambil umpan JSON dari Reddit dan
jq
untuk mengurai data JSON dan mengekstrak bidang yang kita inginkan dari hasil. Instal kedua dependensi ini menggunakan
apt-get
di Ubuntu dan distribusi Linux berbasis Debian lainnya. Di distribusi Linux lainnya, gunakan alat manajemen paket distribusi Anda.
sudo apt-get install curl jq
Ambil Beberapa Data JSON dari Reddit
Mari kita lihat seperti apa data feed itu. Menggunakan
keriting
untuk mengambil kiriman terbaru dari
Sedikit Menarik
subreddit:
curl -s -Sebuah "contoh pengikis reddit" https://www.reddit.com/r/MildlyInteresting.json
Perhatikan bagaimana opsi digunakan sebelum URL:
-s
memaksa curl untuk berjalan dalam mode senyap sehingga kami tidak melihat keluaran apa pun, kecuali data dari server Reddit. Opsi selanjutnya dan parameter yang mengikuti,
-Sebuah "contoh pengikis reddit"
, menyetel string agen pengguna khusus yang membantu Reddit mengidentifikasi layanan yang mengakses datanya. Server API Reddit menerapkan batas kecepatan berdasarkan string agen pengguna. Menetapkan nilai khusus akan menyebabkan Reddit menyegmentasikan batas tarif kami dari penelepon lain dan mengurangi kemungkinan kami mendapatkan kesalahan HTTP 429 Batas Batas Terlampaui.
Outputnya akan memenuhi jendela terminal dan terlihat seperti ini:
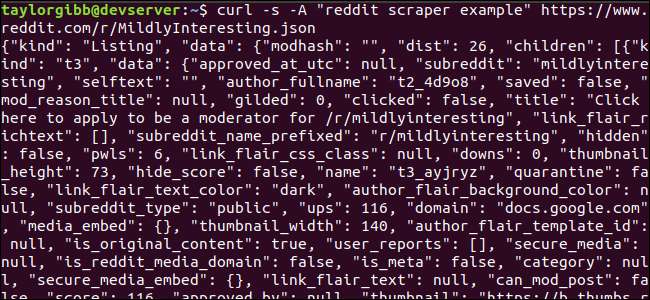
Ada banyak bidang dalam data keluaran, tetapi yang kami minati hanyalah Judul, Tautan Permanen, dan URL. Anda dapat melihat daftar lengkap jenis dan bidangnya di halaman dokumentasi API Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Mengekstrak Data dari Output JSON
Kami ingin mengekstrak Judul, Tautan Permanen, dan URL, dari data keluaran dan menyimpannya ke file tab-delimited. Kita dapat menggunakan alat pengolah teks seperti
dan
dan
pegangan
, tetapi kami memiliki alat lain yang kami miliki yang memahami struktur data JSON, yang disebut
jq
. Untuk percobaan pertama kita, mari kita gunakan untuk mencetak cantik dan memberi kode warna pada keluaran. Kami akan menggunakan panggilan yang sama seperti sebelumnya, tetapi kali ini, menyalurkan keluarannya
jq
dan perintahkan untuk mengurai dan mencetak data JSON.
curl -s -Sebuah "contoh pengikis reddit" https://www.reddit.com/r/MildlyInteresting.json | jq.
Perhatikan periode setelah perintah. Ekspresi ini hanya mengurai input dan mencetaknya sebagaimana adanya. Outputnya tampak diformat dengan baik dan diberi kode warna:
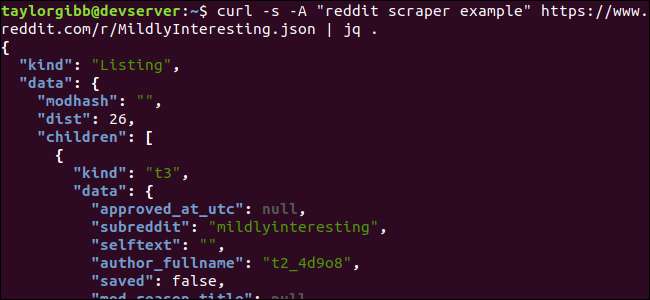
Mari kita periksa struktur data JSON yang kita dapatkan dari Reddit. Hasil root adalah objek yang berisi dua properti: jenis dan data. Yang terakhir memegang properti yang disebut
anak-anak
, yang menyertakan larik postingan ke subreddit ini.
Setiap item dalam larik adalah objek yang juga berisi dua bidang yang disebut jenis dan data. Properti yang ingin kita ambil ada di objek data.
jq
mengharapkan ekspresi yang dapat diterapkan ke data masukan dan menghasilkan keluaran yang diinginkan. Ini harus mendeskripsikan konten dalam hal hierarki dan keanggotaannya pada sebuah array, serta bagaimana data harus diubah. Mari kita jalankan kembali seluruh perintah dengan ekspresi yang benar:
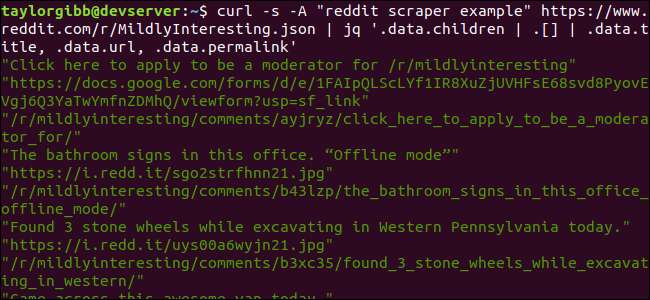
curl -s -Sebuah "contoh pengikis reddit" https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | . [] | .data.title, .data.url, .data.permalink ’
Outputnya menunjukkan Judul, URL, dan Tautan Permanen masing-masing di barisnya sendiri:
Mari selami
jq
perintah yang kami panggil:
jq ‘.data.children | . [] | .data.title, .data.url, .data.permalink ’
Ada tiga ekspresi dalam perintah ini yang dipisahkan oleh dua simbol pipa. Hasil dari setiap ekspresi diteruskan ke yang berikutnya untuk evaluasi lebih lanjut. Ekspresi pertama memfilter semuanya kecuali larik daftar Reddit. Output ini disalurkan ke ekspresi kedua dan dipaksa menjadi array. Ekspresi ketiga bekerja pada setiap elemen dalam larik dan mengekstrak tiga properti. Informasi lebih lanjut tentang
jq
dan sintaks ekspresinya dapat ditemukan di
manual resmi jq
.
Menyatukan Semuanya dalam Skrip
Mari kita gabungkan panggilan API dan pasca-pemrosesan JSON dalam skrip yang akan menghasilkan file dengan postingan yang kita inginkan. Kami akan menambahkan dukungan untuk mengambil postingan dari subreddit mana pun, tidak hanya / r / MildlyInteresting.
Buka editor Anda dan salin konten potongan ini ke dalam file bernama scrape-reddit.sh
#! / bin / bash
jika [ -z "$1" ]
kemudian
echo "Harap tentukan subreddit"
keluar 1
fi
SUBREDDIT = $ 1
SEKARANG = $ (tanggal + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.children | . [] | .data.title, .data.url, .data.permalink '| \
saat membaca -r TITLE; melakukan
baca -r URL
baca -r PERMALINK
echo -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --hapus \ ">> $ {OUTPUT_FILE}
selesai
Skrip ini pertama-tama akan memeriksa apakah pengguna telah memberikan nama subreddit. Jika tidak, itu keluar dengan pesan kesalahan dan kode pengembalian bukan nol.
Selanjutnya, ini akan menyimpan argumen pertama sebagai nama subreddit, dan membangun nama file dengan cap tanggal di mana output akan disimpan.
Tindakan dimulai saat
keriting
dipanggil dengan tajuk khusus dan URL subreddit untuk dikikis. Outputnya disalurkan ke
jq
yang diurai dan dikurangi menjadi tiga bidang: Judul, URL, dan Tautan Permanen. Baris-baris ini dibaca, satu per satu, dan disimpan ke dalam variabel menggunakan perintah baca, semua di dalam while loop, yang akan berlanjut sampai tidak ada lagi baris untuk dibaca. Baris terakhir dari bagian dalam sementara blok menggemakan tiga bidang, dibatasi oleh karakter tab, dan kemudian menyalurkannya melalui
tr
perintah sehingga tanda kutip ganda bisa dihapus. Outputnya kemudian ditambahkan ke file.
Sebelum kami dapat menjalankan skrip ini, kami harus memastikan bahwa skrip tersebut telah diberikan izin eksekusi. Menggunakan
chmod.dll
perintah untuk menerapkan izin ini ke file:
chmod u + x scrape-reddit.sh
Dan, terakhir, jalankan skrip dengan nama subreddit:
./scrape-reddit.sh MildlyInteresting
File keluaran dibuat di direktori yang sama dan isinya akan terlihat seperti ini:

Setiap baris berisi tiga bidang yang kita cari, dipisahkan menggunakan karakter tab.
Pergi Lebih Jauh
Reddit adalah tambang emas konten dan media yang menarik, dan semuanya mudah diakses menggunakan JSON API-nya. Sekarang setelah Anda memiliki cara untuk mengakses data ini dan memproses hasilnya, Anda dapat melakukan hal-hal seperti:
- Dapatkan berita utama terbaru dari / r / WorldNews dan kirimkan ke desktop Anda menggunakan notify-send
- Integrasikan lelucon terbaik dari / r / DadJokes ke dalam Message-Of-The-Day sistem Anda
- Dapatkan gambar terbaik hari ini dari / r / aww dan jadikan sebagai latar desktop Anda
Semua ini dimungkinkan dengan menggunakan data yang disediakan dan alat yang Anda miliki di sistem Anda. Selamat meretas!







