Το Reddit προσφέρει τροφοδοσίες JSON για κάθε subreddit. Δείτε πώς μπορείτε να δημιουργήσετε ένα σενάριο Bash που κατεβάζει και αναλύει μια λίστα αναρτήσεων από οποιοδήποτε subreddit που σας αρέσει. Αυτό είναι μόνο ένα πράγμα που μπορείτε να κάνετε με τις ροές JSON του Reddit.
Εγκατάσταση Curl και JQ
Θα χρησιμοποιήσουμε
μπούκλα
για τη λήψη της ροής JSON από το Reddit και
jq
να αναλύσει τα δεδομένα JSON και να εξαγάγει τα πεδία που θέλουμε από τα αποτελέσματα. Εγκαταστήστε αυτές τις δύο εξαρτήσεις χρησιμοποιώντας
καταλαβαίνω
σε Ubuntu και άλλες διανομές Linux που βασίζονται στο Debian. Σε άλλες διανομές Linux, χρησιμοποιήστε το εργαλείο διαχείρισης πακέτων της διανομής σας.
sudo apt-get install curl jq
Λήψη ορισμένων δεδομένων JSON από το Reddit
Ας δούμε πώς είναι η ροή δεδομένων. Χρήση
μπούκλα
για λήψη των τελευταίων δημοσιεύσεων από το
Ήπια ενδιαφέροντα
subreddit:
curl -s -Ένα "reddit scraper παράδειγμα" https://www.reddit.com/r/MildlyInteresting.json
Σημειώστε πώς χρησιμοποιούνται οι επιλογές πριν από τη διεύθυνση URL:
-μικρό
αναγκάζει το curl να τρέχει σε σιωπηλή λειτουργία, ώστε να μην βλέπουμε καμία έξοδο, εκτός από τα δεδομένα από τους διακομιστές του Reddit. Η επόμενη επιλογή και η παράμετρος που ακολουθεί,
-Ένα "reddit scraper παράδειγμα"
, ορίζει μια προσαρμοσμένη συμβολοσειρά παράγοντα χρήστη που βοηθά το Reddit να αναγνωρίσει την υπηρεσία που αποκτά πρόσβαση στα δεδομένα τους. Οι διακομιστές Reddit API εφαρμόζουν όρια τιμών βάσει της συμβολοσειράς παράγοντα χρήστη. Ο καθορισμός μιας προσαρμοσμένης τιμής θα κάνει το Reddit να τμηματοποιήσει το όριο τιμών μας μακριά από άλλους καλούντες και να μειώσει την πιθανότητα να λάβουμε σφάλμα HTTP 429 Rate Limit Υπέρβαση.
Η έξοδος θα πρέπει να γεμίσει το παράθυρο του τερματικού και να μοιάζει με αυτό:
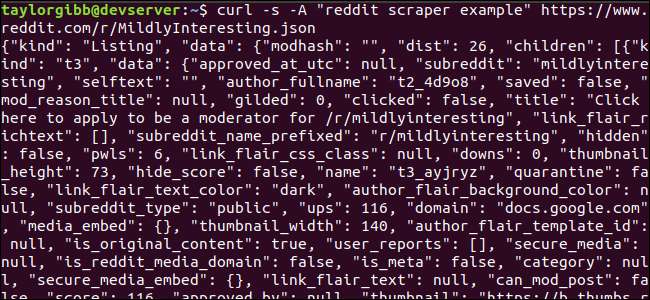
Υπάρχουν πολλά πεδία στα δεδομένα εξόδου, αλλά το μόνο που μας ενδιαφέρει είναι Τίτλος, Μόνιμος σύνδεσμος και διεύθυνση URL. Μπορείτε να δείτε μια αναλυτική λίστα τύπων και τα πεδία τους στη σελίδα τεκμηρίωσης του Reddit API: ήττψ://γιθοβ.κομ/ρεδδιτ-αρχιβε/ρεδδιτ/βίκυ/ΞΣΩΝ
Εξαγωγή δεδομένων από την έξοδο JSON
Θέλουμε να εξαγάγουμε τίτλο, μόνιμο σύνδεσμο και διεύθυνση URL, από τα δεδομένα εξόδου και να τα αποθηκεύσουμε σε ένα αρχείο οριοθετημένο με καρτέλες. Μπορούμε να χρησιμοποιήσουμε εργαλεία επεξεργασίας κειμένου όπως
και
και
λαβή
, αλλά έχουμε ένα άλλο εργαλείο στη διάθεσή μας που κατανοεί τις δομές δεδομένων JSON, που ονομάζεται
jq
. Για την πρώτη μας προσπάθεια, ας το χρησιμοποιήσουμε για να εκτυπώσουμε και να χρωματίσουμε την έξοδο. Θα χρησιμοποιήσουμε την ίδια κλήση με πριν, αλλά αυτή τη φορά, διοχετεύουμε την έξοδο
jq
και δώστε εντολή να αναλύσει και να εκτυπώσει τα δεδομένα JSON.
curl -s -Ένα "reddit scraper παράδειγμα" https://www.reddit.com/r/MildlyInteresting.json | jq.
Σημειώστε την περίοδο που ακολουθεί την εντολή. Αυτή η έκφραση αναλύει απλώς την είσοδο και την τυπώνει ως έχει. Η έξοδος φαίνεται όμορφα μορφοποιημένη και χρωματική κωδικοποίηση:
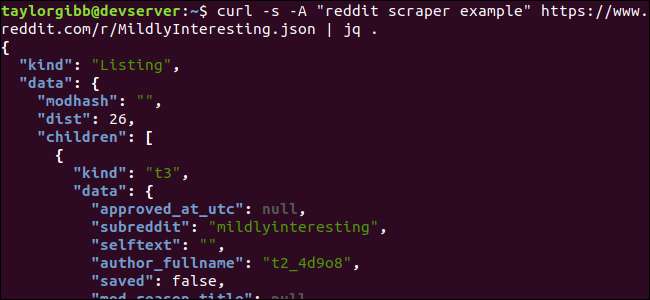
Ας εξετάσουμε τη δομή των δεδομένων JSON που λαμβάνουμε από το Reddit. Το ριζικό αποτέλεσμα είναι ένα αντικείμενο που περιέχει δύο ιδιότητες: είδος και δεδομένα. Το τελευταίο κατέχει μια ιδιότητα που ονομάζεται
παιδιά
, που περιλαμβάνει έναν πίνακα αναρτήσεων σε αυτό το δευτερεύον αρχείο.
Κάθε στοιχείο του πίνακα είναι ένα αντικείμενο που περιέχει επίσης δύο πεδία που ονομάζονται είδος και δεδομένα. Οι ιδιότητες που θέλουμε να αρπάξουμε βρίσκονται στο αντικείμενο δεδομένων.
jq
αναμένει μια έκφραση που μπορεί να εφαρμοστεί στα δεδομένα εισόδου και παράγει την επιθυμητή έξοδο. Πρέπει να περιγράψει τα περιεχόμενα από την άποψη της ιεραρχίας τους και της ιδιότητας μέλους σε έναν πίνακα, καθώς και τον τρόπο μεταμόρφωσης των δεδομένων. Ας εκτελέσουμε ξανά ολόκληρη την εντολή με τη σωστή έκφραση:
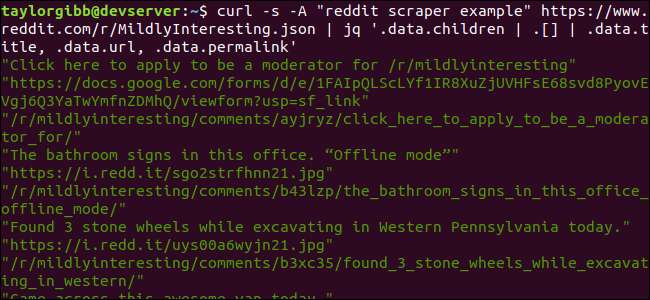
curl -s -Ένα "reddit scraper παράδειγμα" https://www.reddit.com/r/MildlyInteresting.json | jq «.data.children | . [] | .data.title, .data.url, .data.permalink »
Η έξοδος εμφανίζει τον τίτλο, τη διεύθυνση URL και τον μόνιμο σύνδεσμο στη δική τους γραμμή:
Ας βυθίσουμε στο
jq
εντολή που καλέσαμε:
jq «.data.children | . [] | .data.title, .data.url, .data.permalink »
Υπάρχουν τρεις εκφράσεις σε αυτήν την εντολή που χωρίζονται από δύο σύμβολα σωλήνων. Τα αποτελέσματα κάθε έκφρασης περνούν στην επόμενη για περαιτέρω αξιολόγηση. Η πρώτη έκφραση φιλτράρει τα πάντα εκτός από τον πίνακα των λιστών Reddit. Αυτή η έξοδος διοχετεύεται στη δεύτερη έκφραση και αναγκάζεται σε έναν πίνακα. Η τρίτη έκφραση ενεργεί σε κάθε στοιχείο του πίνακα και εξάγει τρεις ιδιότητες. Περισσότερες πληροφορίες για
jq
και η σύνταξη έκφρασης μπορεί να βρεθεί στο
επίσημο εγχειρίδιο του jq
.
Βάζοντας τα όλα μαζί σε ένα σενάριο
Ας βάλουμε την κλήση API και την επεξεργασία μετά το JSON σε ένα σενάριο που θα δημιουργήσει ένα αρχείο με τις αναρτήσεις που θέλουμε. Θα προσθέσουμε υποστήριξη για ανάκτηση αναρτήσεων από οποιοδήποτε subreddit, όχι μόνο / r / MildlyInteresting.
Ανοίξτε τον επεξεργαστή σας και αντιγράψτε το περιεχόμενο αυτού του αποσπάσματος σε ένα αρχείο που ονομάζεται scrape-reddit.sh
#! / bin / bash
εάν [ -z "$1" ]
έπειτα
echo "Προσδιορίστε ένα δευτερεύον αρχείο"
έξοδος 1
fi
SUBREDDIT = 1 $
ΤΩΡΑ = $ (ημερομηνία + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "{SUBREDDIT}_ $ {NOW}.txt"
curl -s -A "bash-scrape-θέματα" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.children | . [] | .data.title, .data.url, .data.permalink '| \
ενώ διαβάζετε -r ΤΙΤΛΟΣ κάνω
read -r URL
διαβάστε -r PERMALINK
echo -e "{TITLE} $ \ t $ {URL} \ t $ {PERMALINK}" | tr - διαγραφή \ ">> {OUTPUT_FILE} $
Ολοκληρώθηκε
Αυτό το σενάριο θα ελέγξει πρώτα εάν ο χρήστης έχει παράσχει ένα όνομα subreddit. Εάν όχι, βγαίνει με ένα μήνυμα σφάλματος και έναν μη επιστρεφόμενο κωδικό επιστροφής.
Στη συνέχεια, θα αποθηκεύσει το πρώτο όρισμα ως το όνομα subreddit και θα δημιουργήσει ένα όνομα αρχείου με ημερομηνία-σήμανση όπου θα αποθηκευτεί η έξοδος.
Η δράση ξεκινά όταν
μπούκλα
καλείται με μια προσαρμοσμένη κεφαλίδα και τη διεύθυνση URL του δευτερεύοντος επεξεργαστή προς απόσυρση. Η έξοδος διοχετεύεται στο
jq
όπου έχει αναλυθεί και μειωθεί σε τρία πεδία: Τίτλος, διεύθυνση URL και Permalink. Αυτές οι γραμμές διαβάζονται, μεμονωμένα, και αποθηκεύονται σε μια μεταβλητή χρησιμοποιώντας την εντολή ανάγνωσης, όλα μέσα σε ένα βρόχο, που θα συνεχιστεί έως ότου δεν υπάρχουν άλλες γραμμές για ανάγνωση. Η τελευταία γραμμή του εσωτερικού ενώ το μπλοκ αντηχεί τα τρία πεδία, οριοθετημένα από έναν χαρακτήρα καρτέλας και στη συνέχεια το διοχετεύει μέσω του
τρ
εντολή έτσι ώστε τα διπλά εισαγωγικά να μπορούν να αφαιρεθούν. Στη συνέχεια, η έξοδος προσαρτάται σε ένα αρχείο.
Προτού μπορέσουμε να εκτελέσουμε αυτό το σενάριο, πρέπει να διασφαλίσουμε ότι έχει εκχωρηθεί δικαιώματα εκτέλεσης. Χρησιμοποιήστε το
chmod
εντολή για την εφαρμογή αυτών των δικαιωμάτων στο αρχείο:
chmod u + x scrape-reddit.sh
Και, τέλος, εκτελέστε το σενάριο με όνομα subreddit:
./scrape-reddit.sh Ήπια ενδιαφέροντα
Ένα αρχείο εξόδου δημιουργείται στον ίδιο κατάλογο και το περιεχόμενό του θα μοιάζει με αυτό:

Κάθε γραμμή περιέχει τα τρία πεδία που ακολουθούμε, χωρισμένα χρησιμοποιώντας έναν χαρακτήρα καρτέλας.
Προχωρώντας περαιτέρω
Το Reddit είναι ένα χρυσωρυχείο ενδιαφέροντος περιεχομένου και πολυμέσων και είναι εύκολα προσβάσιμο μέσω του JSON API. Τώρα που έχετε έναν τρόπο να αποκτήσετε πρόσβαση σε αυτά τα δεδομένα και να επεξεργαστείτε τα αποτελέσματα μπορείτε να κάνετε πράγματα όπως:
- Πιάστε τα πιο πρόσφατα πρωτοσέλιδα από / r / WorldNews και στείλτε τα στον υπολογιστή σας χρησιμοποιώντας ειδοποίηση-αποστολή
- Ενσωματώστε τα καλύτερα αστεία από / r / DadJokes στο μήνυμα-Of-The-Day του συστήματός σας
- Αποκτήστε τη σημερινή καλύτερη εικόνα από / r / aww και δημιουργήστε το ως φόντο της επιφάνειας εργασίας σας
Όλα αυτά είναι δυνατά χρησιμοποιώντας τα παρεχόμενα δεδομένα και τα εργαλεία που έχετε στο σύστημά σας. Καλό χάκερ!





