Reddit erbjuder JSON-flöden för varje subreddit. Så här skapar du ett Bash-skript som laddar ner och analyserar en lista med inlägg från alla subreddit du gillar. Det här är bara en sak du kan göra med Reddits JSON-flöden.
Installera Curl och JQ
Vi ska använda
ringla
för att hämta JSON-flödet från Reddit och
jq
för att analysera JSON-data och extrahera de fält vi vill ha från resultaten. Installera dessa två beroenden med
apt-get
på Ubuntu och andra Debian-baserade Linux-distributioner. På andra Linux-distributioner använder du istället din distributionens pakethanteringsverktyg.
sudo apt-get install curl jq
Hämta några JSON-data från Reddit
Låt oss se hur dataflödet ser ut. Använda sig av
ringla
för att hämta de senaste inläggen från
Mildt intressant
subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Observera hur alternativen som används före webbadressen:
-s
tvingar curl att köra i tyst läge så att vi inte ser någon utdata, förutom data från Reddits servrar. Nästa alternativ och parametern som följer,
-Ett “reddit scraper-exempel”
, ställer in en anpassad användaragentsträng som hjälper Reddit att identifiera tjänsten som får åtkomst till deras data. Reddit API-servrar tillämpar hastighetsgränser baserat på användaragentsträngen. Om du ställer in ett anpassat värde kommer Reddit att segmentera vår taktsgräns från andra som ringer och minska risken för att vi får ett HTTP 429 Rate Limit Exceeded error.
Utgången ska fylla terminalfönstret och se ut så här:
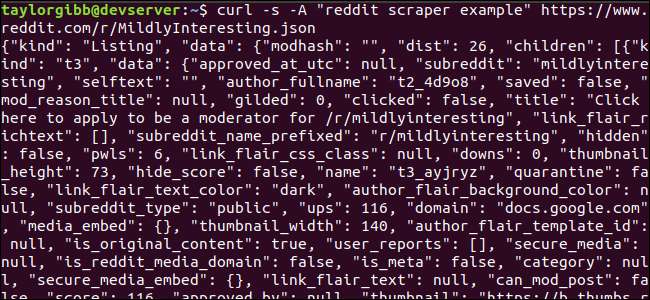
Det finns många fält i utdata, men allt vi är intresserade av är Titel, Permalink och URL. Du kan se en uttömmande lista över typer och deras fält på Reddits API-dokumentationssida: https://github.com/reddit-archive/reddit/wiki/JSON
Extrahera data från JSON-utgången
Vi vill extrahera titel, permalänk och URL från utdata och spara den i en flikavgränsad fil. Vi kan använda textbehandlingsverktyg som
och
och
grep
, men vi har ett annat verktyg till förfogande som förstår JSON-datastrukturer, kallat
jq
. För vårt första försök, låt oss använda den för att vackert skriva ut och färgkoda utdata. Vi kommer att använda samma samtal som tidigare, men den här gången genomföra resultatet
jq
och instruera den att analysera och skriva ut JSON-data.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq.
Observera perioden som följer kommandot. Detta uttryck analyserar helt enkelt inmatningen och skriver ut den som den är. Utgången ser snyggt formaterad och färgkodad ut:
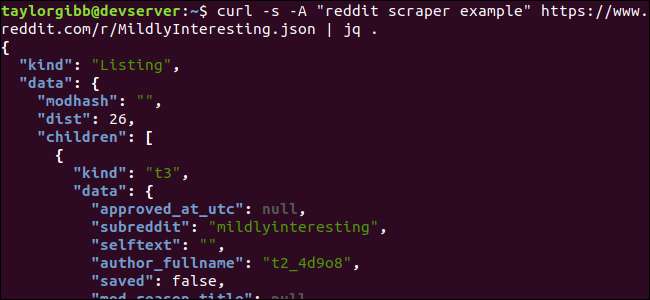
Låt oss undersöka strukturen för JSON-data vi får tillbaka från Reddit. Rotresultatet är ett objekt som innehåller två egenskaper: typ och data. Den senare har en egendom som heter
barn
, som innehåller en rad inlägg till denna underreddit.
Varje objekt i matrisen är ett objekt som också innehåller två fält som kallas typ och data. Egenskaperna vi vill ta är i dataobjektet.
jq
förväntar sig ett uttryck som kan tillämpas på indata och ger önskad utdata. Den måste beskriva innehållet i termer av deras hierarki och medlemskap i en matris, samt hur data ska omvandlas. Låt oss köra hela kommandot igen med rätt uttryck:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.barn | . [] | .data.title, .data.url, .data.permalink '
Utgången visar titel, URL och permalänk var och en på sin egen rad:
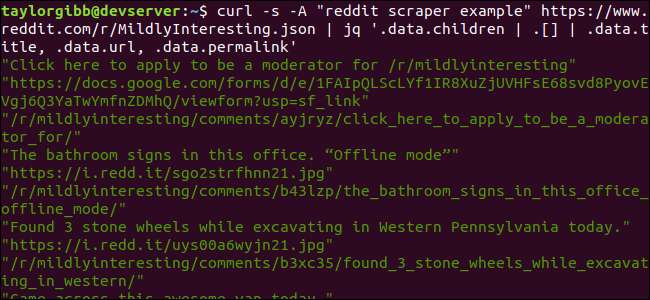
Låt oss dyka in i
jq
kommando vi kallade:
jq ‘.data.barn | . [] | .data.title, .data.url, .data.permalink '
Det finns tre uttryck i detta kommando åtskilda av två rörsymboler. Resultaten av varje uttryck skickas till nästa för vidare utvärdering. Det första uttrycket filtrerar bort allt utom matrisen av Reddit-listor. Denna utgång rörs in i det andra uttrycket och tvingas in i en matris. Det tredje uttrycket verkar på varje element i matrisen och extraherar tre egenskaper. Mer information om
jq
och dess uttryckssyntax finns i
jqs officiella manual
.
Att lägga allt i ett skript
Låt oss sätta API-samtalet och JSON-efterbehandlingen tillsammans i ett skript som genererar en fil med de inlägg vi vill ha. Vi lägger till stöd för att hämta inlägg från valfri subreddit, inte bara / r / MildlyInteresting.
Öppna din redigerare och kopiera innehållet i detta utdrag till en fil som heter scrape-reddit.sh
#! / bin / bash
om [ -z "$1" ]
sedan
echo "Ange en subreddit"
avfart 1
fi
SUBREDDIT = $ 1
NU = $ (datum + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.barn | . [] | .data.title, .data.url, .data.permalink '| \
medan läs -r TITEL; do
läs -r-URL
läs -r PERMALINK
eko -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> $ {OUTPUT_FILE}
Gjort
Detta skript kommer först att kontrollera om användaren har angett ett underrediterat namn. Om inte, avslutas den med ett felmeddelande och en returkod som inte är noll.
Därefter lagras det första argumentet som subreddit-namn och det skapas ett datumstämplat filnamn där utdata kommer att sparas.
Handlingen börjar när
ringla
kallas med en anpassad rubrik och URL för subreddit att skrapa. Utgången rörs till
jq
där den analyseras och reduceras till tre fält: Titel, URL och Permalink. Dessa rader läses, en i taget, och sparas i en variabel med hjälp av läskommandot, allt inuti en stundslinga, som fortsätter tills det inte finns fler rader att läsa. Den sista raden i det inre medan blocket ekar de tre fälten, avgränsade med en tabbtecken, och rör sedan den genom
tr
kommandot så att dubbla citat kan tas bort. Utdata läggs sedan till en fil.
Innan vi kan köra det här skriptet måste vi se till att det har beviljats exekveringsbehörigheter. Använd
chmod
kommando för att tillämpa dessa behörigheter på filen:
chmod u + x scrape-reddit.sh
Och slutligen, kör skriptet med ett subreddit-namn:
./scrape-reddit.sh MildlyInteresting
En utdatafil genereras i samma katalog och dess innehåll ser ut så här:

Varje rad innehåller de tre fälten vi letar efter, åtskilda med hjälp av ett fliktecken.
Går längre
Reddit är en guldgruva med intressant innehåll och media, och det är lätt att nå med JSON API. Nu när du har ett sätt att komma åt dessa data och bearbeta resultaten kan du göra saker som:
- Ta de senaste rubrikerna från / r / WorldNews och skicka dem till ditt skrivbord med meddela-skicka
- Integrera de bästa skämt från / r / DadJokes i ditt systems Message-of-the-Day
- Få dagens bästa bild från / r / aww och gör den till din skrivbordsbakgrund
Allt detta är möjligt med hjälp av de uppgifter som tillhandahålls och de verktyg du har på ditt system. Lycklig hacking!







