Reddit oferuje kanały JSON dla każdego subreddita. Oto jak utworzyć skrypt Bash, który pobiera i analizuje listę postów z dowolnego subreddita. To tylko jedna rzecz, którą możesz zrobić z kanałami JSON Reddit.
Instalowanie Curl i JQ
Będziemy używać
kędzior
aby pobrać kanał JSON z Reddit i
jq
aby przeanalizować dane JSON i wyodrębnić pola, które chcemy, z wyników. Zainstaluj te dwie zależności za pomocą
apt-get
na Ubuntu i innych dystrybucjach Linuksa opartych na Debianie. W innych dystrybucjach Linuksa użyj zamiast tego narzędzia do zarządzania pakietami swojej dystrybucji.
sudo apt-get install curl jq
Pobierz niektóre dane JSON z Reddit
Zobaczmy, jak wygląda plik danych. Posługiwać się
kędzior
aby pobrać najnowsze posty z
Łagodnie Ciekawe
subreddit:
curl -s -A „przykład skrobaka reddit” https://www.reddit.com/r/MildlyInteresting.json
Zwróć uwagę, jak opcje użyte przed adresem URL:
-s
wymusza działanie curl w trybie cichym, dzięki czemu nie widzimy żadnych danych wyjściowych, z wyjątkiem danych z serwerów Reddit. Następna opcja i następujący po niej parametr,
- „Przykład skrobaka reddit”
, ustawia niestandardowy ciąg agenta użytkownika, który pomaga Reddit zidentyfikować usługę uzyskującą dostęp do ich danych. Serwery Reddit API stosują limity szybkości w oparciu o ciąg agenta użytkownika. Ustawienie wartości niestandardowej spowoduje, że Reddit oddzieli nasz limit szybkości od innych dzwoniących i zmniejszy prawdopodobieństwo, że otrzymamy błąd HTTP 429 Rate Limit Exceeded.
Wyjście powinno wypełnić okno terminala i wyglądać mniej więcej tak:
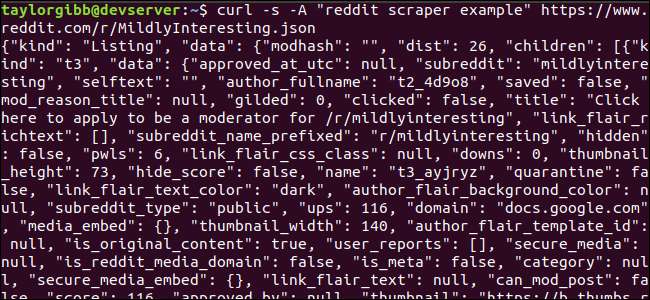
Dane wyjściowe zawierają wiele pól, ale interesują nas tylko tytuł, link bezpośredni i adres URL. Wyczerpującą listę typów i ich pól możesz zobaczyć na stronie dokumentacji interfejsu API Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Wyodrębnianie danych z danych wyjściowych JSON
Chcemy wyodrębnić tytuł, link bezpośredni i adres URL z danych wyjściowych i zapisać je w pliku rozdzielanym tabulatorami. Możemy korzystać z narzędzi do przetwarzania tekstu, takich jak
i
i
uchwyt
, ale mamy do dyspozycji inne narzędzie, które rozumie struktury danych JSON, zwane
jq
. W naszej pierwszej próbie użyjmy go do ładnego wydrukowania i kodowania kolorami wyniku. Użyjemy tego samego wywołania co poprzednio, ale tym razem przekierujemy wyjście
jq
i poinstruuj go, aby przeanalizował i wydrukował dane JSON.
curl -s -A „przykład skrobaka reddit” https://www.reddit.com/r/MildlyInteresting.json | jq.
Zwróć uwagę na okres następujący po poleceniu. To wyrażenie po prostu analizuje dane wejściowe i drukuje je tak, jak jest. Wynik wygląda na ładnie sformatowany i oznaczony kolorami:
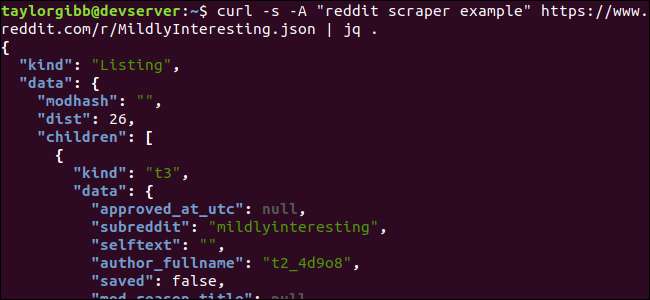
Przyjrzyjmy się strukturze danych JSON, które otrzymujemy z serwisu Reddit. Wynik główny to obiekt, który zawiera dwie właściwości: rodzaj i dane. Ten ostatni posiada własność o nazwie
dzieci
, który zawiera tablicę postów do tego subreddita.
Każdy element tablicy to obiekt, który zawiera również dwa pola zwane rodzajem i danymi. Właściwości, które chcemy pobrać, znajdują się w obiekcie danych.
jq
oczekuje wyrażenia, które można zastosować do danych wejściowych i generuje żądane dane wyjściowe. Musi opisywać zawartość pod względem ich hierarchii i przynależności do tablicy, a także sposobu transformacji danych. Uruchommy ponownie całe polecenie z poprawnym wyrażeniem:
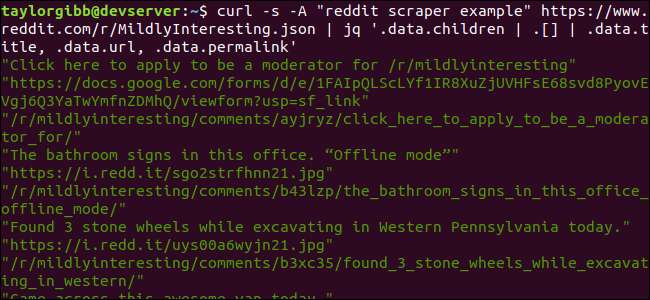
curl -s -A „przykład skrobaka reddit” https://www.reddit.com/r/MildlyInteresting.json | jq „.data.children | . [] | .data.title, .data.url, .data.permalink ”
Dane wyjściowe zawierają tytuł, adres URL i link bezpośredni w osobnych wierszach:
Zanurzmy się w
jq
polecenie, które wywołaliśmy:
jq „.data.children | . [] | .data.title, .data.url, .data.permalink ”
To polecenie zawiera trzy wyrażenia oddzielone dwoma symbolami potoku. Wyniki każdego wyrażenia są przekazywane do następnego w celu dalszej oceny. Pierwsze wyrażenie odfiltrowuje wszystko z wyjątkiem tablicy list Reddit. To wyjście jest przesyłane potokiem do drugiego wyrażenia i wymuszane na tablicy. Trzecie wyrażenie działa na każdy element tablicy i wyodrębnia trzy właściwości. Więcej informacji o
jq
a jego składnię wyrażeń można znaleźć w
oficjalny podręcznik jq
.
Wszystko razem w skrypcie
Połączmy wywołanie API i przetwarzanie końcowe JSON razem w skrypcie, który wygeneruje plik z żądanymi postami. Dodamy obsługę pobierania postów z dowolnego subreddita, nie tylko z / r / MildlyInteresting.
Otwórz edytor i skopiuj zawartość tego fragmentu kodu do pliku o nazwie scrape-reddit.sh
#! / bin / bash
jeśli [ -z "$1" ]
następnie
echo "Określ subreddit"
wyjście 1
fi
SUBREDDIT = 1 $
TERAZ = $ (data + „% m_% d_% y-% H_% M”)
OUTPUT_FILE = "{SUBREDDIT} $_ {NOW}.txt $"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.children | . [] | .data.title, .data.url, .data.permalink '| \
podczas czytania -r TYTUŁ; zrobić
read -r URL
przeczytaj -r PERMALINK
echo -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> {OUTPUT_FILE} dolarów
gotowy
Ten skrypt najpierw sprawdzi, czy użytkownik podał nazwę subreddita. Jeśli nie, kończy się z komunikatem o błędzie i niezerowym kodem powrotu.
Następnie zapisze pierwszy argument jako nazwę subreddita i utworzy nazwę pliku ze znacznikiem daty, w którym dane wyjściowe zostaną zapisane.
Akcja zaczyna się, gdy
kędzior
jest wywoływana z niestandardowym nagłówkiem i adresem URL subreddita do pobrania. Wyjście jest przesyłane potokiem do
jq
gdzie jest analizowany i redukowany do trzech pól: tytuł, URL i link bezpośredni. Te wiersze są odczytywane pojedynczo i zapisywane w zmiennej za pomocą polecenia read, a wszystko to w pętli while, która będzie kontynuowana, dopóki nie będzie więcej wierszy do odczytania. Ostatni wiersz wewnętrznego bloku while powtarza te trzy pola, oddzielone znakiem tabulacji, a następnie przepuszcza je przez
tr
polecenie, aby można było usunąć podwójne cudzysłowy. Dane wyjściowe są następnie dołączane do pliku.
Zanim będziemy mogli wykonać ten skrypt, musimy upewnić się, że nadano mu uprawnienia do wykonywania. Użyj
chmod
polecenie, aby zastosować te uprawnienia do pliku:
chmod u + x scrape-reddit.sh
Na koniec wykonaj skrypt o nazwie subreddita:
./scrape-reddit.sh MildlyInteresting
Plik wyjściowy jest generowany w tym samym katalogu, a jego zawartość będzie wyglądać mniej więcej tak:

Każdy wiersz zawiera trzy pola, o które nam chodzi, oddzielone znakiem tabulacji.
Idąc dalej
Reddit to kopalnia interesujących treści i multimediów, a do wszystkich można łatwo uzyskać dostęp za pomocą interfejsu API JSON. Teraz, gdy masz już dostęp do tych danych i przetworzenie wyników, możesz wykonać następujące czynności:
- Pobierz najnowsze nagłówki z / r / WorldNews i wyślij je na pulpit za pomocą powiadomić-wysłać
- Zintegruj najlepsze dowcipy z / r / DadJokes z wiadomością dnia w swoim systemie
- Uzyskaj najlepsze zdjęcie z / r / aww i ustaw je jako tło pulpitu
Wszystko to jest możliwe dzięki dostarczonym danym i narzędziom, które posiadasz w swoim systemie. Miłego hakowania!







