Reddit offers JSON feeds for each subreddit. Here’s how to create a Bash script that downloads and parses a list of posts from any subreddit you like. This is just one thing you can do with Reddit’s JSON feeds.
Installing Curl and JQ
We’re going to use
कर्ल
to fetch the JSON feed from Reddit and
jq
to parse the JSON data and extract the fields we want from the results. Install these two dependencies using
apt-get
on Ubuntu and other Debian-based Linux distributions. On other Linux distributions, use your distribution’s package management tool instead.
sudo apt-get install curl jq
Fetch Some JSON Data from Reddit
आइए देखें कि डेटा फ़ीड कैसा दिखता है। उपयोग
कर्ल
से नवीनतम पोस्ट लाने के लिए
MildlyInteresting
subreddit:
कर्ल-एस-ए "रेडिट स्क्रेपर उदाहरण" https://www.reddit.com/r/MildlyInteresting.json
ध्यान दें कि URL से पहले उपयोग किए जाने वाले विकल्प:
-s
कर्ल को मूक मोड में चलाने के लिए बाध्य करता है ताकि हम Reddit के सर्वर के डेटा को छोड़कर कोई आउटपुट न देखें। अगला विकल्प और पैरामीटर जो निम्न है,
-एक "लाल खुरचनी उदाहरण"
एक कस्टम उपयोगकर्ता एजेंट स्ट्रिंग सेट करता है जो Reddit को उनके डेटा तक पहुँचने वाली सेवा की पहचान करने में मदद करता है। Reddit API सर्वर उपयोगकर्ता एजेंट स्ट्रिंग के आधार पर दर सीमा लागू करता है। कस्टम वैल्यू सेट करने से Reddit हमारी कॉल लिमिट को दूसरे कॉलर्स से अलग कर देगा और मौका कम कर देगा कि हमें HTTP 429 रेट लिमिट एक्सेस्ड एरर मिलता है।
आउटपुट को टर्मिनल विंडो को भरना चाहिए और कुछ इस तरह देखना चाहिए:
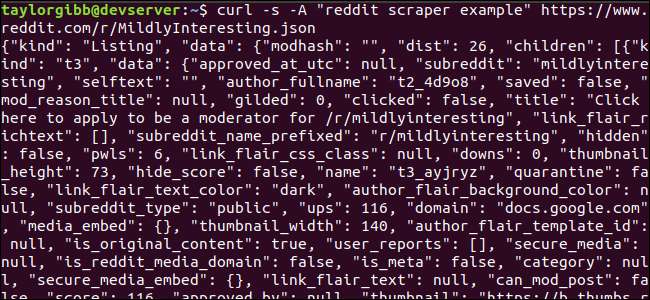
आउटपुट डेटा में बहुत सारे फ़ील्ड हैं, लेकिन हम सभी रुचि रखते हैं शीर्षक, Permalink, और URL। आप Reddit के एपीआई प्रलेखन पृष्ठ पर प्रकारों और उनके क्षेत्रों की एक विस्तृत सूची देख सकते हैं: https://github.com/reddit-archive/reddit/wiki/JSON
Extracting Data from the JSON Output
We want to extract Title, Permalink, and URL, from the output data and save it to a tab-delimited file. We can use text processing tools like
तथा
तथा
पकड़
, लेकिन हमारे पास हमारे निपटान में एक और उपकरण है जो JSON डेटा संरचनाओं को समझता है, जिन्हें कहा जाता है
JQ
. For our first attempt, let’s use it to pretty-print and color-code the output. We’ll use the same call as before, but this time, pipe the output through
jq
and instruct it to parse and print the JSON data.
कर्ल-एस-ए "रेडिट स्क्रैपर उदाहरण" https://www.reddit.com/r/MildlyInteresting.json | जक।
Note the period that follows the command. This expression simply parses the input and prints it as-is. The output looks nicely formatted and color-coded:
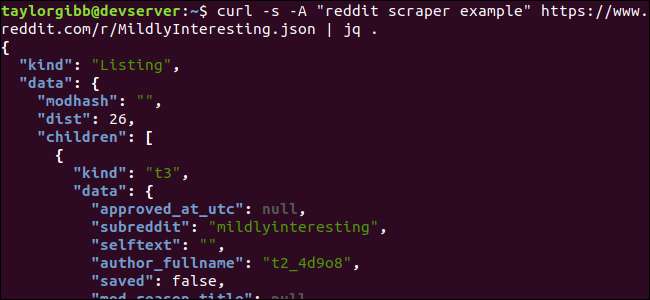
Let’s examine the structure of the JSON data we get back from Reddit. The root result is an object that contains two properties: kind and data. The latter holds a property called
children
, जिसमें इस सब्रेडिट के पदों की एक सरणी शामिल है।
सरणी में प्रत्येक आइटम एक ऑब्जेक्ट है जिसमें दो फ़ील्ड भी होते हैं जिन्हें तरह और डेटा कहा जाता है। जिन संपत्तियों को हम हथियाना चाहते हैं, वे डेटा ऑब्जेक्ट में हैं।
JQ
एक अभिव्यक्ति की अपेक्षा करता है जिसे इनपुट डेटा पर लागू किया जा सकता है और वांछित आउटपुट पैदा करता है। इसमें उनकी पदानुक्रम और सदस्यता के संदर्भ में सामग्री का वर्णन करना होगा, साथ ही साथ डेटा को कैसे रूपांतरित किया जाना चाहिए। चलो सही अभिव्यक्ति के साथ पूरे कमांड को फिर से चलाएं:
कर्ल-एस-ए "रेडिट स्क्रैपर उदाहरण" https://www.reddit.com/r/MildlyInteresting.json | jq q .data.children | [[] | .data.title, .data.url, .data.permalink '
आउटपुट प्रत्येक शीर्षक, URL और Permalink को अपनी लाइन पर दिखाता है:
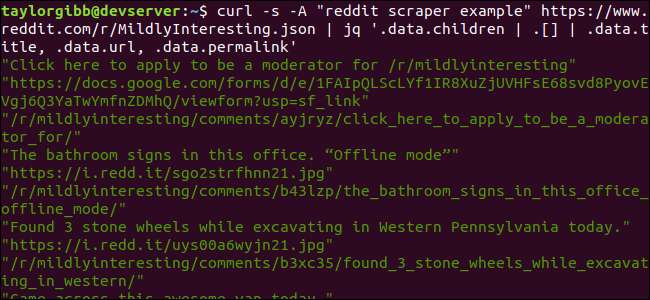
चलो में गोता लगाएँ
JQ
कमांड जिसे हमने बुलाया:
jq q .data.children | [[] | .data.title, .data.url, .data.permalink '
दो पाइप प्रतीकों द्वारा अलग किए गए इस कमांड में तीन अभिव्यक्तियाँ हैं। प्रत्येक अभिव्यक्ति के परिणामों को आगे के मूल्यांकन के लिए अगले पास किया जाता है। पहली अभिव्यक्ति रेडिट लिस्टिंग के सरणी को छोड़कर सब कुछ फ़िल्टर करती है। यह आउटपुट दूसरी अभिव्यक्ति में डाला जाता है और एक सरणी में मजबूर किया जाता है। तीसरी अभिव्यक्ति सरणी में प्रत्येक तत्व पर कार्य करती है और तीन गुणों को निकालती है। के बारे में अधिक जानकारी
JQ
और इसकी अभिव्यक्ति वाक्यविन्यास में पाया जा सकता है
jq का आधिकारिक मैनुअल
.
एक स्क्रिप्ट में यह सब एक साथ लाना
आइए एपीआई कॉल और JSON पोस्ट-प्रोसेसिंग को एक स्क्रिप्ट में एक साथ रखें, जो हम चाहते हैं कि पोस्ट के साथ एक फ़ाइल उत्पन्न करेगा। हम केवल / r / MildlyInteresting ही नहीं, किसी भी सब्रेडिट से पोस्ट लाने के लिए समर्थन जोड़ेंगे।
अपना एडिटर खोलें और इस स्निपेट के कंटेंट को scrape-reddit.sh नामक फाइल में कॉपी करें
#! / Bin / bash
अगर [ -z "$1" ]
फिर
इको "कृपया एक सब्रेडिट निर्दिष्ट करें"
बाहर निकलें 1
फाई
Subreddit = $ 1
अब = $ (दिनांक + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
कर्ल-एस-ए "बाश-परिमार्जन-विषय" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.children | [[] | .data.title, .data.url, .data.permalink '| \
जबकि पढ़ा -r शीर्षक; करना
read -r URL
read -r PERMALINK
इको-ई "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> $ {OUTPUT_FILE}
किया हुआ
यह स्क्रिप्ट पहले जांच करेगी कि उपयोगकर्ता ने एक सब्रेडिट नाम की आपूर्ति की है या नहीं। यदि नहीं, तो यह एक त्रुटि संदेश और एक गैर-शून्य रिटर्न कोड के साथ बाहर निकलता है।
इसके बाद, यह पहले तर्क को सब्रेडिट नाम के रूप में संग्रहित करेगा, और एक तारीख-मुद्रांकित फ़ाइल नाम का निर्माण करेगा जहां आउटपुट सहेजा जाएगा।
जब कार्रवाई शुरू होती है
कर्ल
एक कस्टम हैडर और सब्रेडिट के URL को परिमार्जन करने के लिए कहा जाता है। आउटपुट को पाइप किया जाता है
JQ
जहां यह पार्स और तीन क्षेत्रों में घटा है: शीर्षक, URL और पर्मलिंक। इन पंक्तियों को पढ़ा जाता है, एक-एक-बार, और पढ़ने के आदेश का उपयोग करके एक चर में सहेजा जाता है, सभी थोड़ी देर के लूप के अंदर, यह तब तक जारी रहेगा जब तक कि पढ़ने के लिए और अधिक लाइनें न हों। जबकि एक टैब चरित्र द्वारा सीमांकित, तीन क्षेत्रों को ब्लॉक करता है, जबकि आंतरिक की अंतिम पंक्ति और फिर इसके माध्यम से पाइप करता है
टीआर
कमांड ताकि डबल-कोट्स छीन लिए जा सकें। आउटपुट को तब किसी फ़ाइल में जोड़ा जाता है।
इससे पहले कि हम इस स्क्रिप्ट को निष्पादित कर सकें, हमें यह सुनिश्चित करना चाहिए कि इसे अनुमति दी गई है। उपयोग
chmod
इन अनुमतियों को फ़ाइल में लागू करने के लिए कमांड:
chmod u + x स्क्रेप-reddit.sh
और, अंत में, स्क्रिप्ट को एक सब्रेडिट नाम से निष्पादित करें:
./scrape-reddit.sh मिल्डली इन्टरस्टिंग
एक आउटपुट फ़ाइल एक ही निर्देशिका उत्पन्न होती है और इसकी सामग्री कुछ इस तरह दिखाई देगी:

प्रत्येक पंक्ति में तीन अक्षर होते हैं जिन्हें हम टैब वर्ण का उपयोग करके अलग करते हैं।
आगे बढ़ते हुए
Reddit दिलचस्प सामग्री और मीडिया की एक सोने की खान है, और यह JSON API का उपयोग करके आसानी से सभी तक पहुँचा जा सकता है। अब जब आपके पास इस डेटा तक पहुंचने और परिणामों को संसाधित करने का एक तरीका है, तो आप निम्न कार्य कर सकते हैं:
- / R / WorldNews से नवीनतम सुर्खियों को पकड़ो और उन्हें अपने डेस्कटॉप का उपयोग करके भेजें सूचित-भेज
- आपके सिस्टम के संदेश-द-द-डे में सर्वश्रेष्ठ चुटकुलों को / r / DadJokes से एकीकृत करें
- आज / r / aww से सबसे अच्छी तस्वीर प्राप्त करें और इसे अपनी डेस्कटॉप पृष्ठभूमि बनाएं
यह सब उपलब्ध कराए गए डेटा और आपके सिस्टम पर आपके द्वारा उपयोग किए गए टूल के उपयोग से संभव है। हैप्पी हैकिंग!







