Reddit tarjoaa JSON-syötteet kullekin aliedditille. Näin luodaan Bash-komentosarja, joka lataa ja jäsentää luettelon viesteistä mistä tahansa haluamastasi subredditistä. Tämä on vain yksi asia, jonka voit tehdä Redditin JSON-syötteillä.
Curlin ja JQ: n asentaminen
Aiomme käyttää
kiemura
hakea JSON-syöte Redditistä ja
jq
jäsentää JSON-tiedot ja poimia haluamasi kentät tuloksista. Asenna nämä kaksi riippuvuutta käyttämällä
apt-get
Ubuntu ja muut Debian-pohjaiset Linux-jakelut. Muissa Linux-jakeluissa käytä sen sijaan jakelusi paketinhallintatyökalua.
sudo apt-get install curl jq
Hae joitain JSON-tietoja Redditistä
Katsotaanpa miltä datasyöte näyttää. Käyttää
kiemura
hakea viimeisimmät viestit
Lievästi mielenkiintoinen
subreddit:
kihara -s -Reddit-kaavin esimerkki https://www.reddit.com/r/MildlyInteresting.json
Huomaa, kuinka ennen URL-osoitetta käytetyt vaihtoehdot:
-s
pakottaa käpristyksen toimimaan hiljaisessa tilassa, jotta emme näe mitään ulostuloa, paitsi Redditin palvelimilta tulevat tiedot. Seuraava vaihtoehto ja seuraava parametri,
- "Reddit-kaavin esimerkki"
, asettaa mukautetun käyttäjäagentin merkkijonon, joka auttaa Redditä tunnistamaan palvelun, joka käyttää heidän tietojaan. Reddit-sovellusliittymäpalvelimet käyttävät nopeusrajoituksia käyttäjän agenttijonon perusteella. Mukautetun arvon asettaminen saa Redditin segmentoimaan hintarajamme poispäin muista soittajista ja vähentämään mahdollisuutta saada HTTP 429 -rajan ylitysvirhe.
Lähdön tulisi täyttää pääteikkuna ja näyttää tältä:
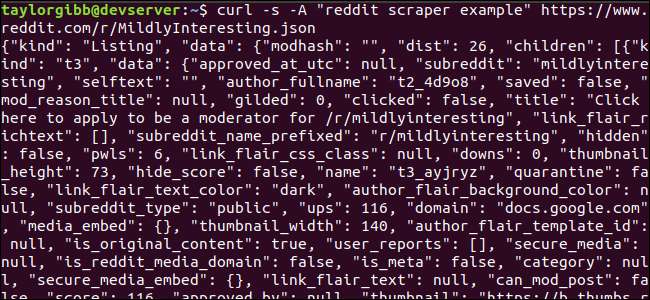
Lähtötiedoissa on paljon kenttiä, mutta kaikki, joista olemme kiinnostuneita, ovat Otsikko, Permalink ja URL. Redditin sovellusliittymän ohjesivulla on kattava luettelo tyypeistä ja niiden kentistä: https://github.com/reddit-archive/reddit/wiki/JSON
Tietojen poimiminen JSON-lähdöstä
Haluamme purkaa otsikon, pysyvän linkin ja URL-osoitteen lähtötiedoista ja tallentaa ne sarkaimilla erotettuun tiedostoon. Voimme käyttää tekstinkäsittelytyökaluja, kuten
ja
ja
pito
, mutta meillä on käytössämme toinen työkalu, joka ymmärtää JSON-tietorakenteet, nimeltään
jq
. Ensimmäisessä yrityksessä käytetään sitä tulostamaan ja värikoodaamaan tulosteen. Käytämme samaa puhelua kuin aiemmin, mutta tällä kertaa ohjaa lähtö läpi
jq
ja neuvoo jäsentämään ja tulostamaan JSON-tiedot.
kihara -s -esimerkki reddit-kaapimesta https://www.reddit.com/r/MildlyInteresting.json | jq.
Huomaa komentoa seuraava jakso. Tämä lauseke vain jäsentää syötteen ja tulostaa sen sellaisenaan. Tulos näyttää hienosti muotoilulta ja värikoodatulta:
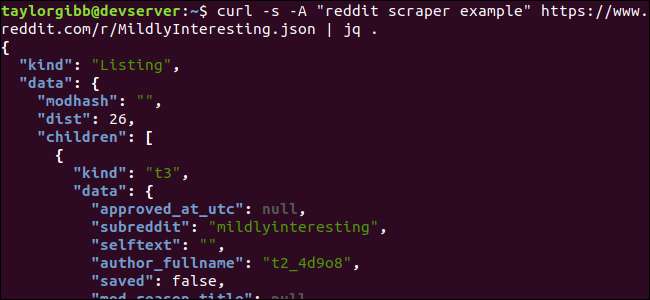
Tarkastellaan Redditiltä saamiemme JSON-tietojen rakennetta. Päätulos on objekti, joka sisältää kaksi ominaisuutta: laji ja data. Jälkimmäisellä on omaisuus nimeltä
lapset
, joka sisältää joukon viestejä tähän subredditiin.
Jokainen taulukon kohde on objekti, joka sisältää myös kaksi kenttää, joita kutsutaan lajiksi ja tiedoksi. Ominaisuudet, jotka haluamme napata, ovat dataobjektissa.
jq
odottaa lauseketta, jota voidaan käyttää syötetietoihin ja tuottaa halutun tuloksen. Sen on kuvattava sisältö niiden hierarkian ja jäsenyyden mukaan, sekä miten tiedot tulisi muuntaa. Suoritetaan koko komento uudelleen oikealla lausekkeella:
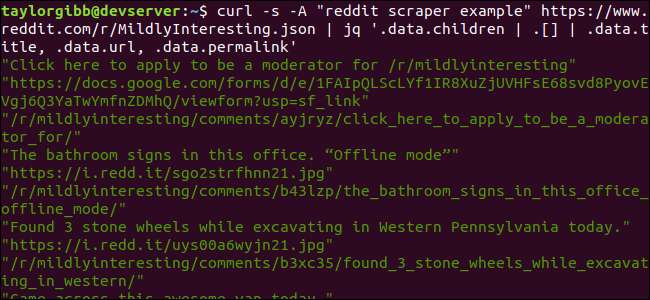
kihara -s -esimerkki reddit-kaapimesta https://www.reddit.com/r/MildlyInteresting.json | jq ’.data.lapset | . [] | .data.title, .data.url, .data.permalink ”
Lähdössä näkyvät otsikko, URL ja pysyvä linkki omalla rivillään:
Sukelletaan
jq
käskyn, jonka soitimme:
jq ’.data.lapset | . [] | .data.title, .data.url, .data.permalink ”
Tässä komennossa on kolme lauseketta, jotka on erotettu kahdella putkisymbolilla. Kunkin lausekkeen tulokset välitetään seuraavalle arviointia varten. Ensimmäinen lauseke suodattaa kaiken paitsi Reddit-luettelot. Tämä lähtö syötetään toiseen lausekkeeseen ja pakotetaan taulukkoon. Kolmas lauseke vaikuttaa ryhmän kaikkiin elementteihin ja poimii kolme ominaisuutta. Lisätietoja
jq
ja sen lausekkeen syntaksin löytyy osoitteesta
jq: n virallinen käsikirja
.
Yhdistämällä kaikki yhdessä käsikirjoitukseen
Laitetaan API-kutsu ja JSON-jälkikäsittely komentosarjaan, joka luo tiedoston haluamillamme viesteillä. Lisäämme tuen viestien hakemiselle mistä tahansa subredditistä, ei pelkästään / r / MildlyInteresting.
Avaa editori ja kopioi tämän koodinpätkän sisältö tiedostoon nimeltä scrape-reddit.sh
#! / bin / bash
jos [ -z "$1" ]
sitten
echo "Määritä subreddit"
poistuminen 1
fi
SUBREDDIT = $ 1
NYT = $ (päivämäärä + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
kihara -s -A "bash-kaavinta-aiheet" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.lapset | . [] | .data.title, .data.url, .data.permalink '| \
luettaessa -r TITLE; tehdä
read -r URL
lue -r PERMALINK
kaiku -e "{TITLE} dollaria \ t {URL} dollaria \ t {PERMALINK} dollaria" | tr --delete \ ">> {OUTPUT_FILE} dollaria
tehty
Tämä komentosarja tarkistaa ensin, onko käyttäjä antanut subreddit-nimen. Jos ei, se poistuu virheilmoituksella ja nollasta poikkeavalla palautuskoodilla.
Seuraavaksi se tallentaa ensimmäisen argumentin subreddit-nimeksi ja rakentaa päivämäärällä leimatun tiedostonimen, johon lähtö tallennetaan.
Toiminta alkaa, kun
kiemura
kutsutaan mukautetulla otsikolla ja kaapattavan subredditin URL-osoitteella. Lähtö johdetaan
jq
missä se on jäsennelty ja supistettu kolmeen kenttään: Otsikko, URL ja Permalink. Nämä rivit luetaan, yksi kerrallaan, ja tallennetaan muuttujaan käyttämällä komentoa read, kaikki jonkin aikaa silmukan sisällä, joka jatkuu, kunnes enää ei ole enää luettavia rivejä. Sisäisen samalla lohkon viimeinen rivi toistaa kolme kenttää, jotka on erotettu sarkainmerkillä, ja vie sen sitten läpi
tr
komento niin, että lainausmerkit voidaan poistaa. Tulos liitetään sitten tiedostoon.
Ennen kuin voimme suorittaa tämän komentosarjan, meidän on varmistettava, että sille on annettu suoritusoikeudet. Käytä
chmod
komento soveltaa näitä oikeuksia tiedostoon:
chmod u + x scrape-reddit.sh
Lopuksi suorita komentosarja subbreddit-nimellä:
./scrape-reddit.sh Lievästi mielenkiintoinen
Lähtötiedosto luodaan sama hakemisto ja sen sisältö näyttää tältä:

Jokainen rivi sisältää seuraavat kolme kenttää, jotka on erotettu sarkainmerkillä.
Mennä kauemmas
Reddit on mielenkiintoisen sisällön ja median kultakaivos, ja siihen pääsee helposti JSON-sovellusliittymän avulla. Nyt kun sinulla on tapa käyttää näitä tietoja ja käsitellä tuloksia, voit tehdä esimerkiksi:
- Tartu viimeisimmät otsikot / r / WorldNews -sivustolta ja lähetä ne työpöydällesi käyttämällä ilmoita-lähetä
- Integroi / r / DadJokesin parhaat vitsit järjestelmän päivän viestiin
- Hanki tämän päivän paras kuva hakemistosta / r / aww ja tee siitä työpöydän tausta
Kaikki tämä on mahdollista toimittamiesi tietojen ja järjestelmässäsi olevien työkalujen avulla. Hyvää hakkerointia!




")


