Redditは、各subredditのJSONフィードを提供します。好きなsubredditから投稿のリストをダウンロードして解析するBashスクリプトを作成する方法は次のとおりです。これは、RedditのJSONフィードで実行できることの1つにすぎません。
CurlとJQのインストール
使用します
カール
RedditからJSONフィードをフェッチして
jq
JSONデータを解析し、結果から必要なフィールドを抽出します。を使用してこれら2つの依存関係をインストールします
apt-get
Ubuntuおよびその他のDebianベースのLinuxディストリビューション。他のLinuxディストリビューションでは、代わりにディストリビューションのパッケージ管理ツールを使用してください。
sudo apt-get install curl jq
RedditからJSONデータを取得する
データフィードがどのように見えるか見てみましょう。使用する
カール
から最新の投稿を取得するには
ややおもしろい
subreddit:
curl -s-「redditスクレーパーの例」https://www.reddit.com/r/MildlyInteresting.json
URLの前に使用されているオプションに注意してください。
-s
強制的にcurlをサイレントモードで実行し、Redditのサーバーからのデータ以外の出力が表示されないようにします。次のオプションとそれに続くパラメータ、
-「redditスクレーパーの例」
、Redditがデータにアクセスするサービスを識別するのに役立つカスタムユーザーエージェント文字列を設定します。 Reddit APIサーバーは、ユーザーエージェント文字列に基づいてレート制限を適用します。カスタム値を設定すると、Redditはレート制限を他の呼び出し元からセグメント化し、HTTP429レート制限超過エラーが発生する可能性を減らします。
出力はターミナルウィンドウを埋め、次のようになります。
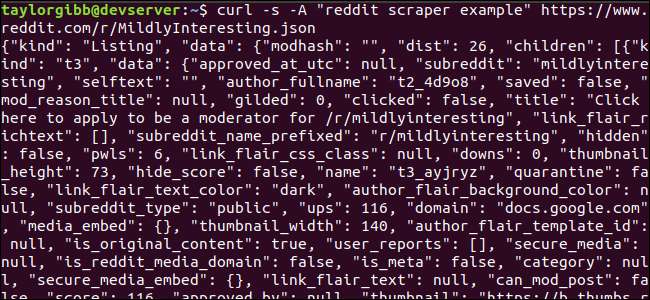
出力データには多くのフィールドがありますが、関心があるのはタイトル、パーマリンク、およびURLだけです。 RedditのAPIドキュメントページで、タイプとそのフィールドの完全なリストを確認できます。 hっtps://ぎてゅb。こm/れっぢtーあrちゔぇ/れっぢt/うぃき/Jそん
JSON出力からのデータの抽出
出力データからタイトル、パーマリンク、およびURLを抽出し、タブ区切りファイルに保存します。次のようなテキスト処理ツールを使用できます
そして
そして
グリップ
、しかし、JSONデータ構造を理解する別のツールがあります。
jq
。最初の試みとして、これを使用して出力をきれいに印刷し、色分けしてみましょう。以前と同じ呼び出しを使用しますが、今回は出力をパイプします
jq
JSONデータを解析して印刷するように指示します。
curl -s-「redditスクレーパーの例」https://www.reddit.com/r/MildlyInteresting.json | jq。
コマンドに続く期間に注意してください。この式は、入力を解析してそのまま出力するだけです。出力は適切にフォーマットされ、色分けされているように見えます。
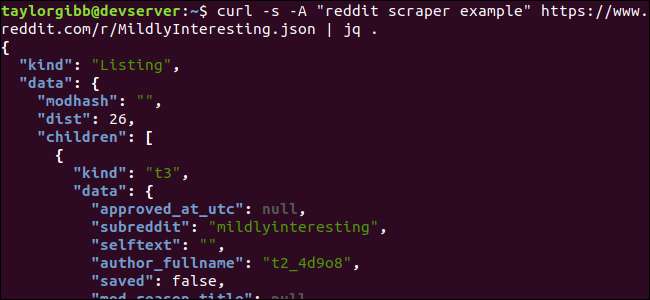
Redditから取得したJSONデータの構造を調べてみましょう。ルート結果は、kindとdataの2つのプロパティを含むオブジェクトです。後者はと呼ばれるプロパティを保持します
子供達
、このsubredditへの投稿の配列が含まれています。
配列の各項目は、kindとdataという2つのフィールドも含むオブジェクトです。取得するプロパティはデータオブジェクトにあります。
jq
入力データに適用でき、目的の出力を生成できる式が必要です。階層と配列のメンバーシップ、およびデータの変換方法の観点からコンテンツを記述する必要があります。正しい式を使用して、コマンド全体をもう一度実行してみましょう。
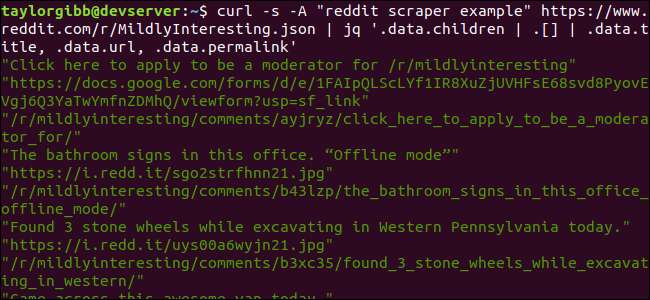
curl -s-「redditスクレーパーの例」https://www.reddit.com/r/MildlyInteresting.json | jq‘.data.children | 。[] | .data.title、.data.url、.data.permalink ’
出力には、タイトル、URL、パーマリンクがそれぞれ独自の行に表示されます。
に飛び込みましょう
jq
私たちが呼び出したコマンド:
jq‘.data.children | 。[] | .data.title、.data.url、.data.permalink ’
このコマンドには、2つのパイプ記号で区切られた3つの式があります。各式の結果は、さらに評価するために次の式に渡されます。最初の式は、Redditリストの配列を除くすべてを除外します。この出力は2番目の式にパイプされ、配列に強制されます。 3番目の式は、配列の各要素に作用し、3つのプロパティを抽出します。についての詳細
jq
そしてその式の構文はで見つけることができます
jqの公式マニュアル
。
すべてを1つのスクリプトにまとめる
API呼び出しとJSON後処理をスクリプトにまとめて、必要な投稿を含むファイルを生成しましょう。 / r / MildlyInterestingだけでなく、任意のsubredditから投稿をフェッチするためのサポートを追加します。
エディターを開き、このスニペットの内容をscrape-reddit.shというファイルにコピーします
#!/ bin / bash
[ -z "$1" ]の場合
その後
echo "subredditを指定してください"
出口1
fi
SUBREDDIT = $ 1
NOW = $(日付+ "%m_%d_%y-%H_%M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq'.data.children | 。[] | .data.title、.data.url、.data.permalink '| \
-rTITLEを読みながら;行う
-rURLを読む
読む-rパーマリンク
echo -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> $ {OUTPUT_FILE}
完了
このスクリプトは、最初にユーザーがsubreddit名を指定したかどうかを確認します。そうでない場合は、エラーメッセージとゼロ以外のリターンコードで終了します。
次に、最初の引数をsubreddit名として保存し、出力が保存される日付スタンプ付きのファイル名を作成します。
アクションは次のときに始まります
カール
カスタムヘッダーとスクレイプするsubredditのURLを使用して呼び出されます。出力はにパイプされます
jq
ここで解析され、タイトル、URL、パーマリンクの3つのフィールドに縮小されます。これらの行は一度に1つずつ読み取られ、readコマンドを使用して変数に保存されます。すべてwhileループ内で、読み取る行がなくなるまで続行されます。内側のwhileブロックの最後の行は、タブ文字で区切られた3つのフィールドをエコーし、パイプでつなぎます。
tr
二重引用符を削除できるようにコマンドを実行します。次に、出力がファイルに追加されます。
このスクリプトを実行する前に、実行権限が付与されていることを確認する必要があります。使用
chmod
これらの権限をファイルに適用するコマンド:
chもd う+x scらぺーれっぢt。sh
そして最後に、subreddit名でスクリプトを実行します。
./scrape-reddit.shMildlyInteresting
出力ファイルは同じディレクトリで生成され、その内容は次のようになります。

各行には、タブ文字を使用して区切られた3つのフィールドが含まれています。
もっと遠く行く
Redditは興味深いコンテンツとメディアの宝庫であり、JSONAPIを使用してすべて簡単にアクセスできます。これで、このデータにアクセスして結果を処理する方法ができたので、次のようなことができます。
- / r / WorldNewsから最新のヘッドラインを取得し、を使用してデスクトップに送信します。 通知-送信
- / r / DadJokesの最高のジョークをシステムのMessage-Of-The-Dayに統合します
- / r / awwから今日の最高の写真を入手して、デスクトップの背景にします
これはすべて、提供されたデータとシステムにあるツールを使用して可能です。ハッピーハッキング!
")






