Reddit tilbyder JSON-feeds for hver subreddit. Sådan oprettes et Bash-script, der downloader og analyserer en liste med indlæg fra enhver subreddit, du kan lide. Dette er kun en ting, du kan gøre med Reddits JSON-feeds.
Installation af Curl og JQ
Vi skal bruge
krølle
at hente JSON-feedet fra Reddit og
jq
at analysere JSON-dataene og udtrække de felter, vi ønsker, fra resultaterne. Installer disse to afhængigheder ved hjælp af
apt-get
på Ubuntu og andre Debian-baserede Linux-distributioner. På andre Linux-distributioner skal du bruge din distributions pakkehåndteringsværktøj i stedet.
sudo apt-get install curl jq
Hent nogle JSON-data fra Reddit
Lad os se, hvordan datafeedet ser ud. Brug
krølle
for at hente de seneste indlæg fra
Mildt interessant
underreddit:
krølle -s -A “eksempel på reddit-skraber” https://www.reddit.com/r/MildlyInteresting.json
Bemærk, hvordan de muligheder, der blev brugt før URL:
-s
tvinger curl til at køre i lydløs tilstand, så vi ikke ser noget output undtagen data fra Reddits servere. Den næste mulighed og den følgende parameter,
-Et eksempel på "reddit scraper"
, indstiller en tilpasset brugeragentstreng, der hjælper Reddit med at identificere den service, der får adgang til deres data. Reddit API-serverne anvender hastighedsgrænser baseret på brugeragentstrengen. Indstilling af en brugerdefineret værdi får Reddit til at segmentere vores takstgrænse væk fra andre opkald og reducere chancen for, at vi får en HTTP 429 Rate Limit Exceeded error.
Outputtet skal udfylde terminalvinduet og se sådan ud:
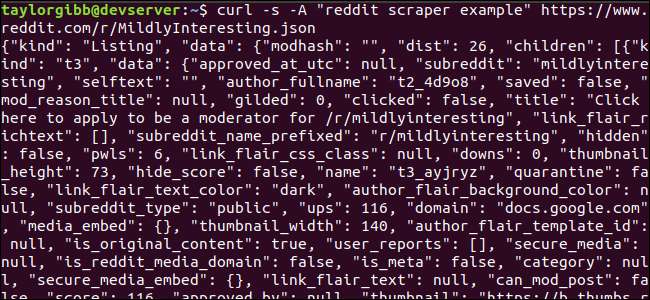
Der er mange felter i outputdataene, men alt hvad vi er interesseret i er titel, permalink og URL. Du kan se en udtømmende liste over typer og deres felter på Reddits API-dokumentationsside: https://github.com/reddit-archive/reddit/wiki/JSON
Uddrag af data fra JSON-output
Vi ønsker at udtrække titel, permalink og URL fra outputdataene og gemme dem i en tabulatorafgrænset fil. Vi kan bruge tekstbehandlingsværktøjer som f.eks
og
og
greb
, men vi har et andet værktøj til rådighed, der forstår JSON-datastrukturer, kaldet
jq
. Lad os bruge det til at udskrive og farvekode output for vores første forsøg. Vi bruger det samme opkald som før, men denne gang skal du gennemføre output
jq
og bede den om at analysere og udskrive JSON-data.
krølle -s -A “eksempel på reddit-skraber” https://www.reddit.com/r/MildlyInteresting.json | jq.
Bemærk den periode, der følger kommandoen. Dette udtryk analyserer simpelthen input og udskriver det som det er. Outputtet ser pænt formateret og farvekodet ud:
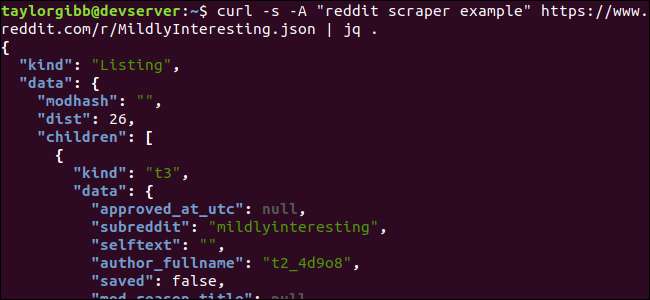
Lad os undersøge strukturen af JSON-dataene, vi får tilbage fra Reddit. Grundresultatet er et objekt, der indeholder to egenskaber: slags og data. Sidstnævnte har en ejendom, der kaldes
børn
, som inkluderer en række indlæg til denne underredit.
Hvert element i arrayet er et objekt, der også indeholder to felter kaldet kind og data. De egenskaber, vi ønsker at få fat i, er i dataobjektet.
jq
forventer et udtryk, der kan anvendes på inputdataene og producerer det ønskede output. Den skal beskrive indholdet med hensyn til deres hierarki og medlemskab til en matrix samt hvordan dataene skal transformeres. Lad os køre hele kommandoen igen med det rigtige udtryk:
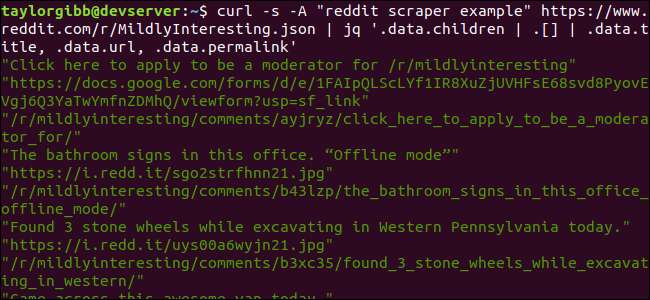
krølle -s -A “eksempel på reddit-skraber” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.børn | . [] | .data.title, .data.url, .data.permalink ’
Outputtet viser titel, URL og Permalink hver på deres egen linje:
Lad os dykke ned i
jq
kommando, vi kaldte:
jq ‘.data.børn | . [] | .data.title, .data.url, .data.permalink ’
Der er tre udtryk i denne kommando adskilt af to rørsymboler. Resultaterne af hvert udtryk overføres til det næste til yderligere evaluering. Det første udtryk filtrerer alt undtagen udvalget af Reddit-lister ud. Denne output ledes ind i det andet udtryk og tvinges ind i en matrix. Det tredje udtryk virker på hvert element i arrayet og udtrækker tre egenskaber. Flere oplysninger om
jq
og dets udtrykssyntaks kan findes i
jqs officielle manual
.
At sætte det hele sammen i et script
Lad os sætte API-opkaldet og JSON-efterbehandlingen sammen i et script, der genererer en fil med de stillinger, vi ønsker. Vi tilføjer support til at hente indlæg fra enhver subreddit, ikke kun / r / MildlyInteresting.
Åbn din editor og kopier indholdet af dette uddrag til en fil kaldet scrape-reddit.sh
#! / bin / bash
hvis [ -z "$1" ]
derefter
ekko "Angiv en subreddit"
afkørsel 1
fi
SUBREDDIT = $ 1
NU = $ (dato + "% m_% d_% y-% H_% M")
OUTPUT_FILE = "$ {SUBREDDIT}_ $ {NOW}.txt"
krølle -s -A "bash-skrabe-emner" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.børn | . [] | .data.title, .data.url, .data.permalink '| \
mens du læser -r TITLE; gør
læse -r URL
læs -r PERMALINK
ekko -e "$ {TITLE} \ t $ {URL} \ t $ {PERMALINK}" | tr --delete \ ">> $ {OUTPUT_FILE}
Færdig
Dette script kontrollerer først, om brugeren har angivet et subreddit-navn. Hvis ikke, afsluttes den med en fejlmeddelelse og en returkode, der ikke er nul.
Derefter gemmer det det første argument som subreddit-navnet og opbygger et datostemplet filnavn, hvor output gemmes.
Handlingen begynder når
krølle
kaldes med et brugerdefineret header og URL'en til subreddit til at skrabe. Outputtet ledes til
jq
hvor den er analyseret og reduceret til tre felter: Titel, URL og Permalink. Disse linjer læses en ad gangen og gemmes i en variabel ved hjælp af læsekommandoen, alt sammen inde i en stund-løkke, der fortsætter, indtil der ikke er flere linjer at læse. Den sidste linje i den indre, mens blokken gentager de tre felter, afgrænset af et faneblad, og rør derefter den gennem
tr
kommandoen, så dobbelt-citaterne kan fjernes. Outputtet føjes derefter til en fil.
Før vi kan udføre dette script, skal vi sikre os, at det har fået udført tilladelser. Brug
chmod
kommando til at anvende disse tilladelser til filen:
chmod u + x scrape-reddit.sh
Og endelig udfør scriptet med et subreddit-navn:
./scrape-reddit.sh MildlyInteresting
En outputfil genereres i den samme mappe, og dens indhold ser sådan ud:

Hver linje indeholder de tre felter, vi leder efter, adskilt ved hjælp af et fanetegn.
Går videre
Reddit er en guldgruve med interessant indhold og medier, og det er let tilgængeligt ved hjælp af dets JSON API. Nu hvor du har en måde at få adgang til disse data og behandle resultaterne, kan du gøre ting som:
- Grib de nyeste overskrifter fra / r / WorldNews, og send dem til dit skrivebord ved hjælp af underret-send
- Integrer de bedste vittigheder fra / r / DadJokes i dit systems Message-Of-The-Day
- Få dagens bedste billede fra / r / aww, og gør det til din skrivebordsbaggrund
Alt dette er muligt ved hjælp af de leverede data og de værktøjer, du har på dit system. Glad hacking!
?")






