
1 Eylül 2020'de NVIDIA, yeni oyun GPU serisini açıkladı: Amper mimarisine dayanan RTX 3000 serisi. Yenilikleri, onunla birlikte gelen yapay zeka destekli yazılımı ve bu nesli gerçekten harika kılan tüm ayrıntıları tartışacağız.
RTX 3000 Serisi GPU'larla tanışın

NVIDIA’nın ana duyurusu, tümü özel bir 8 nm üretim sürecine dayanan ve tümü hem rasterleştirme hem de Işın izleme verim.
Dizinin alt ucunda, RTX 3070 , 499 dolardan geliyor. İlk duyuruda NVIDIA tarafından açıklanan en ucuz kart için biraz pahalı, ancak düzenli olarak 1400 $ 'ın üzerinde perakende satış yapan en üst düzey kart olan mevcut RTX 2080 Ti'yi geçtiğini öğrendiğinizde mutlak bir çalma oluyor. Bununla birlikte, NVIDIA'nın duyurusundan sonra, üçüncü tarafların satış fiyatı düştü ve bunların büyük bir kısmı eBay'de 600 doların altında panik olarak satıldı.
Duyuru itibariyle sağlam bir kıyaslama yok, dolayısıyla kartın olup olmadığı belli değil Gerçekten mi 2080 Ti'den nesnel olarak "daha iyi" veya NVIDIA pazarlamayı biraz döndürüyorsa. Ampere tabanlı 3000 serisi, ışın izlemede Turing'e göre iki kat daha iyi performans göstereceğinden, çalıştırılan kıyaslamalar 4K'daydı ve muhtemelen RTX açıktı, bu da boşluğu tamamen rasterleştirilmiş oyunlarda olduğundan daha büyük gösterebilir. Ancak, ışın izleme artık performansa çok fazla zarar vermeyen bir şey olduğundan ve en yeni nesil konsollarda desteklendiğinden, fiyatın neredeyse üçte biri için son neslin amiral gemisi kadar hızlı çalışması önemli bir satış noktası.
Ayrıca fiyatın bu şekilde kalıp kalmayacağı da belirsiz. Üçüncü taraf tasarımları düzenli olarak fiyat etiketine en az 50 ABD doları ekler ve talebin ne kadar yüksek olacağı düşünüldüğünde, Ekim 2020'de 600 ABD dolarına satıldığını görmek şaşırtıcı olmayacaktır.
Bunun hemen üstünde RTX 3080 RTX 2080'den iki kat daha hızlı olması gereken 699 $ 'da ve 3080'den yaklaşık% 25-30 daha hızlı geliyor.
Ardından, en üstte, yeni amiral gemisi, RTX 3090 , komik olarak çok büyük. NVIDIA bunun farkındadır ve şirket tarafından "Büyük Vahşi GPU" anlamına gelen "BFGPU" olarak adlandırılır.

NVIDIA herhangi bir doğrudan performans ölçütü göstermedi, ancak şirket bunun çalıştığını gösterdi 8K 60 FPS'de oyunlar, bu gerçekten etkileyici. Verilmiş, NVIDIA neredeyse kesinlikle kullanıyor DLSS bu hedefi vurmak için, ancak 8K oyun 8K oyun.
Elbette, sonunda bir 3060 ve daha bütçe odaklı kartların diğer varyasyonları olacaktır, ancak bunlar genellikle daha sonra gelir.
İşleri gerçekten soğutmak için NVIDIA'nın yenilenmiş bir soğutucu tasarımına ihtiyacı vardı. 3080, oldukça yüksek olan 320 watt olarak derecelendirilmiştir, bu nedenle NVIDIA bir çift fan tasarımını seçmiştir, ancak her iki fan altta vwinf yerleştirmek yerine, NVIDIA arka plakanın genellikle gittiği üst uca bir fan koymuştur. Fan, havayı yukarı doğru CPU soğutucusuna ve kasanın üstüne yönlendirir.

Bir durumda kötü hava akışından ne kadar performansın etkilenebileceğine bakıldığında, bu çok mantıklı. Bununla birlikte, devre kartı bu nedenle çok sıkışıktır ve bu muhtemelen üçüncü taraf satış fiyatlarını etkileyecektir.
DLSS: Bir Yazılım Avantajı
Işın izleme, bu yeni kartların tek avantajı değil. Gerçekten, hepsi biraz hack'tir — RTX 2000 serisi ve 3000 serisi o eski nesil kartlara kıyasla gerçek ışın izleme yapmakta çok daha iyi. Blender gibi bir 3D yazılımda tam bir sahneyi izlemek genellikle kare başına birkaç saniye veya hatta dakika sürer, bu nedenle 10 milisaniyenin altında kaba kuvvet uygulamak söz konusu değildir.
Elbette, ışın hesaplamalarını çalıştırmak için RT çekirdekleri adı verilen özel bir donanım var, ancak NVIDIA büyük ölçüde farklı bir yaklaşımı seçti. NVIDIA, GPU'ların korkunç görünen çok ucuz bir tek geçişi oluşturmasına ve bir şekilde yapay zeka büyüsü aracılığıyla bunu bir oyuncunun bakmak istediği bir şeye dönüştürmesine olanak tanıyan gürültü azaltma algoritmalarını geliştirdi. Geleneksel rasterleştirme tabanlı tekniklerle birleştirildiğinde, ışın izleme efektleriyle zenginleştirilmiş hoş bir deneyim sağlar.

Ancak, bunu hızlı bir şekilde yapmak için NVIDIA, Tensor çekirdekleri adı verilen yapay zekaya özgü işlem çekirdeklerini ekledi. Bunlar, makine öğrenimi modellerini çalıştırmak için gereken tüm matematiği işler ve bunu çok hızlı bir şekilde yapar. Toplam bulut sunucu alanında yapay zeka için ezber bozan AI, birçok şirket tarafından yaygın olarak kullanıldığından.
Gürültü azaltmanın ötesinde, oyuncular için Tensor çekirdeklerinin ana kullanımına DLSS veya derin öğrenme süper örnekleme adı verilir. Düşük kaliteli bir çerçeve alır ve bunu tam yerel kaliteye yükseltir. Bu, esasen 4K resme bakarken 1080p seviye kare hızlarıyla oyun oynayabileceğiniz anlamına gelir.
Bu aynı zamanda ışın izleme performansına oldukça yardımcı olur. PCMag'den karşılaştırmalar bir RTX 2080 Super koşu göster Kontrol ultra kalitede, tüm ışın izleme ayarları maks. 4K'da yalnızca 19 FPS ile mücadele ediyor, ancak DLSS açıkken çok daha iyi 54 FPS alıyor. DLSS, Turing ve Ampere üzerindeki Tensor çekirdekleriyle mümkün kılınan NVIDIA için ücretsiz performanstır. Bunu destekleyen ve GPU ile sınırlı olan herhangi bir oyun, yalnızca yazılımdan ciddi hızlanmalar görebilir.
DLSS yeni değildir ve iki yıl önce RTX 2000 serisi piyasaya sürüldüğünde bir özellik olarak duyurulmuştu. O zamanlar, NVIDIA'nın her bir oyun için bir makine öğrenimi modelini eğitmesi ve ayarlaması gerektiğinden çok az oyun tarafından destekleniyordu.
Ancak, o zaman, NVIDIA tamamen yeniden yazdı ve yeni DLSS 2.0 sürümünü çağırdı. Bu genel amaçlı bir API'dir, yani herhangi bir geliştiricinin onu uygulayabileceği anlamına gelir ve çoğu büyük sürüm tarafından zaten kullanılmaktadır. Tek bir kare üzerinde çalışmak yerine, TAA'ya benzer şekilde önceki kareden hareket vektörü verilerini alır. Sonuç, DLSS 1.0'dan çok daha keskin ve bazı durumlarda, aslında daha iyi ve yerel çözünürlükten bile daha keskin, bu yüzden onu açmamak için fazla bir neden yok.
Bir yakalama var - sahneleri tamamen değiştirirken, ara sahnelerde olduğu gibi, DLSS 2.0, hareket vektörü verilerini beklerken ilk kareyi% 50 kalitede oluşturmalıdır. Bu, birkaç milisaniye için kalitede küçük bir düşüşe neden olabilir. Ancak, baktığınız her şeyin% 99'u düzgün bir şekilde işlenecek ve çoğu insan bunu pratikte fark etmeyecek.
İLİŞKİLİ: NVIDIA DLSS Nedir ve Işın İzlemeyi Nasıl Daha Hızlı Hale Getirir?
Amper Mimarisi: Yapay Zeka İçin Üretildi
Amper hızlıdır. Özellikle AI hesaplamalarında son derece hızlı. RT çekirdeği Turing'den 1.7 kat daha hızlıdır ve yeni Tensor çekirdeği Turing'den 2.7 kat daha hızlıdır. İkisinin kombinasyonu, ışın izleme performansında gerçek bir nesil sıçramasıdır.

Mayıs ayı başlarında, NVIDIA, Ampere A100 GPU'yu piyasaya sürdü , AI çalıştırmak için tasarlanmış bir veri merkezi GPU'su. Bununla birlikte, Ampere'yi bu kadar hızlı yapan birçok şeyi detaylandırdılar. Veri merkezi ve yüksek performanslı bilgi işlem iş yükleri için, Ampere genel olarak Turing'den yaklaşık 1,7 kat daha hızlıdır. Yapay zeka eğitimi için 6 kata kadar daha hızlıdır.
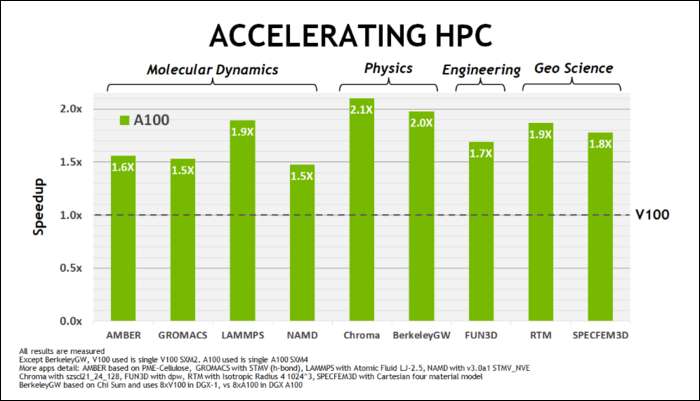
NVIDIA, Ampere ile bazı iş yüklerinde endüstri standardı olan "Floating-Point 32" veya FP32'nin yerini alacak şekilde tasarlanmış yeni bir sayı biçimi kullanıyor. Kısacası, bilgisayarınızın işlediği her sayı, ister 8 bit, 16 bit, 32, 64 veya daha büyük olsun, bellekte önceden tanımlanmış sayıda bit kaplar. Daha büyük sayıların işlenmesi daha zordur, bu nedenle daha küçük bir boyut kullanırsanız, daha az ezmeniz gerekir.
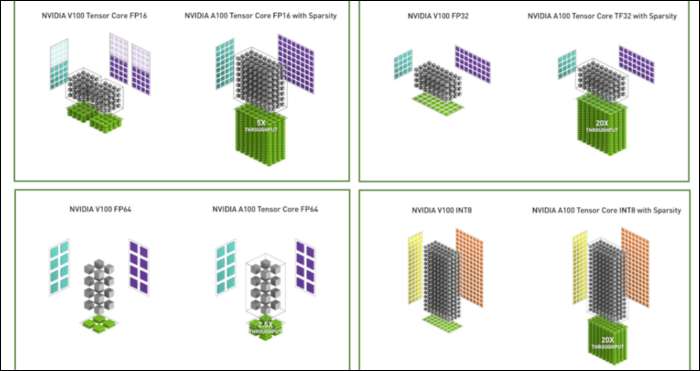
FP32, 32 bitlik bir ondalık sayı depolar ve sayı aralığı için (ne kadar büyük veya küçük olabilir) 8 bit ve hassasiyet için 23 bit kullanır. NVIDIA’nın iddiası, bu 23 hassas bitin birçok AI iş yükü için tamamen gerekli olmadığı ve bunlardan yalnızca 10 tanesinden benzer sonuçlar ve çok daha iyi performans elde edebileceğinizdir. Boyutu 32 yerine 19 bit'e düşürmek, birçok hesaplamada büyük bir fark yaratır.
Bu yeni formata Tensor Float 32 adı verilir ve A100'deki Tensor Çekirdekleri, garip boyuttaki formatı işlemek için optimize edilmiştir. Bu, kalıp küçülmelerinin ve çekirdek sayısının artmasının yanı sıra, yapay zeka eğitiminde devasa 6 kat hızlanmayı nasıl elde ettikleri.

Yeni sayı formatının yanı sıra Ampere, FP32 ve FP64 gibi belirli hesaplamalarda önemli performans artışları görüyor. Bunlar, meslekten olmayanlar için doğrudan daha fazla FPS'ye dönüştürülmez, ancak Tensor operasyonlarında genel olarak neredeyse üç kat daha hızlı olmasını sağlayan şeyin bir parçasıdır.
Ardından, hesaplamaları daha da hızlandırmak için şu kavramını tanıttılar: ince taneli yapılı seyreklik , oldukça basit bir konsept için çok süslü bir kelime. Sinir ağları, nihai çıktıyı etkileyen, ağırlık adı verilen büyük sayı listeleri ile çalışır. Ne kadar çok sayı kırılırsa o kadar yavaş olur.
Ancak, bu sayıların hepsi aslında yararlı değildir. Bazıları kelimenin tam anlamıyla sıfırdır ve temelde atılabilir, bu da aynı anda daha fazla sayı kırabildiğinizde büyük hızlanmalara yol açar. Seyreklik, esasen sayıları sıkıştırır, bu da hesaplamaları yapmak için daha az çaba gerektirir. Yeni "Seyrek Tensör Çekirdeği" sıkıştırılmış veriler üzerinde çalışmak üzere oluşturulmuştur.
Değişikliklere rağmen NVIDIA, bunun eğitimli modellerin doğruluğunu fark edilir şekilde etkilememesi gerektiğini söylüyor.
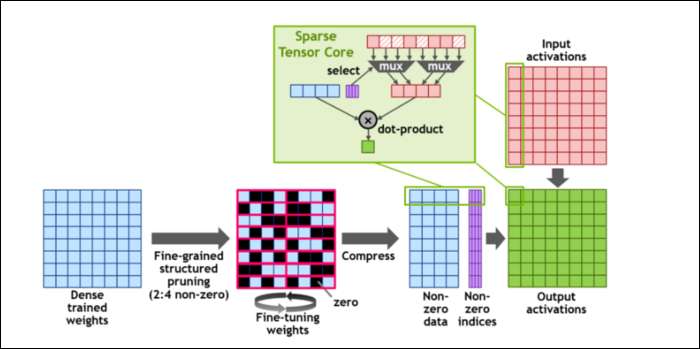
En küçük sayı biçimlerinden biri olan Seyrek INT8 hesaplamaları için tek bir A100 GPU'nun en yüksek performansı, şaşırtıcı derecede yüksek bir sayı olan 1.25 PetaFLOP'un üzerindedir. Elbette, bu yalnızca belirli bir sayı türünü hesaplarken geçerlidir, ancak yine de etkileyici.







