
1 сентября 2020 года NVIDIA представила новую линейку игровых графических процессоров: серию RTX 3000, основанную на архитектуре Ampere. Мы обсудим, что нового, программное обеспечение на базе искусственного интеллекта, которое поставляется с ним, и все детали, которые делают это поколение действительно потрясающим.
Встречайте графические процессоры серии RTX 3000

Основным объявлением NVIDIA стали блестящие новые графические процессоры, все построенные по индивидуальному 8-нм производственному процессу и обеспечивающие значительное ускорение как растеризации, так и трассировка лучей спектакль.
В нижней части модельного ряда есть RTX 3070 , который стоит 499 долларов. Это немного дороже для самой дешевой карты, представленной NVIDIA при первом анонсе, но это будет абсолютная кража, если вы узнаете, что она превосходит существующую RTX 2080 Ti, лучшую линейную карту, которая регулярно продавалась по цене более 1400 долларов. Однако после объявления NVIDIA цена сторонних продаж упала, и многие из них панически продаются на eBay по цене менее 600 долларов.
На момент анонса нет никаких надежных тестов, поэтому неясно, подходит ли карта действительно объективно «лучше», чем 2080 Ti, или если NVIDIA немного искажает маркетинг. Тесты проводились в разрешении 4K и, вероятно, имели RTX, что может сделать разрыв больше, чем он будет в чисто растеризованных играх, поскольку серия 3000 на основе Ampere будет работать при трассировке лучей в два раза лучше, чем Turing. Но теперь, когда трассировка лучей не сильно влияет на производительность и поддерживается в консолях последнего поколения, важным преимуществом является то, что она работает так же быстро, как флагман прошлого поколения, почти за треть цены.
Также неясно, останется ли цена такой. Сторонние разработки регулярно добавляют к цене не менее 50 долларов, и с учетом того, насколько высок будет спрос, неудивительно, что в октябре 2020 года они будут продаваться за 600 долларов.
Чуть выше находится RTX 3080 по цене 699 долларов, что должно быть в два раза быстрее, чем RTX 2080, и примерно на 25-30% быстрее, чем 3080.
Затем, в верхней части, новый флагман - это RTX 3090 , что до смешного огромно. NVIDIA хорошо осведомлена об этом и назвала это «BFGPU», что, по словам компании, означает «Big Ferocious GPU».

NVIDIA не показала никаких прямых показателей производительности, но компания показала, что они работают. 8K игры со скоростью 60 FPS, что серьезно впечатляет. Конечно, NVIDIA почти наверняка использует DLSS чтобы попасть в эту отметку, но игры 8K - это игры 8K.
Конечно, в конечном итоге будет 3060 и другие варианты более бюджетных карт, но они обычно появляются позже.
Чтобы действительно круто, NVIDIA потребовался обновленный дизайн кулера. 3080 рассчитан на 320 Вт, что довольно много, поэтому NVIDIA выбрала дизайн с двумя вентиляторами, но вместо обоих вентиляторов vwinf, размещенных снизу, NVIDIA установила вентилятор на верхнем конце, где обычно находится задняя панель. Вентилятор направляет воздух вверх к кулеру процессора и верхней части корпуса.

Судя по тому, насколько на производительность может повлиять плохой воздушный поток в корпусе, это имеет смысл. Однако из-за этого на печатной плате очень мало места, что, вероятно, повлияет на розничные цены сторонних производителей.
DLSS: преимущество программного обеспечения
Трассировка лучей - не единственное преимущество этих новых карт. На самом деле, все это немного похоже на хакерство - серии RTX 2000 и серии 3000 не являются который гораздо лучше справляется с трассировкой лучей по сравнению с картами более старых поколений. Трассировка лучей всей сцены в программном обеспечении 3D, таком как Blender, обычно занимает несколько секунд или даже минут на кадр, поэтому о грубом форсировании менее 10 миллисекунд не может быть и речи.
Конечно, есть специальное оборудование для выполнения вычислений лучей, называемое ядрами RT, но в основном NVIDIA выбрала другой подход. NVIDIA улучшила алгоритмы шумоподавления, которые позволяют графическим процессорам воспроизводить очень дешевый одиночный проход, который выглядит ужасно, и каким-то образом - с помощью магии ИИ - превращать это в то, на что геймер хочет взглянуть. В сочетании с традиционными методами, основанными на растеризации, это дает приятные впечатления, усиленные эффектами трассировки лучей.

Однако, чтобы сделать это быстро, NVIDIA добавила ядра обработки для ИИ, называемые ядрами Tensor. Они обрабатывают всю математику, необходимую для запуска моделей машинного обучения, и делают это очень быстро. Они всего кардинальное изменение для ИИ в области облачных серверов , так как ИИ широко используется многими компаниями.
Помимо шумоподавления, основное использование ядер Tensor для геймеров называется DLSS или суперсэмплингом глубокого обучения. Он берет кадр низкого качества и масштабирует его до полного исходного качества. По сути, это означает, что вы можете играть с частотой кадров 1080p, глядя на изображение 4K.
Это также немного улучшает производительность трассировки лучей - тесты из PCMag показать RTX 2080 Super работает Контроль с ультра качеством, со всеми настройками трассировки лучей, установленными на максимум. В 4K он борется только с 19 FPS, но с DLSS он получает намного лучше 54 FPS. DLSS - это бесплатная производительность для NVIDIA, которая стала возможной благодаря ядрам Tensor на процессорах Turing и Ampere. Любая игра, которая поддерживает его и ограничена графическим процессором, может получить серьезное ускорение только за счет программного обеспечения.
DLSS - не новость, и она была объявлена как функция, когда два года назад была запущена серия RTX 2000. В то время он поддерживался очень небольшим количеством игр, так как NVIDIA требовала от NVIDIA обучения и настройки модели машинного обучения для каждой отдельной игры.
Однако за это время NVIDIA полностью переписала его, назвав новую версию DLSS 2.0. Это универсальный API, что означает, что любой разработчик может его реализовать, и он уже используется в большинстве основных выпусков. Вместо того, чтобы работать с одним кадром, он берет данные вектора движения из предыдущего кадра, аналогично TAA. Результат намного резче, чем DLSS 1.0, и в некоторых случаях действительно выглядит лучше и резче, чем обычное разрешение, поэтому нет особых причин не включать его.
Есть одна загвоздка - при полном переключении сцен, как в кат-сценах, DLSS 2.0 должен рендерить самый первый кадр с качеством 50%, ожидая данных вектора движения. Это может привести к небольшому снижению качества на несколько миллисекунд. Но 99% всего, на что вы смотрите, будет обработано правильно, и большинство людей не замечают этого на практике.
СВЯЗАННЫЕ С: Что такое NVIDIA DLSS и как это ускорит трассировку лучей?
Архитектура Ampere: создана для ИИ
Ампер быстр. Очень быстро, особенно при расчетах AI. Ядро RT в 1,7 раза быстрее, чем Turing, а новое ядро Tensor в 2,7 раза быстрее, чем Turing. Сочетание этих двух факторов - настоящий скачок в производительности трассировки лучей для поколений.

Ранее в мае NVIDIA выпустила графический процессор Ampere A100 , графический процессор центра обработки данных, предназначенный для запуска ИИ. В нем они подробно описали многое из того, что делает Ampere намного быстрее. Для рабочих нагрузок центров обработки данных и высокопроизводительных вычислений Ampere в целом примерно в 1,7 раза быстрее, чем Turing. Для обучения ИИ это до 6 раз быстрее.
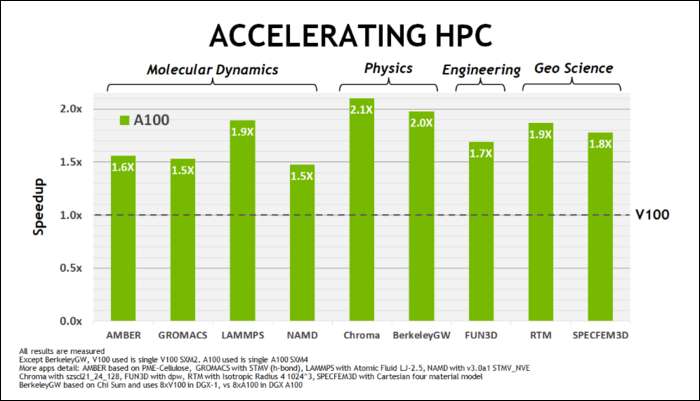
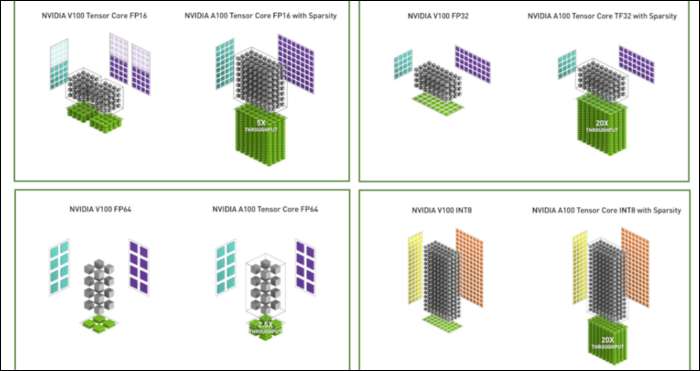
В Ampere NVIDIA использует новый числовой формат, предназначенный для замены стандартного формата «32 с плавающей запятой» или FP32 в некоторых рабочих нагрузках. Под капотом каждое число, обрабатываемое вашим компьютером, занимает определенное количество бит в памяти, будь то 8 бит, 16 бит, 32, 64 или даже больше. Числа большего размера сложнее обрабатывать, поэтому, если вы можете использовать меньший размер, вам придется меньше обрабатывать.
FP32 хранит 32-битное десятичное число и использует 8 бит для диапазона числа (насколько большим или маленьким оно может быть) и 23 бита для точности. NVIDIA утверждает, что эти 23 бита точности не совсем необходимы для многих рабочих нагрузок ИИ, и вы можете получить аналогичные результаты и гораздо лучшую производительность всего с 10 из них. Уменьшение размера до 19 бит вместо 32 имеет большое значение для многих вычислений.
Этот новый формат называется Tensor Float 32, а тензорные ядра в A100 оптимизированы для обработки формата странного размера. Благодаря этому, помимо уменьшения размеров кристаллов и увеличения количества ядер, они получают шестикратное ускорение обучения ИИ.

Помимо нового числового формата, Ampere видит значительное увеличение производительности в определенных вычислениях, таких как FP32 и FP64. Для непрофессионала это не означает прямого увеличения FPS, но это часть того, что делает его почти в три раза быстрее при работе с Tensor.
Затем, чтобы еще больше ускорить вычисления, они представили концепцию мелкозернистая структурированная разреженность , что очень красивое слово для довольно простой концепции. Нейронные сети работают с большими списками чисел, называемыми весами, которые влияют на конечный результат. Чем больше чисел нужно обработать, тем медленнее будет.
Однако не все эти числа на самом деле полезны. Некоторые из них буквально равны нулю, и их можно просто выбросить, что приводит к значительному ускорению, когда вы можете обрабатывать больше чисел одновременно. Разреженность существенно сжимает числа, что требует меньше усилий для проведения расчетов. Новое «Разреженное тензорное ядро» создано для работы со сжатыми данными.
Несмотря на изменения, NVIDIA заявляет, что это вообще не должно заметно влиять на точность обученных моделей.
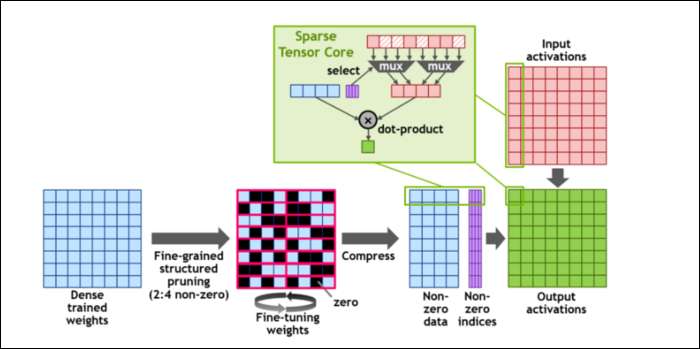
Для вычислений Sparse INT8, одного из форматов наименьших чисел, пиковая производительность одного графического процессора A100 составляет более 1,25 петафлопс, что является ошеломляюще высоким показателем. Конечно, это только при вычислении одного определенного числа, но, тем не менее, это впечатляет.
 лучшую механическую клавиатуру для вас")



 в спящий режим")


