
Pada tanggal 1 September 2020, NVIDIA mengungkapkan jajaran baru dari GPU gaming: seri RTX 3000, berdasarkan arsitektur Ampere mereka. Kami akan membahas apa yang baru, perangkat lunak yang didukung AI, dan semua detail yang membuat generasi ini benar-benar mengagumkan.
Perkenalkan GPU Seri RTX 3000

Pengumuman utama NVIDIA adalah GPU barunya yang mengilap, semua dibangun di atas proses manufaktur kustom 8 nm, dan semuanya membawa percepatan besar dalam rasterisasi dan ray-tracing kinerja.
Di barisan paling bawah, ada RTX 3070 , yang harganya $ 499. Ini agak mahal untuk kartu termurah yang diluncurkan oleh NVIDIA pada pengumuman awal, tetapi itu benar-benar mencuri setelah Anda mengetahui bahwa itu mengalahkan RTX 2080 Ti yang ada, kartu top of the line yang secara teratur dijual seharga lebih dari $ 1400. Namun, setelah pengumuman NVIDIA, harga penjualan pihak ketiga turun, dengan sejumlah besar penjualan panik di eBay dengan harga di bawah $ 600.
Tidak ada tolok ukur yang solid pada pengumuman tersebut, jadi tidak jelas apakah kartunya benar Betulkah secara obyektif “lebih baik” daripada 2080 Ti, atau jika NVIDIA sedikit memutarbalikkan pemasaran. Tolok ukur yang dijalankan berada pada 4K dan kemungkinan memiliki RTX, yang dapat membuat celah terlihat lebih besar daripada di game yang murni raster, karena seri 3000 berbasis Ampere akan tampil dua kali lebih baik pada penelusuran sinar daripada Turing. Namun, dengan ray tracing kini menjadi sesuatu yang tidak terlalu mengganggu performa, dan didukung oleh generasi konsol terbaru, itu adalah nilai jual utama untuk menjalankannya secepat andalan generasi terakhir dengan hampir sepertiga dari harga.
Juga tidak jelas apakah harganya akan tetap seperti itu. Desain pihak ketiga secara teratur menambahkan setidaknya $ 50 ke label harga, dan dengan seberapa tinggi permintaan kemungkinan akan terjadi, tidak mengherankan melihatnya dijual seharga $ 600 pada Oktober 2020.
Tepat di atas itu adalah RTX 3080 dengan $ 699, yang seharusnya dua kali lebih cepat dari RTX 2080, dan datang sekitar 25-30% lebih cepat dari 3080.
Kemudian, di ujung atas, andalan baru adalah RTX 3090 , yang sangat lucu. NVIDIA sangat sadar, dan menyebutnya sebagai "BFGPU", yang menurut perusahaan adalah singkatan dari "Big Ferocious GPU".

NVIDIA tidak memamerkan metrik kinerja langsung apa pun, tetapi perusahaan menunjukkannya berjalan 8K game di 60 FPS, yang sangat mengesankan. Memang, NVIDIA hampir pasti menggunakan DLSS untuk mencapai sasaran itu, tetapi game 8K adalah game 8K.
Tentu saja, pada akhirnya akan ada 3060, dan variasi lain dari kartu yang lebih berorientasi anggaran, tetapi biasanya muncul kemudian.
Untuk benar-benar mendinginkannya, NVIDIA membutuhkan desain yang lebih keren. Seri 3080 memiliki daya 320 watt, yang cukup tinggi, jadi NVIDIA memilih desain kipas ganda, tetapi alih-alih kedua kipas vwinf ditempatkan di bagian bawah, NVIDIA telah meletakkan kipas di ujung atas tempat pelat belakang biasanya dipasang. Kipas mengarahkan udara ke atas menuju pendingin CPU dan bagian atas casing.

Menilai dari seberapa besar kinerja dapat dipengaruhi oleh aliran udara yang buruk dalam sebuah case, ini sangat masuk akal. Namun, papan sirkuit sangat sempit karena hal ini, yang kemungkinan besar akan memengaruhi harga jual pihak ketiga.
DLSS: Keunggulan Perangkat Lunak
Penelusuran sinar bukan satu-satunya keuntungan dari kartu baru ini. Sungguh, itu semua sedikit retas — seri RTX 2000 dan seri 3000 bukan bahwa jauh lebih baik dalam melakukan penelusuran sinar sebenarnya, dibandingkan dengan kartu generasi sebelumnya. Ray menelusuri adegan penuh dalam perangkat lunak 3D seperti Blender biasanya membutuhkan beberapa detik atau bahkan menit per bingkai, jadi memaksa dalam waktu kurang dari 10 milidetik adalah tidak mungkin.
Tentu saja, terdapat perangkat keras khusus untuk menjalankan kalkulasi sinar, yang disebut RT core, tetapi sebagian besar, NVIDIA memilih pendekatan yang berbeda. NVIDIA meningkatkan algoritme denoising, yang memungkinkan GPU membuat single pass yang sangat murah yang terlihat mengerikan, dan entah bagaimana — melalui keajaiban AI — mengubahnya menjadi sesuatu yang ingin dilihat oleh seorang gamer. Ketika dikombinasikan dengan teknik berbasis rasterisasi tradisional, ini membuat pengalaman menyenangkan ditingkatkan dengan efek raytracing.

Namun, untuk melakukan ini dengan cepat, NVIDIA telah menambahkan inti pemrosesan khusus AI yang disebut inti Tensor. Ini memproses semua matematika yang diperlukan untuk menjalankan model pembelajaran mesin, dan melakukannya dengan sangat cepat. Mereka total game-changer untuk AI di ruang server cloud , karena AI digunakan secara luas oleh banyak perusahaan.
Selain denoising, penggunaan utama inti Tensor untuk pemain game disebut DLSS, atau super sampling deep learning. Dibutuhkan dalam bingkai kualitas rendah dan meningkatkannya ke kualitas asli penuh. Ini pada dasarnya berarti Anda dapat bermain game dengan framerate level 1080p, sambil melihat gambar 4K.
Ini juga sedikit membantu kinerja ray-tracing— benchmark dari PCMag menunjukkan RTX 2080 Super berjalan Kontrol pada kualitas ultra, dengan semua pengaturan pelacakan sinar diputar secara maksimal. Pada 4K, ia berjuang dengan hanya 19 FPS, tetapi dengan DLSS aktif, ia mendapat 54 FPS yang jauh lebih baik. DLSS adalah performa gratis untuk NVIDIA, yang dimungkinkan oleh inti Tensor di Turing dan Ampere. Game apa pun yang mendukungnya dan dibatasi GPU dapat melihat percepatan yang serius hanya dari perangkat lunak saja.
DLSS bukanlah hal baru, dan diumumkan sebagai fitur saat seri RTX 2000 diluncurkan dua tahun lalu. Pada saat itu, hanya didukung oleh sedikit game, karena NVIDIA perlu melatih dan menyetel model pembelajaran mesin untuk setiap game.
Namun, pada saat itu, NVIDIA telah sepenuhnya menulis ulang, dengan menyebut versi baru DLSS 2.0. Ini adalah API tujuan umum, yang berarti setiap pengembang dapat menerapkannya, dan itu sudah digunakan oleh sebagian besar rilis utama. Alih-alih mengerjakan satu frame, ini mengambil data vektor bergerak dari frame sebelumnya, mirip dengan TAA. Hasilnya jauh lebih tajam daripada DLSS 1.0, dan dalam beberapa kasus, sebenarnya terlihat lebih baik dan lebih tajam daripada resolusi asli, jadi tidak banyak alasan untuk tidak mengaktifkannya.
Ada satu kendala — saat mengganti seluruh adegan, seperti dalam cutscene, DLSS 2.0 harus merender bingkai pertama dengan kualitas 50% sambil menunggu data vektor gerakan. Ini dapat menyebabkan penurunan kualitas kecil selama beberapa milidetik. Namun, 99% dari semua yang Anda lihat akan ditampilkan dengan benar, dan kebanyakan orang tidak menyadarinya dalam praktiknya.
TERKAIT: Apa itu NVIDIA DLSS, dan Bagaimana Cara Membuat Ray Tracing Lebih Cepat?
Arsitektur Ampere: Dibangun Untuk AI
Ampere cepat. Sangat cepat, terutama pada kalkulasi AI. Inti RT 1,7x lebih cepat daripada Turing, dan inti Tensor baru 2,7x lebih cepat daripada Turing. Kombinasi keduanya adalah lompatan generasi sejati dalam kinerja raytracing.

Awal Mei ini, NVIDIA merilis Ampere A100 GPU , GPU pusat data yang dirancang untuk menjalankan AI. Dengan itu, mereka merinci banyak hal yang membuat Ampere jauh lebih cepat. Untuk beban kerja komputasi pusat data dan kinerja tinggi, Ampere secara umum sekitar 1,7x lebih cepat daripada Turing. Untuk pelatihan AI, ini 6 kali lebih cepat.
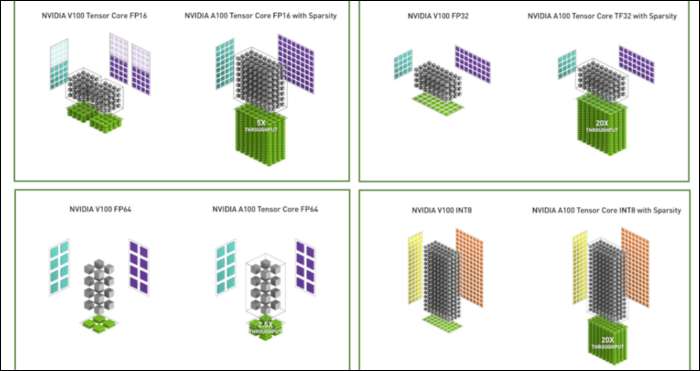
Dengan Ampere, NVIDIA menggunakan format angka baru yang dirancang untuk menggantikan "Floating-Point 32" atau FP32 standar industri, dalam beberapa beban kerja. Di balik terpal, setiap angka yang diproses komputer Anda membutuhkan jumlah bit yang telah ditentukan dalam memori, baik itu 8 bit, 16 bit, 32, 64, atau bahkan lebih besar. Angka yang lebih besar lebih sulit untuk diproses, jadi jika Anda dapat menggunakan ukuran yang lebih kecil, Anda tidak perlu repot.
FP32 menyimpan bilangan desimal 32-bit, dan menggunakan 8 bit untuk kisaran bilangan tersebut (seberapa besar atau kecilnya), dan 23 bit untuk presisi. Klaim NVIDIA adalah bahwa 23 bit presisi ini tidak sepenuhnya diperlukan untuk banyak beban kerja AI, dan Anda bisa mendapatkan hasil yang serupa dan kinerja yang jauh lebih baik hanya dari 10 bit tersebut. Mengurangi ukuran menjadi hanya 19 bit, bukan 32, membuat perbedaan besar di banyak perhitungan.
Format baru ini disebut Tensor Float 32, dan Tensor Cores di A100 dioptimalkan untuk menangani format berukuran aneh. Ini, di atas penyusutan dadu dan jumlah inti meningkat, bagaimana mereka mendapatkan percepatan 6x besar dalam pelatihan AI.

Di atas format angka baru, Ampere melihat percepatan kinerja utama dalam perhitungan tertentu, seperti FP32 dan FP64. Ini tidak secara langsung diterjemahkan ke lebih banyak FPS untuk orang awam, tetapi mereka adalah bagian dari apa yang membuatnya hampir tiga kali lebih cepat secara keseluruhan pada operasi Tensor.
Kemudian, untuk lebih mempercepat penghitungan, mereka telah memperkenalkan konsep ketersebaran terstruktur berbutir halus , yang merupakan kata yang sangat mewah untuk konsep yang cukup sederhana. Jaringan saraf bekerja dengan daftar angka yang besar, yang disebut bobot, yang memengaruhi hasil akhir. Semakin banyak angka yang diolah, semakin lambat jadinya.
Namun, tidak semua angka ini benar-benar berguna. Beberapa dari mereka benar-benar hanya nol, dan pada dasarnya dapat dibuang, yang mengarah ke percepatan besar ketika Anda dapat menghitung lebih banyak angka pada saat yang bersamaan. Ketersebaran pada dasarnya memampatkan angka, yang membutuhkan lebih sedikit upaya untuk melakukan penghitungan. "Sparse Tensor Core" baru dibuat untuk beroperasi pada data terkompresi.
Terlepas dari perubahan tersebut, NVIDIA mengatakan bahwa hal ini seharusnya tidak memengaruhi keakuratan model terlatih sama sekali.
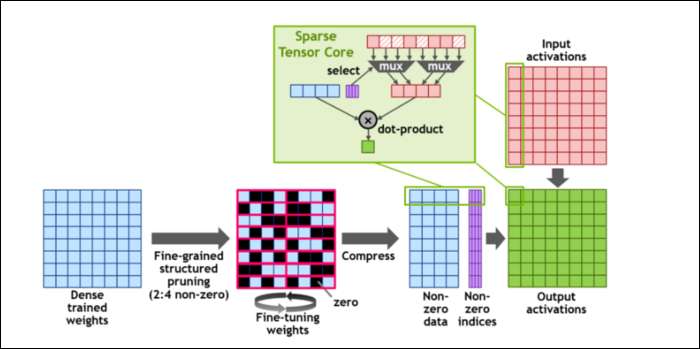
Untuk perhitungan Sparse INT8, salah satu format angka terkecil, performa puncak satu GPU A100 lebih dari 1,25 PetaFLOP, angka yang sangat tinggi. Tentu saja, itu hanya saat mengunyah satu jenis angka tertentu, tetapi tetap mengesankan.
")






