
1 सितंबर 2020 को, NVIDIA ने अपने एम्पीयर आर्किटेक्चर के आधार पर गेमिंग GPUs की अपनी नई लाइनअप: RTX 3000 श्रृंखला का खुलासा किया। हम चर्चा करेंगे कि नया, AI- संचालित सॉफ्टवेयर जो इसके साथ आता है, और इस पीढ़ी को वास्तव में भयानक बनाने वाले सभी विवरण।
RTX 3000 सीरीज GPU से मिलें

NVIDIA की मुख्य घोषणा इसकी चमकदार नई जीपीयू थी, जो सभी कस्टम 8 एनएम विनिर्माण प्रक्रिया पर बनाई गई थी, और सभी रास्टरकरण और दोनों में प्रमुख स्पीडअप में ला रहे थे। किरण पर करीबी नजर रखना प्रदर्शन।
लाइनअप के निचले सिरे पर, वहाँ है RTX 3070 , जो $ 499 में आता है। यह शुरुआती घोषणा में NVIDIA द्वारा अनावरण किए गए सबसे सस्ते कार्ड के लिए थोड़ा महंगा है, लेकिन यह जानने के लिए कि यह लाइन कार्ड के शीर्ष पर मौजूदा RTX 2080 तिवारी है, जो नियमित रूप से $ 1400 से अधिक के लिए रिटेल करता है, एक बार चोरी करता है। हालांकि, NVIDIA की घोषणा के बाद, तृतीय-पक्ष की बिक्री कम हो गई, जिसमें बड़ी संख्या में घबराहट ईबे पर $ 600 के तहत बेची गई।
घोषणा के अनुसार कोई ठोस बेंचमार्क नहीं है, इसलिए यह स्पष्ट नहीं है कि कार्ड क्या है वास्तव में उद्देश्यपूर्ण रूप से "बेहतर" 2080 तिवारी की तुलना में, या यदि NVIDIA विपणन को थोड़ा मोड़ रहा है। चलाए जा रहे बेंचमार्क 4K पर थे और संभवत: RTX चालू था, जो इस अंतर को बड़ा रूप दे सकता है, यह विशुद्ध रूप से रेखापुंज खेल में होगा, क्योंकि एम्पीयर-आधारित 3000 श्रृंखला ट्यूरिंग की तुलना में किरण अनुरेखण पर दो बार प्रदर्शन करेगी। लेकिन, रे ट्रेसिंग के साथ अब ऐसा कुछ हो रहा है जो प्रदर्शन को बहुत नुकसान नहीं पहुंचाता है, और नवीनतम पीढ़ी के कंसोल में समर्थित होने के कारण, यह एक प्रमुख विक्रय बिंदु है जो लगभग एक तिहाई कीमत के लिए अंतिम जीन के प्रमुख के रूप में तेजी से चल रहा है।
यह भी स्पष्ट नहीं है कि कीमत इस तरह रहेगी। थर्ड-पार्टी डिज़ाइन नियमित रूप से मूल्य टैग में कम से कम $ 50 जोड़ते हैं, और इसकी उच्च मांग की संभावना कैसे होगी, यह $ 600 अक्टूबर 2020 तक बिक्री के लिए इसे देखकर आश्चर्य नहीं होगा।
बस इतना ही ऊपर है RTX 3080 $ 699 पर, जो कि आरटीएक्स 2080 के मुकाबले दोगुना होना चाहिए, और 3080 की तुलना में लगभग 25-30% तेजी से आता है।
फिर, शीर्ष सिरे पर नया फ्लैगशिप है RTX 3090 , जो कि बहुत बड़ा है। NVIDIA अच्छी तरह से वाकिफ है, और इसे "BFGPU" के रूप में संदर्भित किया गया है, जिसे कंपनी का कहना है कि यह "बिग क्रूर जीपीयू" है।

NVIDIA ने कोई प्रत्यक्ष प्रदर्शन मैट्रिक्स नहीं दिखाया, लेकिन कंपनी ने इसे चालू दिखाया 8K 60 एफपीएस पर खेल, जो गंभीर रूप से प्रभावशाली है। दी, NVIDIA लगभग निश्चित रूप से उपयोग कर रहा है DLSS उस निशान को मारने के लिए, लेकिन 8K गेमिंग 8K गेमिंग है।
बेशक, अंत में 3060 और अधिक बजट उन्मुख कार्ड के अन्य रूपांतर होंगे, लेकिन वे आमतौर पर बाद में आते हैं।
वास्तव में चीजों को ठंडा करने के लिए, NVIDIA को एक नया कूलर डिजाइन की आवश्यकता थी। 3080 को 320 वाट के लिए रेट किया गया है, जो कि काफी अधिक है, इसलिए NVIDIA ने एक दोहरी प्रशंसक डिजाइन का विकल्प चुना है, लेकिन नीचे की ओर रखे गए दोनों प्रशंसकों के लिए vwinf के बजाय, NVIDIA ने शीर्ष छोर पर एक प्रशंसक लगाया है जहां आमतौर पर पीछे की प्लेट जाती है। प्रशंसक सीपीयू कूलर और मामले के शीर्ष की ओर हवा को ऊपर की ओर निर्देशित करता है।

किसी मामले में खराब एयरफ़्लो से कितना प्रदर्शन प्रभावित हो सकता है, यह देखते हुए, यह सही समझ में आता है। हालांकि, सर्किट बोर्ड इस वजह से बहुत तंग है, जो संभवतः तीसरे पक्ष की बिक्री की कीमतों को प्रभावित करेगा।
DLSS: एक सॉफ्टवेयर एडवांटेज
इन नए कार्डों का एकमात्र लाभ रे ट्रेसिंग नहीं है। वास्तव में, यह आरटीएक्स 2000 श्रृंखला और 3000 श्रृंखला के सभी हैक नहीं है उस कार्ड की पुरानी पीढ़ियों की तुलना में वास्तविक किरण अनुरेखण करने में बहुत बेहतर है। ब्लेंडर जैसे 3 डी सॉफ्टवेयर में एक पूर्ण दृश्य का पता लगाने में रे को आमतौर पर प्रति सेकंड कुछ सेकंड या प्रति मिनट लगते हैं, इसलिए 10 मिलीसेकेंड से कम आयु में यह क्रूरतापूर्ण प्रश्न से बाहर है।
बेशक, रे गणनाओं को चलाने के लिए समर्पित हार्डवेयर है, जिसे आरटी कोर कहा जाता है, लेकिन बड़े पैमाने पर, NVIDIA ने एक अलग दृष्टिकोण का विकल्प चुना। NVIDIA ने डीनोइजिंग एल्गोरिदम में सुधार किया, जो जीपीयू को बहुत ही सस्ते सिंगल पास को प्रस्तुत करने की अनुमति देता है, जो भयानक लगता है, और किसी भी तरह- एआई जादू के माध्यम से - एक ऐसी चीज में बदल जाता है जिसे एक गेमर देखना चाहता है। जब पारंपरिक रेखांकन-आधारित तकनीकों के साथ जोड़ा जाता है, तो यह किरणों के प्रभाव से बढ़े हुए सुखद अनुभव के लिए बनाता है।

हालाँकि, इस उपवास को करने के लिए, NVIDIA ने AI- विशिष्ट प्रसंस्करण कोर को Tensor cores कहा है। मशीन लर्निंग मॉडल को चलाने के लिए आवश्यक सभी गणित, और इसे बहुत जल्दी करते हैं। वे कुल हैं क्लाउड सर्वर स्पेस में AI के लिए गेम-चेंजर , क्योंकि AI का उपयोग कई कंपनियों द्वारा बड़े पैमाने पर किया जाता है।
निंदा से परे, गेमर्स के लिए टेन्सर कोर के मुख्य उपयोग को डीएलएसएस, या डीप लर्निंग सुपर सैंपलिंग कहा जाता है। यह कम गुणवत्ता वाले फ्रेम में होता है और इसे पूर्ण-देशी गुणवत्ता तक बढ़ा देता है। यह अनिवार्य रूप से मतलब है कि आप 4K तस्वीर को देखते हुए 1080p स्तर के फ्रैमरेट्स के साथ खेल सकते हैं।
यह किरण-अनुरेखण प्रदर्शन के साथ काफी मदद करता है- PCMag से मानदंड एक RTX 2080 सुपर दिखा रहा है नियंत्रण अल्ट्रा गुणवत्ता में, सभी किरण-अनुरेखण सेटिंग्स के साथ अधिकतम तक क्रैंक किया गया। 4K में, यह केवल 19 एफपीएस के साथ संघर्ष करता है, लेकिन डीएलएसएस के साथ, यह बहुत बेहतर 54 एफपीएस हो जाता है। डीएलएसएस, ट्यूरिंग और एम्पीयर पर टेन्सर कोर द्वारा संभव बनाया गया एनवीआईडीआईए के लिए नि: शुल्क प्रदर्शन है। कोई भी गेम जो इसका समर्थन करता है और GPU-limited है, अकेले सॉफ्टवेयर से गंभीर स्पीडअप देख सकता है।
DLSS नया नहीं है, और इसे एक सुविधा के रूप में घोषित किया गया था जब दो साल पहले RTX 2000 श्रृंखला शुरू की गई थी। उस समय, यह बहुत कम गेम द्वारा समर्थित था, क्योंकि इसमें प्रत्येक व्यक्तिगत गेम के लिए मशीन-लर्निंग मॉडल को प्रशिक्षित करने और ट्यून करने के लिए NVIDIA की आवश्यकता थी।
हालांकि, उस समय में, NVIDIA ने नए संस्करण DLSS 2.0 को कॉल करते हुए इसे पूरी तरह से फिर से लिखा है। यह एक सामान्य-उद्देश्य वाला एपीआई है, जिसका अर्थ है कि कोई भी डेवलपर इसे लागू कर सकता है, और इसे पहले से ही अधिकांश प्रमुख रिलीज द्वारा उठाया जा रहा है। एक फ्रेम पर काम करने के बजाय, यह पिछले फ्रेम से मोशन वेक्टर डेटा लेता है, उसी तरह टीएए के लिए भी। परिणाम DLSS 1.0 की तुलना में बहुत तेज है, और कुछ मामलों में, वास्तव में दिखता है बेहतर और मूल संकल्प की तुलना में तेज है, इसलिए इसे चालू नहीं करने का कोई कारण नहीं है।
एक कैच है- जब पूरी तरह से कटकनेसेस में दृश्य स्विच करते हैं, तो DLSS 2.0 को मोशन वेक्टर डेटा पर प्रतीक्षा करते समय 50% गुणवत्ता पर बहुत पहले फ्रेम को प्रस्तुत करना होगा। इसके परिणामस्वरूप कुछ मिलीसेकंड के लिए गुणवत्ता में एक छोटी सी गिरावट हो सकती है। लेकिन, आपके द्वारा देखी गई 99% चीजें ठीक से प्रदान की जाएंगी, और ज्यादातर लोग इसे व्यवहार में नहीं देखते हैं।
सम्बंधित: NVIDIA DLSS क्या है, और यह कैसे रे ट्रेसिंग को तेज़ करेगा?
एम्पीयर आर्किटेक्चर: एआई के लिए निर्मित
एम्पीयर तेज है। गंभीरता से तेजी से, विशेष रूप से एआई गणना पर। RT कोर ट्यूरिंग की तुलना में 1.7x तेज है, और नया Tensor Core ट्यूरिंग की तुलना में 2.7x तेज है। दो का संयोजन किरण प्रदर्शन में एक सच्ची पीढ़ीगत छलांग है।

इससे पहले मई, NVIDIA ने एम्पीयर ए 100 जीपीयू जारी किया , AI चलाने के लिए डिज़ाइन किया गया एक डेटा सेंटर GPU। इसके साथ, उन्होंने एंपियर को इतना तेज बनाने के लिए बहुत कुछ विस्तृत किया। डेटा-सेंटर और उच्च-प्रदर्शन कंप्यूटिंग वर्कलोड के लिए, एम्पीयर सामान्य रूप से ट्यूरिंग की तुलना में 1.7 गुना तेज है। एआई प्रशिक्षण के लिए, यह 6 गुना तक तेज है।
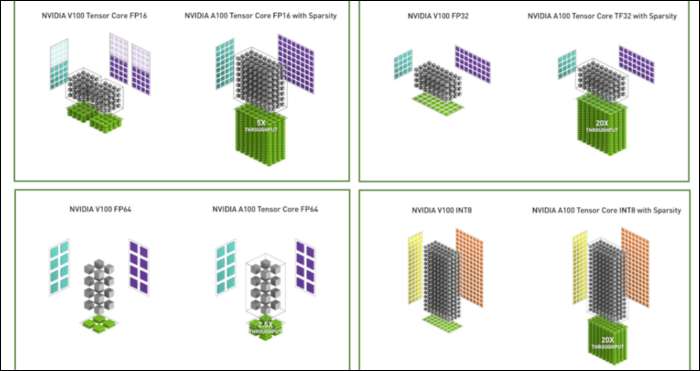
एम्पीयर के साथ, NVIDIA उद्योग-मानक "फ्लोटिंग-पॉइंट 32," या FP32 को बदलने के लिए डिज़ाइन किए गए एक नए नंबर प्रारूप का उपयोग कर रहा है, कुछ वर्कलोड में। हुड के तहत, आपके कंप्यूटर के हर नंबर में बिट्स की पूर्वनिर्धारित संख्या होती है, चाहे वह 8 बिट्स हो, 16 बिट्स, 32, 64, या इससे भी बड़ी हो। जो संख्याएँ बड़ी होती हैं, उन्हें संसाधित करना कठिन होता है, इसलिए यदि आप छोटे आकार का उपयोग कर सकते हैं, तो आपके पास कमी होगी।
FP32 एक 32-बिट दशमलव संख्या संग्रहीत करता है, और यह संख्या की सीमा के लिए 8 बिट्स का उपयोग करता है (यह कितना बड़ा या छोटा हो सकता है), और सटीक के लिए 23 बिट्स। एनवीआईडीआईए का दावा है कि ये 23 सटीक बिट्स पूरी तरह से कई एआई वर्कलोड के लिए आवश्यक नहीं हैं, और आप समान परिणाम प्राप्त कर सकते हैं और उनमें से सिर्फ 10 में से बेहतर प्रदर्शन कर सकते हैं। 32 के बजाय सिर्फ 19 बिट्स तक आकार को कम करना, कई गणनाओं में एक बड़ा अंतर बनाता है।
इस नए प्रारूप को Tensor Float 32 कहा जाता है, और A100 में Tensor Cores को अजीब आकार के प्रारूप को संभालने के लिए अनुकूलित किया गया है। यह मरने वाले श्रिंक और कोर काउंट में वृद्धि करता है, कैसे वे एआई प्रशिक्षण में बड़े पैमाने पर 6x स्पीडअप प्राप्त कर रहे हैं।

नए नंबर प्रारूप के शीर्ष पर, एम्पीयर विशिष्ट गणनाओं में प्रमुख प्रदर्शन गति को देख रहा है, जैसे कि एफपी 32 और एफपी 64। ये आम तौर पर आम आदमी के लिए अधिक एफपीएस का अनुवाद नहीं करते हैं, लेकिन वे जो भी करते हैं, उसका लगभग दस गुना अधिक तेजी से टेंसर संचालन में होता है।
फिर, गणना को और भी अधिक तेज़ करने के लिए, उन्होंने अवधारणा की शुरुआत की ठीक दानेदार संरचित विरलता , जो एक बहुत ही सरल अवधारणा के लिए एक बहुत ही फैंसी शब्द है। तंत्रिका नेटवर्क वजन की बड़ी सूची के साथ काम करते हैं, जिन्हें वेट कहा जाता है, जो अंतिम आउटपुट को प्रभावित करते हैं। क्रंच करने के लिए जितनी अधिक संख्या होगी, उतनी ही धीमी होगी।
हालाँकि, ये सभी संख्याएँ वास्तव में उपयोगी नहीं हैं। उनमें से कुछ सचमुच शून्य हैं, और मूल रूप से बाहर फेंक दिया जा सकता है, जो बड़े पैमाने पर स्पीडअप की ओर जाता है जब आप एक ही समय में अधिक संख्या में क्रंच कर सकते हैं। स्पार्सिटी अनिवार्य रूप से संख्याओं को संपीड़ित करता है, जिसके साथ गणना करने के लिए कम प्रयास लगते हैं। नया "स्पार्स टेन्सर कोर" कंप्रेस्ड डेटा पर काम करने के लिए बनाया गया है।
परिवर्तनों के बावजूद, NVIDIA का कहना है कि यह बिल्कुल प्रशिक्षित मॉडल की सटीकता को प्रभावित नहीं करना चाहिए।
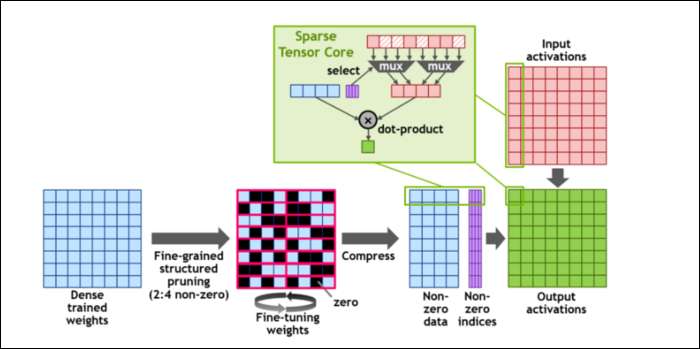
स्पार्स INT8 गणना के लिए, सबसे छोटी संख्या प्रारूपों में से एक, एक ए 100 जीपीयू का शिखर प्रदर्शन 1.25 पेटाफ्लॉप्स, एक कंपित रूप से उच्च संख्या है। बेशक, यह केवल तभी होता है जब एक विशिष्ट प्रकार की संख्या को क्रंच करते हैं, लेकिन फिर भी यह प्रभावशाली नहीं है।







