
1 вересня 2020 року NVIDIA представила свою нову лінійку ігрових графічних процесорів: серію RTX 3000, засновану на їхній архітектурі Ампера. Ми обговоримо, що нового, програмне забезпечення на основі штучного інтелекту, що поставляється в комплекті, та всі деталі, які роблять це покоління справді чудовим.
Зустріньте графічні процесори серії RTX 3000

Основним анонсом NVIDIA стали нові блискучі графічні процесори, всі вони побудовані на спеціальному виробничому процесі 8 нм, і всі вони забезпечують великі прискорення як у растеризації, так і в трасування променів продуктивність.
У нижньому кінці складу є RTX 3070 , який коштує 499 доларів. Це трохи дорожче для найдешевшої картки, яку NVIDIA представила під час першого анонсу, але це абсолютна викрадка, коли ви дізнаєтеся, що вона вибиває існуючу RTX 2080 Ti, верхню частину картки, яка регулярно продається за ціною понад 1400 доларів. Однак після оголошення NVIDIA ціни на сторонні продажі впали, і велика кількість з них у паніці продається на eBay за ціною менше 600 доларів.
На момент оголошення немає твердих тестів, тому незрозуміло, чи є ця картка справді об'єктивно "кращий", ніж 2080 Ti, або якщо NVIDIA трохи перекручує маркетинг. Бенчмарки, які запускали, були на рівні 4K, і, ймовірно, увімкнули RTX, що може зробити розрив вигляд більшим, ніж це буде в чисто растеризованих іграх, оскільки серія 3000 на базі Ampere буде працювати вдвічі краще за трасування променів, ніж Turing. Але, оскільки відстеження променів зараз є чимось, що не заважає продуктивності, і що підтримується в консолях останнього покоління, важливою точкою продажу є його робота так само швидко, як флагман останнього покоління, майже на третину ціни.
Також незрозуміло, чи залишиться ціна такою. Сторонні дизайни регулярно додають до цінника щонайменше 50 доларів, і з урахуванням того, наскільки високим буде попит, не буде дивно, що його продаж за 600 доларів відбудеться в жовтні 2020 року.
Якраз над цим знаходиться RTX 3080 на $ 699, що має бути вдвічі швидше, ніж RTX 2080, і прийти приблизно на 25-30% швидше, ніж 3080.
Тоді, у верхній частині, новий флагман - це RTX 3090 , що комічно величезне. NVIDIA це добре знає і називає його "BFGPU", що, за словами компанії, означає "Big Ferocious GPU".

NVIDIA не показала жодних прямих показників продуктивності, але компанія показала, що вона працює 8 тис гри на 60 кадрів в секунду, що є серйозним враженням. Звичайно, NVIDIA майже напевно використовує DLSS щоб досягти цієї позначки, але 8K ігор - це 8K ігор.
Звичайно, з часом буде 3060 та інші варіанти більш бюджетних карток, але вони, як правило, з’являються пізніше.
Щоб насправді охолодити ситуацію, NVIDIA потребувала оновленого дизайну кулера. 3080 розрахований на 320 Вт, що є досить високим показником, тому NVIDIA зупинила свій вибір на подвійному дизайні вентилятора, але замість обох вентиляторів vwinf, розміщених внизу, NVIDIA поставила вентилятор на верхньому кінці, куди зазвичай йде задня пластина. Вентилятор спрямовує повітря вгору до кулера процесора та верхньої частини корпусу.

Судячи з того, наскільки потужність може вплинути на поганий потік повітря у футлярі, це цілком логічно. Однак друкована плата через це дуже тісна, що, ймовірно, вплине на ціни продажу інших виробників.
DLSS: Перевага програмного забезпечення
Трасування променів - не єдина перевага цих нових карток. Справді, це все трохи зламано - серії RTX 2000 та 3000 не є що набагато краще виконувати фактичну трасування променів у порівнянні зі старішими поколіннями карток. Промінь відслідковує повну сцену в програмному забезпеченні 3D, як Blender, зазвичай займає кілька секунд або навіть хвилин на кадр, тож примусове використання грубого тексту за 10 мілісекунд не може бути й мови.
Звичайно, існує спеціальне обладнання для запуску променевих обчислень, яке називається ядрами RT, але в основному NVIDIA обрала інший підхід. NVIDIA вдосконалила алгоритми шумозаглушення, які дозволяють графічним процесорам робити дуже дешевий одиночний прохід, який виглядає жахливо, і якимось чином - за допомогою магії ШІ - перетворює це на щось, на що хоче подивитися геймер. У поєднанні з традиційними методами, заснованими на растеризації, це створює приємні враження, покращені ефектами трасування променів.

Однак, щоб зробити це швидко, NVIDIA додала специфічні для штучного інтелекту ядра обробки, які називаються ядрами Tensor. Вони обробляють всю математику, необхідну для запуску моделей машинного навчання, і роблять це дуже швидко. Вони загальні чейнджер для ШІ в хмарному просторі серверів , оскільки ШІ широко використовується багатьма компаніями.
Окрім шуму, основне використання ядер Tensor для геймерів називається DLSS, або глибоке вивчення супер вибірки. Він приймає низькоякісний кадр і підвищує його до повноцінної якості. Це по суті означає, що ви можете грати з частотою кадрів 1080p, переглядаючи зображення 4K.
Це також трохи допомагає в роботі з трасуванням променів - тести від PCMag показати RTX 2080 Super running Контроль в надвисокій якості, з усіма налаштуваннями трасування променів, максимально скрученими У 4K він бореться лише з 19 FPS, але при включеному DLSS він отримує набагато кращі 54 FPS. DLSS - це безкоштовна продуктивність для NVIDIA, яка стала можливою завдяки ядрам Tensor на Turing та Ampere. Будь-яка гра, яка її підтримує і обмежена графічним процесором, може бачити серйозні прискорення лише за допомогою програмного забезпечення.
DLSS не є новиною і була анонсована як особливість, коли серія RTX 2000 стартувала два роки тому. На той час це підтримувалося дуже мало ігор, оскільки для цього потрібно було, щоб NVIDIA навчила та налаштувала модель машинного навчання для кожної окремої гри.
Однак у той час NVIDIA повністю переписала його, назвавши нову версію DLSS 2.0. Це загальний API, що означає, що будь-який розробник може його реалізувати, і його вже підхоплюють більшість основних версій. Замість того, щоб працювати над одним кадром, він приймає векторні дані руху з попереднього кадру, подібно до TAA. Результат набагато чіткіший, ніж DLSS 1.0, і в деяких випадках насправді виглядає краще і чіткіше, ніж навіть рідна роздільна здатність, тому немає великих причин не вмикати її.
Є одна фішка - при повністю перемиканні сцен, як у кадрах, DLSS 2.0 повинен робити перший кадр із 50% якістю, очікуючи на дані вектора руху. Це може призвести до крихітного зниження якості на кілька мілісекунд. Але 99% усього, що ви дивитесь, буде зроблено належним чином, і більшість людей цього не помічають на практиці.
ПОВ'ЯЗАНІ: Що таке NVIDIA DLSS і як це зробить трасування променів швидшим?
Архітектура Ампера: побудована для штучного інтелекту
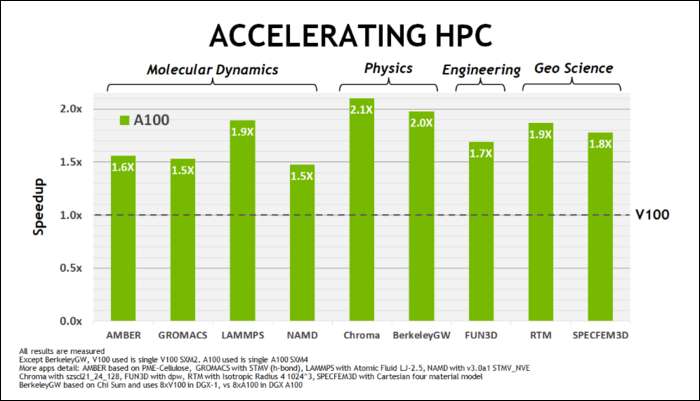
Ампер швидкий. Серйозно швидко, особливо під час обчислень ШІ. Ядро RT в 1,7 рази швидше, ніж Тьюрінг, а нове ядро Tensor в 2,7 рази швидше, ніж Тьюрінг. Поєднання цих двох є справжнім стрибком поколінь у характеристиках трасування променів.

Раніше цього травня, NVIDIA випустила графічний процесор Ampere A100 , графічний процесор центру обробки даних, призначений для запуску AI. З його допомогою вони деталізували багато того, що робить Ампер набагато швидшим. Для робочих навантажень для центрів обробки даних та високопродуктивних обчислень Ампер загалом приблизно в 1,7 рази швидший, ніж Тьюрінг. Навчання ШІ до 6 разів швидше.
З Ampere NVIDIA використовує новий формат чисел, призначений для заміни галузевого стандарту «Плаваюча точка 32» або FP32 в деяких робочих навантаженнях. Під капотом кожне число, яке обробляє ваш комп’ютер, займає заздалегідь визначену кількість бітів у пам’яті, будь то 8 біт, 16 бітів, 32, 64 або навіть більше. Числа, більші, обробляти складніше, тому, якщо ви можете використовувати менший розмір, вам буде менше хрустувати.
FP32 зберігає 32-розрядне десяткове число, і воно використовує 8 бітів для діапазону числа (наскільки великим або малим воно може бути), і 23 біти для точності. Твердження NVIDIA полягає в тому, що ці 23 біти точності не є абсолютно необхідними для багатьох робочих навантажень ШІ, і ви можете отримати подібні результати та набагато кращу продуктивність лише з 10 з них. Зменшення розміру до лише 19 біт, замість 32, має велике значення для багатьох обчислень.
Цей новий формат називається Tensor Float 32, а ядра Tensor в A100 оптимізовані для обробки формату дивних розмірів. Це, на додачу до усадки штампа та збільшення кількості ядер, те, як вони отримують величезне 6-кратне прискорення у навчанні ШІ.

Окрім нового формату чисел, Ampere спостерігає значні прискорення продуктивності в конкретних розрахунках, таких як FP32 та FP64. Вони безпосередньо не перекладаються на більшу кількість кадрів у секунду для непрофесіоналів, але вони є частиною того, що робить це майже втричі швидшим в цілому в операціях Tensor.
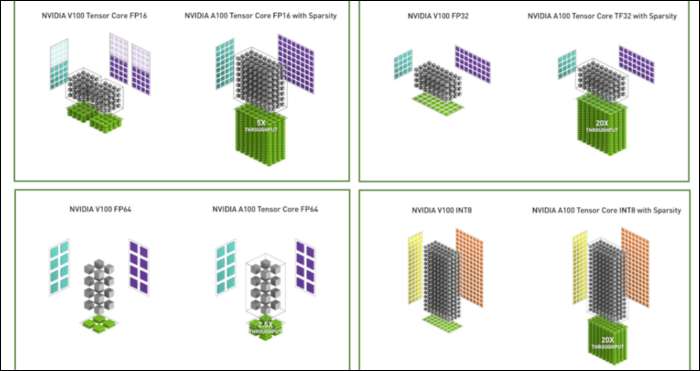
Потім, щоб ще більше пришвидшити обчислення, вони ввели поняття дрібнозерниста структурована розрідженість , що є дуже вигадливим словом для досить простої концепції. Нейронні мережі працюють з великими списками чисел, званими вагами, які впливають на кінцевий результат. Чим більше цифр буде хрустіти, тим повільніше це буде.
Однак не всі ці цифри насправді корисні. Деякі з них буквально просто нульові і в основному можуть бути викинуті, що призводить до масових прискорень, коли ви можете одночасно розчавити більше чисел. Розрідженість по суті стискає цифри, для обчислення яких потрібно менше зусиль. Нове “Розріджене ядро тензора” створено для роботи зі стиснутими даними.
Незважаючи на зміни, NVIDIA заявляє, що це взагалі не повинно помітно впливати на точність навчених моделей.
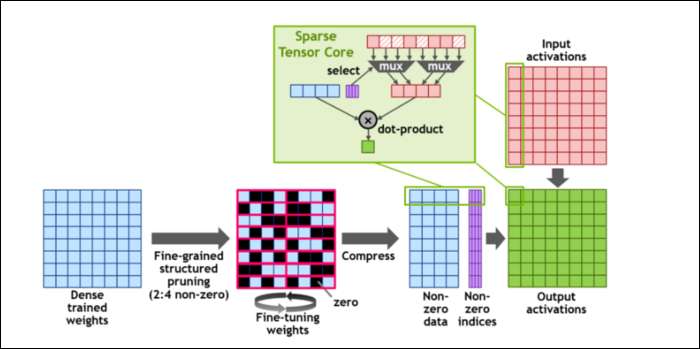
Для розріджених обчислень INT8, одного з найменших форматів чисел, пікова продуктивність одного графічного процесора A100 перевищує 1,25 PetaFLOP, що надзвичайно велике число. Звичайно, це лише при подрібненні одного конкретного виду числа, але тим не менш це вражає.







