
2020. szeptember 1-jén az NVIDIA bemutatta új gaming GPU -inak felsorolását: az RTX 3000 sorozatot, Ampere architektúrájuk alapján. Megbeszéljük az újdonságokat, a hozzá tartozó mesterséges intelligenciával működő szoftvert és minden részletet, ami igazán fantasztikussá teszi ezt a generációt.
Ismerje meg az RTX 3000 sorozatú GPU-kat

Az NVIDIA legfőbb bejelentése a fényes új GPU-k voltak, amelyek mind egyedi 8 nm-es gyártási folyamatra épültek, és mindez jelentős gyorsításokat hozott mind a raszterizálás, mind a sugárkövetés teljesítmény.
A felsorolás alsó végén ott van a RTX 3070 , ami 499 dollárba kerül. Kicsit drága a legolcsóbb kártya esetében, amelyet az NVIDIA mutatott be az eredeti bejelentéskor, de abszolút lopás, ha megtudja, hogy legyőzi a meglévő RTX 2080 Ti-t, a vonal tetején található kártyát, amelyet rendszeresen több mint 1400 dollárért vásárolnak. Az NVIDIA bejelentése után azonban a harmadik fél eladási árai csökkentek, nagy részük pánikba esett az eBay-en 600 dollár alatt.
A bejelentés óta nincsenek szilárd referenciaértékek, ezért nem világos, hogy a kártya van-e igazán objektíven „jobb”, mint egy 2080-as Ti, vagy ha az NVIDIA kissé megforgatja a marketinget. A futtatott referenciaértékek 4K-n voltak, és valószínűleg bekapcsolták az RTX-et, ami nagyobbnak tűnhet a résnél, mint amennyi a tisztán raszterizált játékokban lesz, mivel az Ampere-alapú 3000-es sorozat kétszer olyan jól fog teljesíteni a sugárkövetésben, mint a Turing. De mivel a sugárkövetés ma már nem károsítja a teljesítményt, és a legújabb generációs konzolok támogatják, fontos eladási pont, hogy az ár csaknem egyharmadával ugyanolyan gyorsan fut, mint az utolsó gen zászlóshajója.
Az sem világos, hogy az ár ilyen marad-e. A harmadik féltől származó tervek rendszeresen hozzáadnak legalább 50 dollárt az árcédulához, és hogy mennyire lesz nagy a kereslet, nem meglepő, ha azt látjuk, hogy 2020 dollárért 600 dollárért árulják.
Éppen ezen felül van a RTX 3080 699 dollárért, amelynek kétszer olyan gyorsnak kell lennie, mint az RTX 2080-nak, és körülbelül 30-30% -kal gyorsabban be kell jönnie, mint a 3080-as.
Aztán a felső végén az új zászlóshajó a RTX 3090 , ami komikusan óriási. Az NVIDIA tisztában van vele, és „BFGPU” néven emlegette, amely a vállalat szerint a „Big Ferocious GPU” rövidítése.

Az NVIDIA nem mutatott semmilyen közvetlen teljesítménymutatót, de a vállalat azt mutatta, hogy fut 8K játékok 60 kép / mp sebességgel, ami komolyan lenyűgöző. Bizony, az NVIDIA szinte biztosan használja DLSS hogy elérje ezt a határt, de a 8K játék 8K játék.
Természetesen végül lesz egy 3060-as, és más változatok a költségvetés-orientáltabb kártyákból, de ezek általában később érkeznek.
Ahhoz, hogy valóban lehűtse a dolgokat, az NVIDIA-nak megújult hűvösebb kialakításra volt szüksége. A 3080 névleges teljesítménye 320 watt, ami meglehetősen magas, ezért az NVIDIA a kettős ventilátor kialakítását választotta, de az aljára helyezett mindkét vwinf ventilátor helyett az NVIDIA egy ventilátort helyezett a felső végére, ahová általában a hátlap jár. A ventilátor felfelé irányítja a levegőt a processzor hűtője és a ház teteje felé.

Annak megítélése, hogy az esetleges teljesítményt mennyire befolyásolhatja a rossz légáramlás, ennek tökéletes értelme van. Az áramköri lap azonban emiatt nagyon szűkös, ami valószínűleg befolyásolja a harmadik felek eladási árait.
DLSS: Szoftverelőny
A sugárkövetés nem az egyetlen előnye ezeknek az új kártyáknak. Tényleg, ez egy kicsit hack - az RTX 2000 sorozat és a 3000 sorozat nem az hogy sokkal jobban tudja elvégezni a tényleges sugárkövetést, mint a kártyák idősebb generációi. A teljes jelenet leképezése a 3D-s szoftverekben, mint például a Blender, képkockánként általában néhány másodpercet vagy akár percet is igénybe vesz, így a durva kényszerítés 10 milliszekundum alatt nem jöhet szóba.
Természetesen van egy dedikált hardver a sugárszámítások futtatásához, az úgynevezett RT magok, de nagyrészt az NVIDIA más megközelítést választott. Az NVIDIA továbbfejlesztette a denoising algoritmusokat, amelyek lehetővé teszik a GPU-k számára, hogy nagyon olcsó egyszeri átadást nyújtsanak, ami szörnyen néz ki, és valahogy - az AI varázslatán keresztül - olyanná változtatja, amit a játékosok meg akarnak nézni. A hagyományos raszterezésen alapuló technikákkal kombinálva kellemes élményt nyújt a sugárkövetési hatásokkal.

Ennek gyors végrehajtásához azonban az NVIDIA felvette az AI-specifikus feldolgozó magokat, az úgynevezett Tensor magokat. Ezek feldolgozzák a gépi tanulási modellek futtatásához szükséges összes matematikát, és ezt nagyon gyorsan elvégzik. Összesen játékváltó az AI számára a felhő kiszolgálón , mivel az AI-t sok vállalat széles körben használja.
A denoizáláson túl a Tensor magok fő alkalmazását a játékosok számára DLSS-nek vagy mély tanulási szuper mintavételnek hívják. Alacsony minőségű keretet vesz fel, és teljes natív minőségre emeli. Ez lényegében azt jelenti, hogy 1080p szintű képkocka-sebességgel játszhat, miközben 4K képet néz.
Ez is sokat segít a sugárkövetési teljesítményben - referenciaértékek a PCMag-tól mutasson egy futó RTX 2080 Super-et Ellenőrzés ultra minőségben, minden sugárkövetési beállítással max. 4K-nál csak 19 FPS-el küzd, de bekapcsolt DLSS-sel sokkal jobb 54 FPS-t kap. A DLSS ingyenes teljesítmény az NVIDIA számára, amelyet a Turing és az Ampere Tensor magjai tesznek lehetővé. Bármely játék, amely támogatja és GPU-korlátozott, csak a szoftverből képes komoly gyorsulásokat látni.
A DLSS nem új keletű, és két évvel ezelőtt indított RTX 2000-es sorozatként jelentették be. Abban az időben nagyon kevés játék támogatta, mivel az NVIDIA-nak szüksége volt egy gépi tanulási modell kiképzésére és hangolására minden egyes játékhoz.
Azonban ez idő alatt az NVIDIA teljesen átírta, az új verziót DLSS 2.0-nak hívta. Ez egy általános célú API, ami azt jelenti, hogy bármely fejlesztő megvalósíthatja, és a legtöbb jelentős kiadás már felvette. Ahelyett, hogy egy képkockán dolgozna, a TAA-hoz hasonlóan az előző képkocka mozgásvektor adatait veszi fel. Az eredmény sokkal élesebb, mint a DLSS 1.0, és egyes esetekben valóban kinéz jobb és még a natív felbontásnál is élesebb, ezért nincs sok oka annak bekapcsolására.
Van egy fogás - ha teljesen átkapcsolunk jeleneteket, például a jeleneteknél, a DLSS 2.0-nak a legelső keretet 50% -os minőségben kell megjelenítenie, miközben a mozgásvektor-adatokra vár. Ez apró minőségromlást eredményezhet néhány milliszekundumig. De a megtekintett dolgok 99% -a rendesen megjelenik, és a legtöbb ember ezt nem veszi észre a gyakorlatban.
ÖSSZEFÜGGŐ: Mi az NVIDIA DLSS, és hogyan gyorsítja a sugárkövetést?
Ampere architektúra: AI-re készült
Ampere gyors. Komolyan gyorsan, különösen az AI-számításoknál. Az RT mag 1,7-szer gyorsabb, mint a Turing, az új Tensor mag pedig 2,7-szer gyorsabb, mint a Turing. A kettő kombinációja igazi generációs ugrás a sugárkövetési teljesítményben.

Május elején, Az NVIDIA kiadta az Ampere A100 GPU-t , az AI futtatására tervezett adatközpont GPU. Ezzel sok mindent részleteztek, ami miatt az Ampere sokkal gyorsabb. Az adatközpontos és nagy teljesítményű számítási munkaterhelések esetében az Ampere általában 1,7-szer gyorsabb, mint Turing. Az AI-képzéshez akár hatszor gyorsabb.
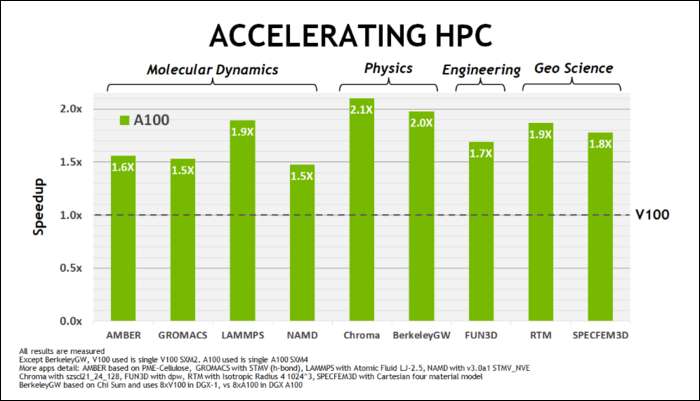
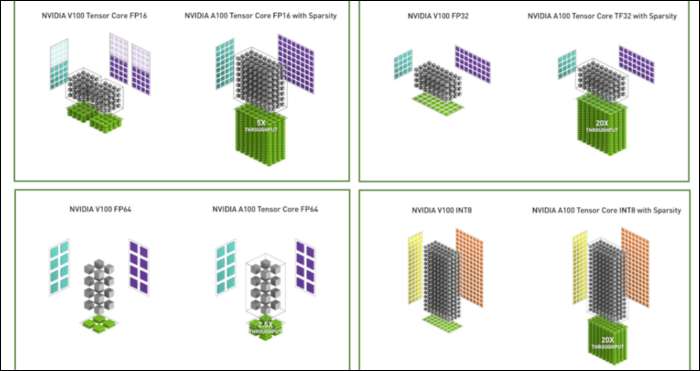
Az Ampere segítségével az NVIDIA egy új számformátumot használ, amely bizonyos terheléseknél az iparági szabvány „Lebegőpontos 32” vagy FP32 helyébe lép. A motorháztető alatt a számítógéped által feldolgozott összes szám egy előre meghatározott számú bitet foglal el a memóriában, legyen az 8, 16, 32, 64 vagy annál nagyobb. A nagyobb számokat nehezebb feldolgozni, így ha kisebb méretet tud használni, akkor kevesebbet kell összeszorítania.
Az FP32 32 bites decimális számot tárol, és 8 bitet használ a szám tartományához (mekkora vagy kicsi lehet), és 23 bitet a pontossághoz. Az NVIDIA állítása szerint ez a 23 precíziós bit nem feltétlenül szükséges sok mesterséges intelligencia-terheléshez, és mindössze 10 közül hasonló eredményeket és sokkal jobb teljesítményt érhet el. A méret csökkentése 32 helyett csak 19 bitre, sok különbséggel jár a számítások között.
Ezt az új formátumot Tensor Float 32-nek hívják, és az A100-as Tensor magok a furcsa méretű formátum kezelésére vannak optimalizálva. Ez az, hogy meghal a zsugorodás és növekszik a magszám, hogyan érik el a 6-szoros gyorsítást az AI-képzés során.

Az új számformátum mellett az Ampere jelentős teljesítmény-gyorsulásokat tapasztal speciális számításokban, például az FP32 és az FP64 esetében. Ezek közvetlenül nem jelentenek több FPS-t a laikusok számára, de részei annak, ami a Tensor-műveletek során összességében közel háromszor gyorsabbá teszi.
Aztán, hogy még jobban felgyorsítsák a számításokat, bevezették a koncepciót finomszemcsés strukturált ritkaság , ami nagyon divatos szó egy nagyon egyszerű koncepcióhoz. Az ideghálózatok nagy számlistákkal, úgynevezett súlyokkal dolgoznak, amelyek befolyásolják a végső kimenetet. Minél több számot kell összeütni, annál lassabb lesz.
Mindazonáltal ezek a számok nem mind hasznosak. Némelyikük szó szerint csak nulla, és alapvetően kidobható, ami hatalmas gyorsulásokhoz vezet, amikor egyszerre több számot tud összeütni. A ritkaság lényegében tömöríti a számokat, ami kevesebb erőfeszítést igényel a számítások elvégzéséhez. Az új „Sparse Tensor Core” a tömörített adatok működésére épül.
A változások ellenére az NVIDIA szerint ez egyáltalán nem befolyásolhatja észrevehetően a képzett modellek pontosságát.
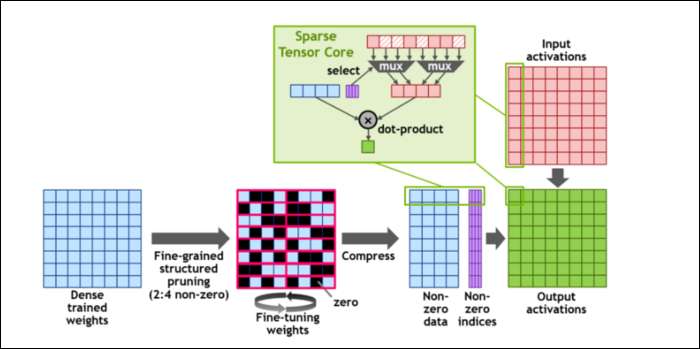
A ritka INT8 számításokhoz, az egyik legkisebb számformátumhoz, egyetlen A100 GPU csúcsteljesítménye meghaladja az 1,25 PetaFLOP-t, ami megdöbbentően magas szám. Természetesen ez csak akkor történik meg, amikor egy bizonyos típusú számot összezúz, de ennek ellenére lenyűgöző.







