
あなたがGoogleで何かを検索し、疑問に思っている「方法は、それがどこを見て知っているのですか?」答えは、あなたが簡単にオンラインのものを見つけることができるように、ウェブやインデックスを検索「ウェブクローラ」です。説明します。
検索エンジンとクローラ
Googleなどの検索エンジンでキーワードを使用して検索する場合 焼き 、サイトには、その用語に関連した結果のリストを生成するために、ページの兆を通じて選別し。どのように正確にこれらの検索エンジンは、ファイルにこれらのページのすべてを持って、それらを探すために方法を知っている、と数秒以内に、これらの結果を生成するのですか?
答えはまた、スパイダーとして知られているウェブクローラ、です。これらは自動化されたプログラムは、彼らが検索エンジンに追加することができるようにウェブ上の「クロール」またはブラウズもの(多くの場合、「ロボット」または「ボット」と呼ばれます)。これらのロボットのインデックスのウェブサイトは、最終的には、検索結果に表示されるページのリストを作成します。
クローラはまた、ほぼ瞬時に検索を行うことができますエンジンのデータベースにこれらのページのコピーを作成して保存。また、検索エンジンは頻繁に含まれた理由です サイトのキャッシュバージョン そのデータベースインチ
関連している: それがダウンすると、Webページにアクセスする方法
サイトマップと選定
だから、どのようにクローラは、クロールにどのウェブサイトを選ぶのですか?まあ、最も一般的なシナリオは、そのウェブサイトの所有者が自分のサイトをクロールする検索エンジン欲しいです。彼らはインデックスに自分のページをグーグル、ビング、ヤフー、または別の検索エンジンを要求することによって、これを達成することができます。このプロセスは、エンジンにエンジンによって異なります。また、検索エンジンは頻繁にURLが他の公共のサイトにリンクされた回数を追跡することによって、クロールに人気の高い、よくリンク先のウェブサイトを選択します。
ウェブサイトの所有者は、ヘルプの検索エンジンのインデックスになど、自分のウェブサイトを、特定のプロセスを使用することができます
サイトマップをアップロードします。これはあなたのウェブサイトの一部であるすべてのリンクとページを含むファイルです。通常、あなたが好きなページがインデックス何を示すのに使われています。
検索エンジンは既に一度ウェブサイトをクロールした後、彼らは再び自動的にそのサイトをクロールします。周波数は、ウェブサイトが他のメトリックの中で、どのように人気のあるによって異なります。そのため、サイトの所有者は頻繁にエンジンがインデックスにどの新しいウェブサイトを知っているように更新したサイトマップを維持します。
ロボットと丁寧ファクター

どのような場合は、ウェブサイト いない 一部またはすべてのページが検索エンジンに表示したいですか?たとえば、あなたは、人々は会員専用ページを検索するか、あなたを見たいと思っていないかもしれません 404エラーページ 。また、robots.txtのとして知られているクロール除外リストは、出番です。これは、そのWebページがインデックスから除外するクローラへのおもむくまま、単純なテキストファイルです。
robots.txtのが重要であるもう一つの理由は、ウェブクローラがサイトのパフォーマンスに大きな影響を与えることができるということです。クローラは基本的にウェブサイト上のすべてのページをダウンロードしているので、それらはリソースを消費し、速度低下を引き起こす可能性があります。彼らは、予測不可能な時点および承認なしに到着します。あなたのページが繰り返しインデックス化が必要ない場合は、停止クローラはあなたのウェブサイトの負荷の一部を軽減することがあります。幸いなことに、ほとんどのクローラがサイトの所有者のルールに基づいて特定のページをクロールを停止します。
メタデータのマジック
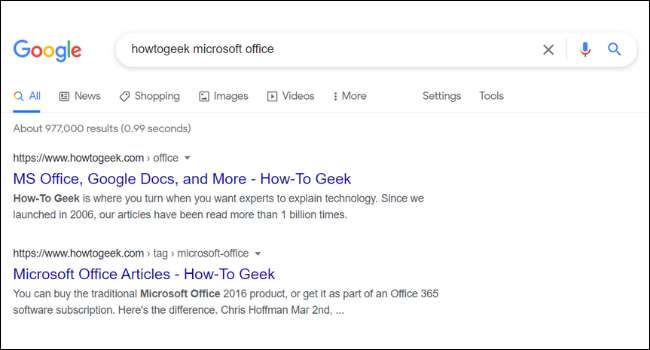
グーグルですべての検索結果のURLとタイトルの下には、ページの短い説明を見つけます。これらの記述は、スニペットと呼ばれています。 Googleでのページのスニペットは、常にウェブサイトの実際のコンテンツと並んでいないことに気づくかもしれません。多くのウェブサイトと呼ばれるものを持っているので、これは「 METAタグ 、」サイトの所有者が自分のページに追加することをカスタムの説明です。
サイト所有者は、多くの場合、あなたがウェブサイト上でクリックします作るために書かれたメタデータの記述を誘導を思い付きます。 Googleはまた、価格や在庫状況などの他のメタ情報を、一覧表示されます。これは、これらの実行されている電子商取引のウェブサイトのために特に有用です。
あなたの検索中
Web検索はインターネットを使用するという本質的な部分です。 Webを検索することは、新しいWebサイト、ストア、コミュニティ、および興味を発見するための素晴らしい方法です。毎日、Webクローラは何百万ページを訪問し、それらを検索エンジンに追加します。クローラには、サイトリソースを取り上げるように、いくつかのダウンサイドがありますが、サイトの所有者や訪問者の両方には貴重です。
関連している: 最後の15分のGoogle検索履歴を削除する方法







