
Hai mai cercato qualcosa su Google e si chiedeva: "Come sa dove guardare?" La risposta è "Web crawler", che cerca il web e indicilo in modo che tu possa trovare le cose facilmente online. Spiegheremo.
Motori di ricerca e crawlers
Quando cerchi utilizzando una parola chiave su un motore di ricerca come Google o Bing , il sito si confonde attraverso trilioni di pagine per generare un elenco di risultati relativi a tale termine. Come fanno esattamente questi motori di ricerca hanno tutte queste pagine in file, sai come cercarli e generare questi risultati in pochi secondi?
La risposta è web crawler, noto anche come ragni. Questi sono programmi automatizzati (spesso chiamati "robot" o "robot") che "gattonio" o sfoglia il web in modo che possano essere aggiunti ai motori di ricerca. Questi siti Web dei robot indice per creare un elenco di pagine che alla fine vengono visualizzate nei risultati della ricerca.
I crawlers creano e archiviano anche copie di queste pagine nel database del motore, che ti consente di rendere le ricerche quasi all'istante. È anche il motivo per cui i motori di ricerca spesso includono Versioni memorizzate nella cache dei siti nei loro database.
IMPARENTATO: Come accedere a una pagina Web quando è giù
Mappe e selezione del sito
Quindi, come fanno i crawlers quali siti web strisciano? Bene, lo scenario più comune è che i proprietari del sito web vogliono i motori di ricerca per strisciare i loro siti. Possono raggiungere questo richiedendo Google, Bing, Yahoo o un altro motore di ricerca per indicizzare le loro pagine. Questo processo varia dal motore al motore. Inoltre, i motori di ricerca selezionano spesso i siti Web popolari e ben collegati per la scansione monitorando il numero di volte in cui un URL è collegato su altri siti pubblici.
I proprietari di siti Web possono utilizzare determinati processi per aiutare i motori di ricerca indicizzano i loro siti Web, come ad esempio
Caricamento di una mappa del sito. Questo è un file contenente tutti i link e le pagine che fanno parte del tuo sito web. Normalmente è usato per indicare quali pagine vorresti indicizzato.
Una volta che i motori di ricerca hanno già sistemato un sito Web una volta, scanderanno automaticamente il sito di nuovo quel sito. La frequenza varia in base a quanto sia popolare un sito web, tra le altre metriche. Pertanto, i proprietari di siti spesso tengono spesso le mappe del sito aggiornate per consentire ai motori a sapere quali nuovi siti Web indice.
Robot e il fattore di cortesia

Cosa succede se un sito web no. Vuoi che alcune o tutte le sue pagine appaiano su un motore di ricerca? Ad esempio, potresti non volere che le persone cercano una pagina solo per un membro o vedere il tuo 404 Pagina di errore . Questo è dove la lista di esclusione di crawl, nota anche come robots.txt, entra in gioco. Questo è un semplice file di testo che detta i crawlers quali pagine Web da escludere dall'indicizzazione.
Un altro motivo per cui robots.txt è importante è che il web crawler può avere un effetto significativo sulle prestazioni del sito. Poiché i crawlers stanno essenzialmente scaricando tutte le pagine sul tuo sito web, consumano risorse e possono causare rallentamenti. Arrivano a tempi imprevedibili e senza approvazione. Se non hai bisogno di pagine indicizzate ripetutamente, smettere di crawlers potrebbe aiutare a ridurre alcuni dei carichi del tuo sito web. Fortunatamente, la maggior parte dei crawlers smette di strisciare determinate pagine in base alle regole del proprietario del sito.
Metadati magic.
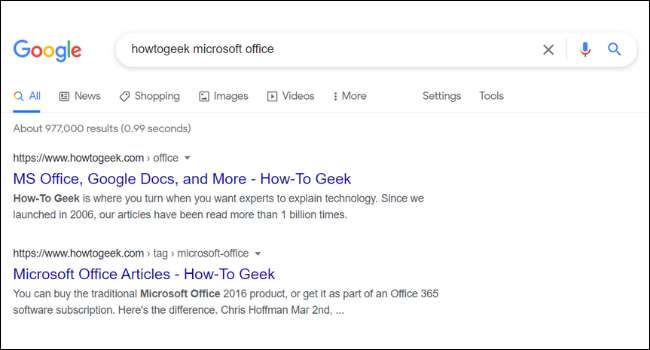
Sotto l'URL e il titolo di ogni risultato della ricerca in Google, troverai una breve descrizione della pagina. Queste descrizioni sono chiamate snippet. Potresti notare che lo snippet di una pagina in Google non sempre si allinea con il contenuto effettivo del sito web. Questo perché molti siti web hanno qualcosa chiamato " meta tags "Quali sono le descrizioni personalizzate che i proprietari del sito si aggiungono alle loro pagine.
I proprietari del sito vengono spesso forniti con le descrizioni di metadati allettanti scritte per farti fare clic su un sito web. Google elenca anche altre meta-informazioni, come i prezzi e la disponibilità di magazzino. Questo è particolarmente utile per chi esegue i siti Web di e-commerce.
La tua ricerca
La ricerca Web è una parte essenziale dell'utilizzo di Internet. La ricerca del Web è un ottimo modo per scoprire nuovi siti Web, negozi, comunità e interessi. Ogni giorno, web crawlers visita milioni di pagine e aggiungili ai motori di ricerca. Mentre i crawlers hanno degli aspetti negativi, come assumere risorse del sito, sono inestimabili sia per i proprietari dei siti che per i visitatori.
IMPARENTATO: Come eliminare gli ultimi 15 minuti della cronologia di ricerca di Google





