
Har du någonsin sökt efter något på Google och undrat, "Hur vet det vart man ska se?" Svaret är "Web Crawlers", som söker på webben och indexerar det så att du enkelt kan hitta saker online. Vi kommer att förklara.
Sökmotorer och crawlers
När du söker med ett sökord på en sökmotor som Google eller Bing , platsen siktar genom trillioner av sidor för att generera en lista över resultat relaterade till den termen. Hur exakt har dessa sökmotorer alla dessa sidor på filen, vet hur man letar efter dem och genererar dessa resultat inom några sekunder?
Svaret är webbkrypare, även kända som spindlar. Dessa är automatiserade program (ofta kallade "robotar" eller "bots") som "krypa" eller bläddra över webben så att de kan läggas till sökmotorer. Dessa robotar index webbplatser för att skapa en lista med sidor som så småningom visas i dina sökresultat.
Crawlers skapar även och lagrar kopior av dessa sidor i motorns databas, vilket gör att du kan göra sökningar nästan omedelbart. Det är också anledningen till att sökmotorer ofta inkluderar cachade versioner av webbplatser i sina databaser.
RELATERAD: Så här öppnar du en webbsida när den är nere
Webbplatskartor och urval
Så hur väljer crawlers vilka webbplatser att krypa? Tja, det vanligaste scenariot är att webbplatsägare vill att sökmotorer ska krypa sina platser. De kan uppnå detta genom att begära Google, Bing, Yahoo eller en annan sökmotor för att indexera sina sidor. Denna process varierar från motor till motor. Dessutom väljer sökmotorer ofta populära, välbundna webbplatser för att krypa genom att spåra antalet gånger som en URL är länkad på andra offentliga webbplatser.
Webbplatsägare kan använda vissa processer för att hjälpa till med att söka motorer indexera sina webbplatser, till exempel
Ladda upp en webbplatskarta. Detta är en fil som innehåller alla länkar och sidor som ingår i din webbplats. Det används normalt för att ange vilka sidor du vill ha indexerat.
När sökmotorer redan har krypt en webbplats en gång, kommer de automatiskt att krypa den webbplatsen igen. Frekvensen varierar baserat på hur populär en webbplats är bland annat metrics. Därför håller webbplatsägare ofta uppdaterade webbplatskartor för att låta motorer veta vilka nya webbplatser som ska indexera.
Robotar och den politiska faktorn

Vad händer om en webbplats inte Vill du ha några eller alla sidor som ska visas på en sökmotor? Till exempel kanske du inte vill att folk ska söka efter en medlems enda sida eller se din 404 Fel sida . Det är här listan Crawlusion, även känd som robots.txt, kommer i spel. Det här är en enkel textfil som dikterar till crawlers vilka webbsidor som ska utesluta från indexering.
En annan anledning till att robots.txt är viktigt är att webbsökare kan ha en signifikant effekt på platsens prestanda. Eftersom sökrobotar i huvudsak laddar ner alla sidor på din webbplats, konsumerar de resurser och kan orsaka avmattning. De anländer till oförutsägbara tider och utan godkännande. Om du inte behöver dina sidor indexerade upprepade gånger, kan stoppa crawlers hjälpa till att minska en del av din webbplatsbelastning. Lyckligtvis slutar de flesta crawlers att krypa vissa sidor baserat på webbplatsens ägares regler.
Metadata magi
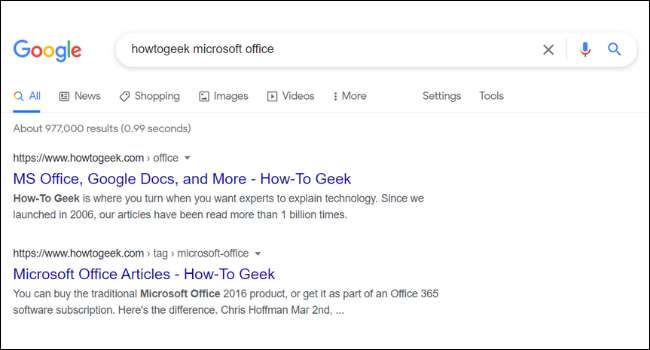
Under webbadressen och titeln på varje sökresultat i Google hittar du en kort beskrivning av sidan. Dessa beskrivningar kallas snippets. Du kanske märker att snippet på en sida i Google inte alltid stämmer överens med webbplatsens faktiska innehåll. Detta beror på att många webbplatser har något som kallas " Metataggar , "Vilka är anpassade beskrivningar som webbplatsägare lägger till på sina sidor.
Webbplatsägare kommer ofta upp med lockande metadatabeskrivningar skrivna för att du vill klicka på en webbplats. Google listar också andra metainformation, till exempel priser och lager. Detta är särskilt användbart för de som kör e-handel webbplatser.
Din sökning
Websökning är en viktig del av att använda Internet. Att söka på webben är ett utmärkt sätt att upptäcka nya webbplatser, butiker, samhällen och intressen. Varje dag besöker Web Crawlers miljontals sidor och lägger till dem på sökmotorer. Medan crawlers har några downsides, som att ta upp webbplatsens resurser, är de ovärderliga för båda platsägare och besökare.
RELATERAD: Så här tar du bort de senaste 15 minuterna av Googles sökhistorik







