
Вы когда-нибудь искали что-то в Google и задумывались: «Как он знает, куда посмотреть?» Ответ - «Web Crawlers», которые ищут в Интернете и индексируйте его, чтобы вы могли легко найти в Интернете. Мы объясним.
Поисковые системы и сотрясения
Когда вы ищете с помощью ключевого слова на поисковую систему, как Google или Промежуток , сайт сидит через триллионы страниц, чтобы генерировать список результатов, связанных с этим термином. Насколько именно эти поисковые системы имеют все эти страницы в файле, знают, как их искать, и генерировать эти результаты в течение нескольких секунд?
Ответ - это веб-скалы, также известный как пауки. Это автоматизированные программы (часто называют «роботами» или «ботами»), которые «ползти» или просматривают через Интернет, чтобы их можно было добавить в поисковые системы. Эти веб-сайты Robots Index создают список страниц, которые в конечном итоге появляются в ваших результатах поиска.
Crawlers также создают и хранят копии этих страниц в базе данных двигателя, что позволяет сделать поиски почти мгновенно. Это также причина, по которой поисковые системы часто включают кэшированные версии сайтов в их базах данных.
СВЯЗАННЫЕ С: Как получить доступ к веб-странице, когда она снижается
Карты сайта и выбор
Итак, как Crawlers выбирают какие сайты для ползания? Что ж, наиболее распространенным сценарием является то, что владельцы сайта хотят поисковые системы для ползания своих сайтов. Они могут достичь этого, запрашивая Google, Bing, Yahoo или другой поисковой системе, чтобы индексировать свои страницы. Этот процесс варьируется от двигателя к двигателю. Кроме того, поисковые системы часто выбирают популярные, хорошо связанные сайты для ползания, отслеживая количество раз, когда URL связан на других публичных сайтах.
Владельцы веб-сайтов могут использовать определенные процессы, чтобы помочь поисковым системам индекс своих веб-сайтов, таких как
Загрузка карты сайта. Это файл, содержащий все ссылки и страницы, которые являются частью вашего сайта. Обычно используется для указания каких страниц, которые вы хотели бы проиндексированы.
Как только поисковые системы уже один раз выползали веб-сайт, они автоматически сканируют этот сайт снова. Частота варьируется в зависимости от того, насколько популярен сайт, среди других метрик. Поэтому владельцы сайта часто поддерживают обновленные карты сайта, чтобы позволить двигателям знать, какие новые веб-сайты индексируют.
Роботы и фактор вещества

Что если сайт нет Хотите некоторые или все его страницы, чтобы появиться на поисковой системе? Например, вы можете не захотеть людей искать страницу только для участников или увидеть ваш Страница ошибки 404 Отказ Это то, где в игру входит список исключения, также известный как ROBOTS.TXT. Это простой текстовый файл, который диктует сканерам, которые веб-страницы для исключения из индексации.
Еще одна причина, по которой ROBOTS.TXT важно, так это то, что веб-скалы могут оказать существенное влияние на производительность сайта. Поскольку Crawlers по существу загружают все страницы на вашем сайте, они потребляют ресурсы и могут вызвать замедление. Они прибывают в непредсказуемые времена и без одобрения. Если вам не нужны ваши страницы, проиндексированные неоднократно, затем остановка ползунок может помочь уменьшить нагрузку на некоторые из ваших веб-сайтов. К счастью, большинство погреблений перестают ползать определенные страницы на основе правил владельца сайта.
Метаданная магия
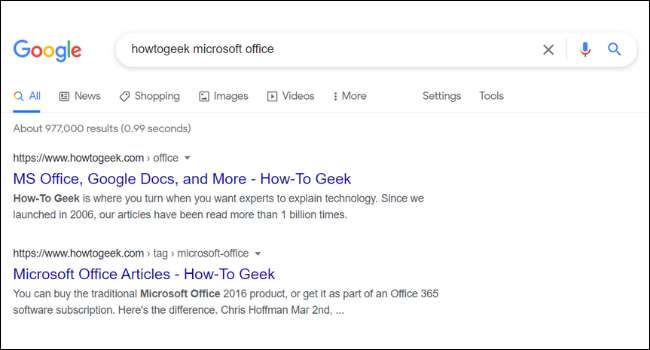
Под URL-адресом и названием каждого результата поиска в Google вы найдете краткое описание страницы. Эти описания называются фрагментами. Вы можете заметить, что фрагмент страницы в Google не всегда выстраивается с фактическим контентом веб-сайта. Это потому, что многие сайты имеют что-то называемое » Мета-теги , «Которые являются пользовательскими описаниями, которые владельцы сайта добавляют к их страницам.
Владельцы сайта часто придумывают запрашивающие описания метаданных, чтобы заставить вы хотите нажать на веб-сайт. Google также перечисляет другую мета-информацию, такую как цены и наличие акций. Это особенно полезно для бегущих веб-сайтов электронной коммерции.
Ваш поиск
Интернет-поиск - это неотъемлемая часть использования Интернета. Поиск в Интернете - отличный способ обнаружить новые веб-сайты, магазины, общины и интересы. Каждый день Web Crawlers посещают миллионы страниц и добавляют их в поисковые системы. В то время как Crawlers имеют некоторые недостатки, такие как сбор ресурсов сайта, они неоценимы для владельцев сайтов и посетителей.
СВЯЗАННЫЕ С: Как удалить последние 15 минут истории поиска Google







