
Už jste někdy hledal něco na Google a přemýšlel, „Jak to víte, kde hledat?“ Odpověď je „web roboti“, které hledají na internetu, a index tak, že můžete najít věci snadno online. Vysvětlíme.
Vyhledávače a Crawlers
Když se vyhledávat pomocí klíčového slova na vyhledávače jako Google nebo Bing. Se sifts místě přes biliony stránek pro generování seznamu výsledků týkajících se tohoto pojmu. Jak přesně se tyto vyhledávače mají všechny tyto stránky ze spisu, víte, jak se dívat na ně a vytvářet tyto výsledky během několika vteřin?
Odpovědí je prohledávače, také známý jako pavouci. Toto jsou automatické programy (často nazývané „roboti“ nebo „roboty“), že „plazit“ nebo procházení na webu tak, aby mohly být přidány do vyhledávače. Tito roboti index webové stránky, vytvořit seznam stránek, které nakonec se objevují ve výsledcích vyhledávání.
Roboti také vytvářet a ukládat kopie těchto stránek v databázi motoru, který umožňuje, aby se vyhledávání téměř okamžitě. To je také důvod, proč vyhledávače často obsahují mezipaměti verze stránek ve svých databázích.
PŘÍBUZNÝ: Jak získat přístup k webové stránce, když je to Down
Site Mapy a Selection
Tak, jak se roboti vybrat, které stránky se plazit? No, z nichž nejčastější scénář je, že majitelé webových stránek chtějí vyhledávače procházet své stránky. Mohou dosáhnout tím, že požaduje Google, Bing, Yahoo, nebo jiný vyhledávač k indexu své stránky. Tento postup se liší od motoru k motoru. Také vyhledávače často vybrat populární a dobře propojené webové stránky k procházení tím, že sleduje, kolikrát, že URL je propojen na jiných veřejných místech.
Vlastníci webových stránek mohou používat určité procesy pomáhat vyhledávače index svých webových stránkách, jako je například
nahrání mapa stránek. Jedná se o soubor, který obsahuje všechny odkazy a stránky, které jsou součástí vašich webových stránkách. Je běžně používá k označení, jaké stránky byste chtěli indexovány.
Jakmile vyhledávače již lezl webových stránek najednou, budou automaticky procházet tento web znovu. Frekvence se liší v závislosti na tom, jak populární webové stránky je mimo jiné metriky. Proto se majitelé stránek často udržovat aktualizované mapy stránek, aby motory vědět, jaké nové stránky do indexu.
Roboti a Zdvořilost faktor

Co když webové stránky neudělaný chcete některých nebo všech jejích stránkách se objeví na vyhledávače? Například, možná nebudete chtít, aby lidé hledat stránky pouze pro členy nebo vidět váš 404 chybová stránka . To je místo, kde seznam vyloučení kraul, také známý jako robots.txt, vstoupí do hry. Jedná se o jednoduchý textový soubor, který diktuje na pásech, které webové stránky vyjmout z indexování.
Dalším důvodem, proč robots.txt Důležité je, že webové prohledávače mohou mít významný vliv na výkon webu. Vzhledem k tomu, roboti jsou v podstatě stahovat všechny stránky na svých webových stránkách, které spotřebovávají zdroje a může způsobit zpomalení. Dorazí v nepředvídatelných časech a bez schválení. Pokud nepotřebujete vaše stránky opakovaně indexovány, pak zastavení roboti by mohla pomoci snížit některé ze svých webových stránek zatížení. Naštěstí většina roboti zastavení procházení určitých stránek založených na pravidlech jejich vlastníka.
metadata Magie
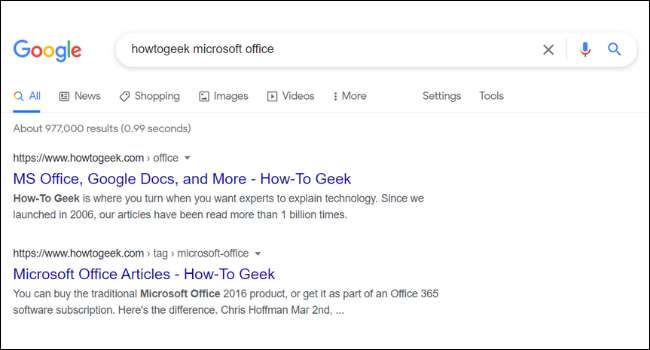
Pod URL a titulek každého výsledku vyhledávání v Google, najdete krátký popis stránky. Tyto popisy jsou nazývané úryvky. Můžete si všimnout, že fragment stránky v Googlu nemusí vždy vyrovnaná se skutečným obsahem internetových stránek. To je proto, že mnoho internetových stránek mají něco, co nazývá „ meta tagy „, Které jsou vlastní popisy, které majitelé stránek přidat do svých stránek.
Majitelé stránek často přijít s lákavou popisy metadat písemné, aby chcete kliknout na internetových stránkách. Google také uvádí další metainformace, jako jsou ceny a dostupnosti zásob. To je užitečné zejména pro ty, běh e-commerce webové stránky.
Vaše Vyhledávání
Hledání webu je nezbytnou součástí používání internetu. Hledání webu je skvělý způsob, jak objevit nové webové stránky, obchody, komunity a zájmy. Každý den navštěvují webové prohlašovače miliony stránek a přidají je do vyhledávačů. Zatímco Crawlers mají nějaké downsides, stejně jako zaujmout zdroje stránek, jsou neocenitelné pro majitele stránek a návštěvníků.
PŘÍBUZNÝ: Jak odstranit posledních 15 minut historie vyhledávání Google
 při budování PC?")






