
Har du nogensinde søgt efter noget på Google og spekulerede på, "Hvordan ved det, hvor du skal se?" Svaret er "Web Crawlers", som søger på internettet og indeks det, så du kan finde ting nemt online. Vi vil forklare.
Søgemaskiner og crawlere
Når du søger ved hjælp af et søgeord på en søgemaskine som Google eller Bing. , Site Sifts gennem trillioner af sider for at generere en liste over resultater relateret til dette udtryk. Hvordan har disse søgemaskiner alle disse sider på filen, ved, hvordan man skal lede efter dem og generere disse resultater inden for få sekunder?
Svaret er webcrawlere, også kendt som edderkopper. Disse er automatiserede programmer (ofte kaldet "robotter" eller "bots"), der "crawl" eller gennemse på tværs af internettet, så de kan tilføjes til søgemaskiner. Disse robotter indeks websteder for at oprette en liste over sider, der i sidste ende vises i dine søgeresultater.
Crawlers opretter også og gemmer kopier af disse sider i motorens database, som giver dig mulighed for at gøre søgninger næsten øjeblikkeligt. Det er også grunden til, at søgemaskiner ofte omfatter cachelagrede versioner af websteder i deres databaser.
RELATEREDE: Sådan får du adgang til en webside, når den er nede
Site Maps og Selection
Så, hvordan vælger crawlere hvilke websteder der skal krybe? Nå, det mest almindelige scenario er, at webstedsejere vil have søgemaskiner til at krybe deres websteder. De kan opnå dette ved at anmode om Google, Bing, Yahoo eller en anden søgemaskine til at indeksere deres sider. Denne proces varierer fra motor til motor. Søgemaskiner vælger også ofte populære, velbundne websteder til at krybe ved at spore antallet af gange, som en webadresse er forbundet på andre offentlige websteder.
Website ejere kan bruge visse processer til at hjælpe søgemaskiner indeks deres hjemmesider, som f.eks
Uploading af et webstedskort. Dette er en fil, der indeholder alle de links og sider, der er en del af dit websted. Det bruges normalt til at angive, hvilke sider du vil have indekseret.
Når søgemaskiner allerede har gennemsøgt en hjemmeside en gang, vil de automatisk krybe det pågældende websted igen. Frekvensen varierer baseret på, hvor populært en hjemmeside er blandt andet metrics. Derfor holder webstedsejere ofte opdaterede webstedskort for at lade motorer vide, hvilke nye websites at indeksere.
Roboter og høflighedsfaktoren

Hvad hvis en hjemmeside ikke det ikke Vil du have nogle eller alle sine sider, der skal vises på en søgemaskine? For eksempel kan du ikke have, at folk kan søge efter en kun-kun-side eller se din 404 Fejl side . Her er crawl eksklusionslisten, også kendt som robots.txt, kommer i spil. Dette er en simpel tekstfil, der dikterer at crawlere, hvilke websider der skal udelukker fra indeksering.
En anden grund til, at robots.txt er vigtigt, er, at webcrawlere kan have en betydelig effekt på stedet ydeevne. Fordi crawlere i det væsentlige downloader alle siderne på din hjemmeside, bruger de ressourcer og kan forårsage afmatning. De ankommer til uforudsigelige tider og uden godkendelse. Hvis du ikke har brug for dine sider, der er indekseret gentagne gange, kan stoppe crawlere måske medvirke til at reducere nogle af din website load. Heldigvis stopper de fleste crawlere med at krybe visse sider baseret på reglerne for webstedets ejer.
Metadata Magic.
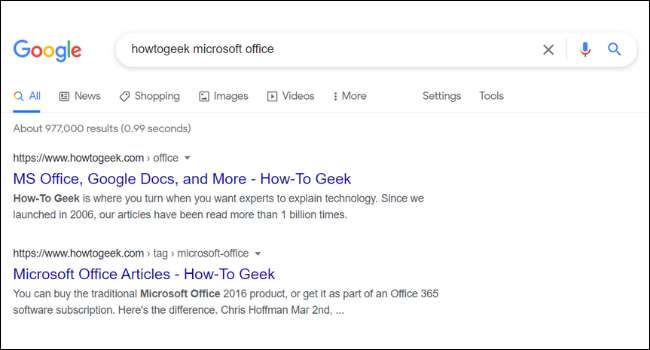
Under webadressen og titlen på hvert søgeresultat i Google finder du en kort beskrivelse af siden. Disse beskrivelser kaldes uddrag. Du kan muligvis bemærke, at uddragningen på en side i Google ikke altid linker op med webstedets faktiske indhold. Dette skyldes, at mange hjemmesider har noget, der hedder " Meta Tags. , "Som er brugerdefinerede beskrivelser, som webstedsejere tilføjer til deres sider.
Site ejere kommer ofte op med lokkende metadata beskrivelser skrevet for at få dig til at klikke på en hjemmeside. Google viser også andre meta-information, såsom priser og lager tilgængelighed. Dette er især nyttigt for dem, der kører e-handelswebsteder.
Din søgning
Websøgning er en væsentlig del af brugen af internettet. At søge på internettet er en fantastisk måde at opdage nye hjemmesider, butikker, fællesskaber og interesser på. Hver dag besøger webcrawlere millioner af sider og tilføjer dem til søgemaskiner. Mens crawlere har nogle ulemper, som at tage op på stedet ressourcer, er de uvurderlige for både webstedsejere og besøgende.
RELATEREDE: Sådan slettes de sidste 15 minutter af Google Search History







