
Avez-vous déjà cherché quelque chose sur Google et me demanda: "Comment ça sait où regarder?" La réponse est "web crawlers" qui recherchent sur le Web et indexer pour que vous puissiez trouver des choses facilement en ligne. Nous allons expliquer.
Moteurs de recherche et agendules
Lorsque vous recherchez à l'aide d'un mot-clé sur un moteur de recherche comme Google ou Bing Le site passe à travers des trillions de pages pour générer une liste de résultats liés à ce terme. Comment ces moteurs de recherche ont-ils toutes ces pages dans le fichier, savent-ils les rechercher et générer ces résultats en quelques secondes?
La réponse est web crawlers, également appelée araignées. Ce sont des programmes automatisés (souvent appelés «robots» ou «bots») qui «rampe» ou parcourent sur la bande afin qu'ils puissent être ajoutés aux moteurs de recherche. Ces sites Web d'indice des robots pour créer une liste de pages qui apparaissent éventuellement dans vos résultats de recherche.
Les crawlers créent également et stockent des copies de ces pages dans la base de données du moteur, ce qui vous permet de faire des recherches presque instantanément. C'est aussi la raison pour laquelle les moteurs de recherche incluent souvent Versions en cache des sites dans leurs bases de données.
EN RELATION: Comment accéder à une page Web quand c'est en panne
Cartes et sélection du site
Alors, comment les crawlers choisissent-ils les sites Web pour ramper? Eh bien, le scénario le plus courant est que les propriétaires de sites Web veulent que les moteurs de recherche puissent ramper leurs sites. Ils peuvent y parvenir en demandant à Google, Bing, Yahoo ou un autre moteur de recherche pour indexer leurs pages. Ce processus varie d'un moteur au moteur. En outre, les moteurs de recherche sélectionnent fréquemment des sites Web populaires et bien liés à ramper en suivant le nombre de fois qu'une URL est liée sur d'autres sites publics.
Les propriétaires de sites Web peuvent utiliser certains processus pour aider les moteurs de recherche à indexer leurs sites Web, tels que
Téléchargement d'une carte du site. Ceci est un fichier contenant tous les liens et pages qui font partie de votre site Web. Il est normalement utilisé pour indiquer quelles pages vous aimeriez indexées.
Une fois que les moteurs de recherche ont déjà rampé un site Web une fois, ils ramperont automatiquement ce site à nouveau. La fréquence varie en fonction de la popularité d'un site Web, entre autres mesures. Par conséquent, les propriétaires de sites conservent fréquemment des cartes de site mis à jour pour laisser les moteurs savoir quels nouveaux sites Web à indexer.
Robots et le facteur de politesse

Et si un site web ne pas Vous voulez que tout ou partie de ses pages apparaisse sur un moteur de recherche? Par exemple, vous ne voudrez peut-être pas que les gens recherchent une page des membres seulement ou de voir votre Page 404 Page d'erreur . C'est ici que la liste d'exclusion d'analyse, également appelée robots.txt, entre en jeu. Il s'agit d'un simple fichier texte qui dicte aux crawlers que les pages Web à exclure de l'indexation.
Une autre raison pour laquelle les robots.txt sont importants est que les agresseurs Web peuvent avoir un effet significatif sur la performance du site. Parce que les crawlers téléchargent essentiellement toutes les pages de votre site Web, ils consomment des ressources et peuvent entraîner des ralentissements. Ils arrivent à des moments imprévisibles et sans approbation. Si vous n'avez pas besoin de vos pages indexées à plusieurs reprises, les robots d'arrêt peuvent aider à réduire la charge de votre site Web. Heureusement, la plupart des crawlers arrêtent de ramper certaines pages sur la base des règles du propriétaire du site.
Métadonnées magique
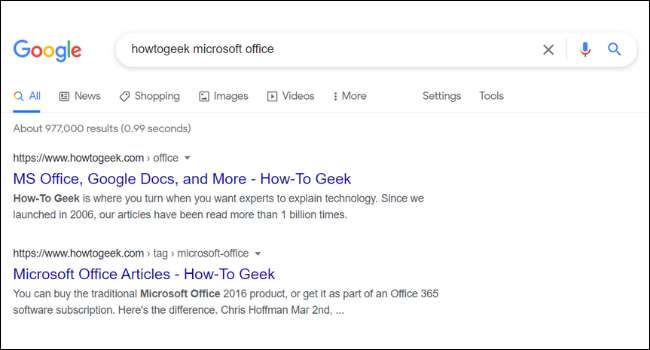
Sous l'URL et le titre de chaque résultat de recherche dans Google, vous trouverez une brève description de la page. Ces descriptions sont appelées extraits. Vous remarquerez peut-être que l'extrait d'une page de Google ne s'aligne pas toujours avec le contenu réel du site Web. C'est parce que de nombreux sites Web ont appelé " méta tags , "Descriptions personnalisées que les propriétaires de site ajoutent à leurs pages.
Les propriétaires de sites proposent souvent des descriptions de métadonnées séduisantes écrites pour vous donner envie de cliquer sur un site Web. Google énumère également d'autres méta-informations, telles que les prix et la disponibilité des stocks. Ceci est particulièrement utile pour ceux qui exécutent des sites Web de commerce électronique.
Votre recherche
La recherche sur le Web est une partie essentielle de l'utilisation d'Internet. La recherche sur le Web est un excellent moyen de découvrir de nouveaux sites Web, magasins, communautés et intérêts. Chaque jour, web crawlers visitent des millions de pages et ajoutez-les aux moteurs de recherche. Bien que les crawlers aient des effectifs, comme prendre des ressources sur le site, ils sont inestimables pour les propriétaires de sites et les visiteurs.
EN RELATION: Comment supprimer les 15 dernières minutes de l'historique de recherche de Google






?")
