ASCII, UTF-8, ISO-8859… Być może widzieliście te dziwne monikery, ale co one właściwie oznaczają? Czytaj dalej, ponieważ wyjaśniamy, czym jest kodowanie znaków i jak te akronimy odnoszą się do zwykłego tekstu, który widzimy na ekranie.
Podstawowe bloki konstrukcyjne
Kiedy mówimy o języku pisanym, mówimy o literach, które są budulcem słów, z których następnie budujemy zdania, akapity i tak dalej. Litery to symbole przedstawiające dźwięki. Kiedy mówisz o języku, mówisz o grupach dźwięków, które łączą się, tworząc jakieś znaczenie. Każdy system językowy ma złożony zestaw reguł i definicji, które rządzą tymi znaczeniami. Jeśli masz słowo, jest bezużyteczne, chyba że wiesz, z jakiego języka pochodzi, i używasz go z innymi, którzy mówią w tym języku.
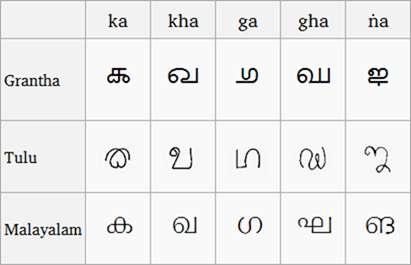
(Porównanie skryptów Grantha, Tulu i Malayalam, zdjęcie z Wikipedia )
W świecie komputerów używamy terminu „postać”. Znak jest czymś w rodzaju abstrakcyjnego pojęcia, definiowanego przez określone parametry, ale jest podstawową jednostką znaczeniową. Łacińskie „A” to nie to samo, co greckie „alfa” czy arabskie „alif”, ponieważ mają różne konteksty - pochodzą z różnych języków i mają nieco inną wymowę - więc możemy powiedzieć, że są to różne znaki. Wizualna reprezentacja znaku nazywana jest „glifem”, a różne zestawy glifów nazywane są czcionkami. Grupy postaci należą do „zestawu” lub „repertuaru”.
Kiedy wpisujesz akapit i zmieniasz czcionkę, nie zmieniasz wartości fonetycznych liter, ale zmieniasz ich wygląd. To tylko kosmetyczne (ale nie bez znaczenia!). Niektóre języki, takie jak starożytny egipski i chiński, mają ideogramy; reprezentują one całe idee zamiast dźwięków, a ich wymowa może się zmieniać w czasie i odległości. Jeśli zastępujesz jeden znak innym, zastępujesz pomysł. To coś więcej niż tylko zmiana liter, to zmiana ideogramu.
Kodowanie znaków

(Zdjęcie z Wikipedia )
Kiedy wpisujesz coś na klawiaturze lub ładujesz plik, skąd komputer wie, co wyświetlić? Do tego służy kodowanie znaków. Tekst na komputerze to nie litery, to seria sparowanych wartości alfanumerycznych. Kodowanie znaków działa jak klucz, dla którego wartości odpowiadają danym znakom, podobnie jak ortografia narzuca, które dźwięki odpowiadają którym literom. Kod Morse'a to rodzaj kodowania znaków. Wyjaśnia, w jaki sposób grupy długich i krótkich jednostek, takie jak sygnały dźwiękowe, reprezentują znaki. W alfabecie Morse'a znaki to tylko angielskie litery, cyfry i kropki. Istnieje wiele komputerowych kodowań znaków, które przekładają się na litery, cyfry, znaki akcentu, znaki interpunkcyjne, symbole międzynarodowe i tak dalej.
Często w tym temacie używany jest również termin „strony kodowe”. Zasadniczo są to kodowania znaków używane przez określone firmy, często z niewielkimi modyfikacjami. Na przykład strona kodowa Windows 1252 (wcześniej znana jako ANSI 1252) jest zmodyfikowaną formą ISO-8859-1. Są one najczęściej używane jako system wewnętrzny w odniesieniu do standardowych i zmodyfikowanych kodowań znaków, które są specyficzne dla tych samych systemów. Na początku kodowanie znaków nie było tak ważne, ponieważ komputery nie komunikowały się ze sobą. Ponieważ internet zyskuje na znaczeniu, a tworzenie sieci jest częstym zjawiskiem, staje się coraz ważniejszy w naszym codziennym życiu, nawet nie zdając sobie z tego sprawy.
Wiele różnych typów
(Zdjęcie z sarah sosiak )
Istnieje wiele różnych kodowań znaków i jest wiele powodów. To, które kodowanie znaków wybierzesz, zależy od Twoich potrzeb. Jeśli komunikujesz się po rosyjsku, sensowne jest użycie kodowania znaków, które dobrze obsługuje cyrylicę. Jeśli komunikujesz się po koreańsku, przydałoby się coś, co dobrze reprezentuje Hangul i Hanja. Jeśli jesteś matematykiem, potrzebujesz czegoś, co ma dobrze przedstawione wszystkie symbole naukowe i matematyczne, a także glify greckie i łacińskie. Jeśli jesteś dowcipnisiem, może byś na tym skorzystał tekst do góry nogami . A jeśli chcesz, aby wszystkie tego typu dokumenty były przeglądane przez dowolną osobę, potrzebujesz kodowania, które jest dość powszechne i łatwo dostępne.
Przyjrzyjmy się niektórym z bardziej powszechnych.
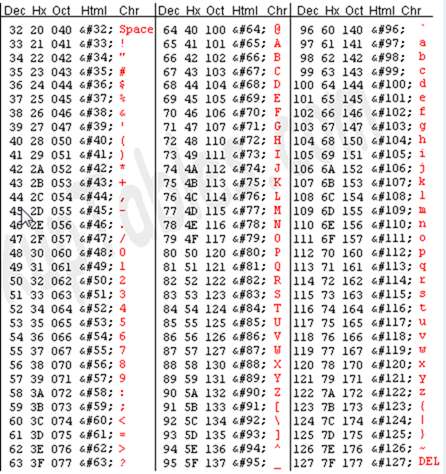
(Fragment tabeli ASCII, obraz z asciitable.com )
- ASCII - American Standard Code for Information Interchange to jedno ze starszych kodowań znaków. Został pierwotnie opracowany w oparciu o kody telegraficzne i ewoluował z czasem, aby zawierać więcej symboli i niektóre przestarzałe niedrukowane znaki kontrolne. Jest prawdopodobnie tak prosty, jak to tylko możliwe, jeśli chodzi o nowoczesne systemy, ponieważ ogranicza się do alfabetu łacińskiego bez znaków akcentowanych. Jego 7-bitowe kodowanie dopuszcza tylko 128 znaków, dlatego na całym świecie jest używanych kilka nieoficjalnych wariantów.
- ISO-8859 - Najpowszechniej stosowaną grupą kodowania znaków Międzynarodowej Organizacji Normalizacyjnej jest numer 8859. Każde konkretne kodowanie jest oznaczone numerem, często poprzedzonym opisowym monikerem, np. ISO-8859-3 (Latin-3), ISO-8859-6 (Latin / Arabic). Jest to nadzbiór ASCII, co oznacza, że pierwszych 128 wartości w kodowaniu jest takich samych jak ASCII. Jest jednak 8-bitowy i pozwala na 256 znaków, więc opiera się na nim i zawiera znacznie szerszy zakres znaków, przy czym każde kodowanie koncentruje się na innym zestawie kryteriów. Latin-1 zawiera kilka akcentowanych liter i symboli, ale później został zastąpiony poprawionym zestawem o nazwie Latin-9, który zawiera zaktualizowane glify, takie jak symbol euro.
(Fragment tybetańskiego skryptu, Unicode v4, z unicode.org )
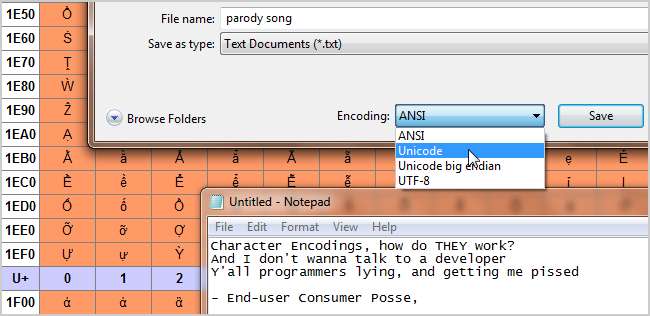
- Unicode - Ten standard kodowania ma na celu uniwersalność. Obecnie zawiera 93 skrypty zorganizowane w kilka bloków, a wiele innych jest w przygotowaniu. Unicode działa inaczej niż inne zestawy znaków, ponieważ zamiast bezpośrednio kodować glif, każda wartość jest kierowana dalej do „punktu kodowego”. Są to wartości szesnastkowe, które odpowiadają znakom, ale same glify są dostarczane w sposób odłączony przez program, na przykład przeglądarkę internetową. Te punkty kodowe są zwykle przedstawiane w następujący sposób: U + 0040 (co oznacza ‘@’ ). Konkretne kodowania w standardzie Unicode to UTF-8 i UTF-16. UTF-8 próbuje zapewnić maksymalną kompatybilność z ASCII. Jest 8-bitowy, ale dopuszcza wszystkie znaki za pomocą mechanizmu podstawiania i wielu par wartości na znak. UTF-16 zapewnia doskonałą kompatybilność ASCII, zapewniając pełniejszą 16-bitową zgodność ze standardem.
- ISO-10646 - To nie jest rzeczywiste kodowanie, tylko zestaw znaków Unicode, który został znormalizowany przez ISO. Jest to szczególnie ważne, ponieważ jest to repertuar znaków używany przez HTML. Brakuje niektórych bardziej zaawansowanych funkcji zapewnianych przez Unicode, które umożliwiają sortowanie i pisanie od prawej do lewej obok skryptu od lewej do prawej. Mimo to działa bardzo dobrze w Internecie, ponieważ pozwala na użycie szerokiej gamy skryptów i pozwala przeglądarce interpretować glify. To sprawia, że lokalizacja jest nieco łatwiejsza.
Jakiego kodowania powinienem używać?
Cóż, ASCII działa dla większości osób mówiących po angielsku, ale niewiele więcej. Częściej będziesz widzieć ISO-8859-1, który działa w większości języków zachodnioeuropejskich. Inne wersje ISO-8859 działają dla cyrylicy, arabskiego, greckiego i innych specyficznych skryptów. Jeśli jednak chcesz wyświetlić wiele skryptów w tym samym dokumencie lub na tej samej stronie internetowej, UTF-8 zapewnia znacznie lepszą kompatybilność. Działa również bardzo dobrze dla osób, które używają właściwej interpunkcji, symboli matematycznych lub znaków spontanicznych, takich jak kwadraty i pola wyboru .

(Wiele języków w jednym dokumencie, zrzut ekranu gujaratsamachar.com )
Każdy zestaw ma jednak wady. ASCII ma ograniczone znaki interpunkcyjne, więc nie działa niezwykle dobrze w przypadku poprawnych typograficznie edycji. Czy kiedykolwiek pisałeś kopiuj / wklej z programu Word tylko po to, aby uzyskać dziwną kombinację glifów? To jest wada ISO-8859, a właściwie jego domniemana interoperacyjność ze stronami kodowymi specyficznymi dla systemu operacyjnego (patrzymy na CIEBIE, Microsoft!). Główną wadą UTF-8 jest brak odpowiedniego wsparcia w aplikacjach do edycji i publikacji. Innym problemem jest to, że przeglądarki często nie interpretują i po prostu wyświetlają znacznik kolejności bajtów znaku zakodowanego w UTF-8. Powoduje to wyświetlanie niechcianych glifów. Oczywiście zadeklarowanie jednego kodowania i użycie znaków z innego bez deklarowania / odwoływania się do nich poprawnie na stronie internetowej utrudnia przeglądarkom ich prawidłowe renderowanie, a wyszukiwarkom ich odpowiednie indeksowanie.
W przypadku własnych dokumentów, rękopisów itp. Możesz użyć wszystkiego, czego potrzebujesz, aby wykonać zadanie. Jeśli chodzi o internet, wydaje się jednak, że większość ludzi zgadza się na używanie wersji UTF-8, która nie używa znaku kolejności bajtów, ale nie jest to całkowicie jednomyślne. Jak widać, każde kodowanie znaków ma swoje własne zastosowanie, kontekst oraz mocne i słabe strony. Jako użytkownik końcowy prawdopodobnie nie będziesz musiał się tym zajmować, ale teraz możesz zrobić dodatkowy krok naprzód, jeśli tak zdecydujesz.







