ASCII, UTF-8, ISO-8859… आपने इन अजीबोगरीब मुनियों को घूमते हुए देखा होगा, लेकिन वास्तव में इसका क्या मतलब है? आगे पढ़िए कि हम बताते हैं कि कौन सा वर्ण एन्कोडिंग है और ये समक्रमिक उस सादे पाठ से संबंधित हैं जिसे हम स्क्रीन पर देखते हैं।
मौलिक बिल्डिंग ब्लॉक्स
जब हम लिखित भाषा के बारे में बात करते हैं, तो हम अक्षरों को शब्दों के निर्माण खंड होने के बारे में बात करते हैं, जो तब वाक्य, पैराग्राफ और इसी तरह का निर्माण करते हैं। पत्र प्रतीक हैं जो ध्वनियों का प्रतिनिधित्व करते हैं। जब आप भाषा के बारे में बात करते हैं, तो आप उन ध्वनियों के समूह के बारे में बात कर रहे हैं जो किसी प्रकार का अर्थ बनाने के लिए एक साथ आते हैं। प्रत्येक भाषा प्रणाली में नियमों और परिभाषाओं का एक जटिल समूह होता है जो उन अर्थों को नियंत्रित करता है। यदि आपके पास एक शब्द है, तो यह तब तक बेकार है जब तक आप यह नहीं जानते कि यह किस भाषा का है और आप इसका उपयोग दूसरों के साथ करते हैं जो उस भाषा को बोलते हैं।
(ग्रांथा, तुलु, और मलयालम लिपियों की छवि, से छवि विकिपीडिया )
कंप्यूटर की दुनिया में, हम "वर्ण" शब्द का उपयोग करते हैं। एक चरित्र एक अमूर्त अवधारणा की तरह है, जिसे विशिष्ट मापदंडों द्वारा परिभाषित किया गया है, लेकिन यह अर्थ की मौलिक इकाई है। लैटिन ‘ए’ ग्रीक ’अल्फा’ या अरबी ‘अलिफ’ के समान नहीं है क्योंकि उनके अलग-अलग संदर्भ हैं - वे अलग-अलग भाषाओं से हैं और थोड़ा अलग उच्चारण हैं - इसलिए हम कह सकते हैं कि वे अलग-अलग वर्ण हैं। एक चरित्र के दृश्य प्रतिनिधित्व को "ग्लिफ़" कहा जाता है और ग्लिफ़ के विभिन्न सेटों को फोंट कहा जाता है। पात्रों के समूह एक "सेट" या एक "प्रदर्शनों की सूची" से संबंधित हैं।
जब आप एक पैराग्राफ टाइप करते हैं और आप फ़ॉन्ट बदलते हैं, तो आप अक्षरों के ध्वन्यात्मक मानों को नहीं बदल रहे हैं, आप यह देख रहे हैं कि आप कैसे दिख रहे हैं। यह सिर्फ कॉस्मेटिक है (लेकिन महत्वहीन नहीं है!)। कुछ भाषाएं, जैसे प्राचीन मिस्र और चीनी, में विचारधाराएं हैं; ये ध्वनियों के बजाय पूरे विचारों का प्रतिनिधित्व करते हैं, और उनके उच्चारण समय और दूरी के अनुसार भिन्न हो सकते हैं। यदि आप एक वर्ण को दूसरे के लिए प्रतिस्थापित करते हैं, तो आप एक विचार को प्रतिस्थापित कर रहे हैं। यह केवल पत्र बदलने से अधिक है, यह एक विचारधारा बदल रहा है।
अक्षरों को सांकेतिक अक्षरों में बदलना

(छवि से विकिपीडिया )
जब आप कीबोर्ड पर कुछ टाइप करते हैं, या एक फाइल लोड करते हैं, तो कंप्यूटर को कैसे पता चलता है कि क्या प्रदर्शित करना है? यह किस वर्ण एन्कोडिंग के लिए है आपके कंप्यूटर पर पाठ वास्तव में पत्र नहीं है, यह युग्मित अल्फ़ान्यूमेरिक मूल्यों की एक श्रृंखला है। चरित्र एन्कोडिंग एक कुंजी के रूप में कार्य करता है जिसके लिए मान किस वर्ण के अनुरूप होते हैं, बहुत कुछ यह है कि ऑर्थोग्राफी किस प्रकार के अक्षरों के अनुरूप है। मोर्स कोड एक तरह का कैरेक्टर एन्कोडिंग है। यह बताता है कि बीप्स जैसे लंबी और छोटी इकाइयों के समूह किस प्रकार वर्णों का प्रतिनिधित्व करते हैं। मोर्स कोड में, अक्षर सिर्फ अंग्रेजी अक्षर, संख्या और पूर्ण विराम हैं। कई कंप्यूटर वर्ण एन्कोडिंग हैं जो अक्षरों, संख्याओं, उच्चारण चिह्न, विराम चिह्न, अंतर्राष्ट्रीय प्रतीकों और इतने पर अनुवाद करते हैं।
अक्सर इस विषय पर, "कोड पृष्ठ" शब्द का भी उपयोग किया जाता है। वे अनिवार्य रूप से चरित्र एन्कोडिंग हैं जैसा कि विशिष्ट कंपनियों द्वारा उपयोग किया जाता है, अक्सर मामूली संशोधनों के साथ। उदाहरण के लिए, विंडोज 1252 कोड पेज (जिसे पहले ANSI 1252 के रूप में जाना जाता है) ISO-8859-1 का संशोधित रूप है। वे ज्यादातर मानक और संशोधित चरित्र एन्कोडिंग को संदर्भित करने के लिए एक आंतरिक प्रणाली के रूप में उपयोग किए जाते हैं जो समान प्रणालियों के लिए विशिष्ट हैं। आरंभ में, वर्ण एन्कोडिंग इतना महत्वपूर्ण नहीं था क्योंकि कंप्यूटर एक दूसरे के साथ संवाद नहीं करते थे। इंटरनेट के प्रमुख होने और नेटवर्किंग के एक सामान्य घटना होने के साथ, यह हमारे दिन-प्रतिदिन के जीवन का एक महत्वपूर्ण हिस्सा बन गया है, यहां तक कि इसे साकार किए बिना।
कई अलग-अलग प्रकार
(छवि से सरह सोसिाक )
वहाँ विभिन्न चरित्र एन्कोडिंग के बहुत सारे हैं, और उसके लिए बहुत सारे कारण हैं। आप किस चरित्र एन्कोडिंग का उपयोग करने के लिए चुनते हैं, यह इस बात पर निर्भर करता है कि आपकी ज़रूरतें क्या हैं। यदि आप रूसी में संवाद करते हैं, तो यह एक चरित्र एन्कोडिंग का उपयोग करने के लिए समझ में आता है जो सिरिलिक अच्छी तरह से समर्थन करता है। यदि आप कोरियाई में संवाद करते हैं, तो आप कुछ ऐसा चाहते हैं जो हंगुल और हंजा का प्रतिनिधित्व करे। यदि आप एक गणितज्ञ हैं, तो आप ऐसा कुछ चाहते हैं जिसमें सभी वैज्ञानिक और गणितीय प्रतीकों का अच्छी तरह से प्रतिनिधित्व किया गया हो, साथ ही साथ ग्रीक और लैटिन ग्लिफ़ भी। यदि आप एक मसखरा हैं, तो शायद आप इससे लाभान्वित हों उल्टा पाठ । और, यदि आप चाहते हैं कि उन सभी प्रकार के दस्तावेज़ों को किसी भी व्यक्ति द्वारा देखा जाए, तो आप ऐसा एन्कोडिंग चाहते हैं जो बहुत ही सामान्य और आसानी से सुलभ हो।
आइए कुछ अधिक सामान्य लोगों पर एक नज़र डालें।
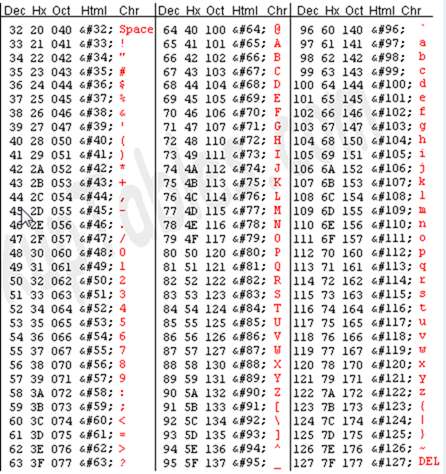
(ASCII तालिका का अंश, छवि से ास्कीटाब्ले.कॉम )
- ASCII - अमेरिकन स्टैंडर्ड कोड फॉर इंफॉर्मेशन इंटरचेंज पुराने कैरेक्टर एनकोडिंग में से एक है। यह मूल रूप से टेलीग्राफिक कोड के आधार पर तैयार किया गया था और समय के साथ-साथ अधिक प्रतीकों और कुछ पुराने-गैर-मुद्रित नियंत्रण वर्णों को शामिल करने के लिए विकसित हुआ। यह संभवतः आधुनिक प्रणालियों के संदर्भ में उतना ही बुनियादी है, जितना कि बिना उच्चारण पात्रों के लैटिन वर्णमाला तक सीमित। इसकी 7-बिट एन्कोडिंग केवल 128 वर्णों के लिए अनुमति देती है, यही वजह है कि दुनिया भर में कई अनौपचारिक संस्करण हैं।
- आईएसओ 8859 - मानकीकरण के लिए अंतर्राष्ट्रीय संगठन चरित्र एन्कोडिंग का सबसे व्यापक रूप से उपयोग किया जाने वाला समूह संख्या 8859 है। प्रत्येक विशिष्ट एन्कोडिंग को एक संख्या द्वारा निर्दिष्ट किया जाता है, जिसे अक्सर वर्णनात्मक मॉनीकर द्वारा उपसर्ग किया जाता है, उदा। ISO-8859-3 (लैटिन -3), ISO-8859-6 (लैटिन / अरबी)। यह ASCII का सुपरसेट है, जिसका अर्थ है कि एन्कोडिंग में पहले 128 मान ASCII के समान हैं। हालाँकि, यह 8-बिट है, और 256 वर्णों के लिए अनुमति देता है, इसलिए यह वहाँ से दूर बनाता है और वर्णों का एक बहुत व्यापक सरणी शामिल करता है, जिसमें प्रत्येक विशिष्ट एन्कोडिंग मापदंड के एक अलग सेट पर ध्यान केंद्रित करता है। लैटिन -1 में उच्चारण अक्षरों और प्रतीकों का एक समूह शामिल था, लेकिन बाद में इसे लैटिन -9 नामक एक संशोधित सेट के साथ बदल दिया गया, जिसमें यूरो प्रतीक जैसे अपडेट किए गए ग्लिफ़ शामिल हैं।
(तिब्बती लिपि का अंश, यूनिकोड v4, से यूनिकोड.ऑर्ग )
- यूनिकोड - इस एन्कोडिंग मानक का उद्देश्य सार्वभौमिकता है। इसमें वर्तमान में कई खंडों में आयोजित 93 लिपियों को शामिल किया गया है, जिसमें कई और कार्य भी हैं। यूनिकोड अन्य वर्ण सेटों की तुलना में अलग तरीके से काम करता है जिसमें सीधे ग्लिफ़ के लिए कोडिंग के बजाय, प्रत्येक मान को "कोड बिंदु" पर आगे निर्देशित किया जाता है। ये हेक्साडेसिमल मान हैं जो वर्णों से मेल खाते हैं लेकिन ग्लिफ़ स्वयं प्रोग्राम द्वारा अलग तरीके से प्रदान किए जाते हैं, जैसे कि आपका वेब ब्राउज़र। ये कोड बिंदु आमतौर पर निम्नानुसार दर्शाए गए हैं: U + 0040 (जो अनुवाद करता है ‘@’ )। यूनिकोड मानक के तहत विशिष्ट एनकोडिंग UTF-8 और UTF-16 हैं। UTF-8 ASCII के साथ अधिकतम संगतता के लिए अनुमति देने का प्रयास करता है। यह 8-बिट है, लेकिन एक प्रतिस्थापन तंत्र और प्रति चरित्र के कई जोड़े मूल्यों के माध्यम से सभी वर्णों के लिए अनुमति देता है। UTF-16 मानक के साथ एक अधिक पूर्ण 16-बिट संगतता के लिए सही ASCII संगतता को खोदता है।
- आईएसओ 10646 - यह एक वास्तविक एन्कोडिंग नहीं है, बस यूनिकोड का एक सेट है जिसे आईएसओ द्वारा मानकीकृत किया गया है। यह सबसे महत्वपूर्ण है क्योंकि यह HTML द्वारा उपयोग किए गए चरित्र प्रदर्शनों की सूची है। यूनिकोड द्वारा प्रदान किए गए कुछ और अधिक उन्नत कार्य जो बाएं से दाएं स्क्रिप्टिंग के साथ-साथ टकराव और दाएं-बाएं की अनुमति देते हैं, गायब है। फिर भी, यह इंटरनेट पर उपयोग के लिए बहुत अच्छी तरह से काम करता है क्योंकि यह विभिन्न प्रकार की लिपियों के उपयोग की अनुमति देता है और ब्राउज़र को ग्लाइकल्स की व्याख्या करने की अनुमति देता है। इससे स्थानीयकरण कुछ हद तक आसान हो जाता है।
मुझे किस एन्कोडिंग का उपयोग करना चाहिए?
खैर, ASCII अधिकांश अंग्रेजी बोलने वालों के लिए काम करता है, लेकिन बहुत अधिक के लिए नहीं। अधिक बार आप ISO-8859-1 देख रहे होंगे, जो अधिकांश पश्चिमी यूरोपीय भाषाओं के लिए काम करता है। ISO-8859 के अन्य संस्करण सिरिलिक, अरबी, ग्रीक या अन्य विशिष्ट लिपियों के लिए काम करते हैं। हालाँकि, यदि आप एक ही दस्तावेज़ में या एक ही वेब पेज पर कई स्क्रिप्ट प्रदर्शित करना चाहते हैं, तो UTF-8 बहुत बेहतर संगतता की अनुमति देता है। यह उन लोगों के लिए भी वास्तव में अच्छी तरह से काम करता है जो उचित विराम चिह्न, गणित प्रतीकों या ऑफ-द-कफ वर्णों का उपयोग करते हैं, जैसे कि वर्गों और चेकबॉक्स .

(एक दस्तावेज़ में कई भाषाएँ, का स्क्रीनशॉट गुजरातसमाचार.कॉम )
हालांकि, प्रत्येक सेट में कमियां हैं। ASCII अपने विराम चिह्नों में सीमित है, इसलिए यह टाइपोग्राफिक रूप से सही संपादन के लिए अविश्वसनीय रूप से अच्छी तरह से काम नहीं करता है। कभी शब्द से कॉपी / पेस्ट टाइप करें केवल ग्लिफ़ के कुछ अजीब संयोजन के लिए? यह ISO-8859 की खामी है, या अधिक सही ढंग से, ओएस-विशिष्ट कोड पेजों के साथ इसकी अंतर-संचालनशीलता (हम आपको, Microsoft देख रहे हैं!)। UTF-8 की बड़ी कमी संपादन और प्रकाशन अनुप्रयोगों में उचित समर्थन की कमी है। एक और समस्या यह है कि ब्राउज़र अक्सर व्याख्या नहीं करते हैं और बस UTF-8 एन्कोडेड वर्ण का बाइट ऑर्डर चिह्न प्रदर्शित करते हैं। इससे अवांछित ग्लिफ़ प्रदर्शित होते हैं। और निश्चित रूप से, एक एन्कोडिंग की घोषणा करना और एक वेब पेज पर उन्हें ठीक से घोषित / संदर्भित किए बिना किसी दूसरे से वर्णों का उपयोग करना, ब्राउज़रों के लिए उन्हें सही तरीके से प्रस्तुत करना और खोज इंजन के लिए उन्हें उचित रूप से अनुक्रमित करना मुश्किल बनाता है।
अपने स्वयं के दस्तावेजों, पांडुलिपियों और इसके आगे के लिए, आप जो भी काम करना चाहते हैं उसका उपयोग कर सकते हैं। जहां तक वेब जाता है, हालांकि, ऐसा लगता है कि ज्यादातर लोग UTF-8 संस्करण का उपयोग करने पर सहमत होते हैं जो बाइट ऑर्डर मार्क का उपयोग नहीं करता है, लेकिन यह पूरी तरह से एकमत नहीं है। जैसा कि आप देख सकते हैं, प्रत्येक वर्ण एन्कोडिंग का अपना उपयोग, संदर्भ और ताकत और कमजोरियां हैं। एक अंतिम-उपयोगकर्ता के रूप में, आपको शायद इससे निपटना नहीं है, लेकिन अब यदि आप चुनते हैं तो आप अतिरिक्त कदम उठा सकते हैं।







