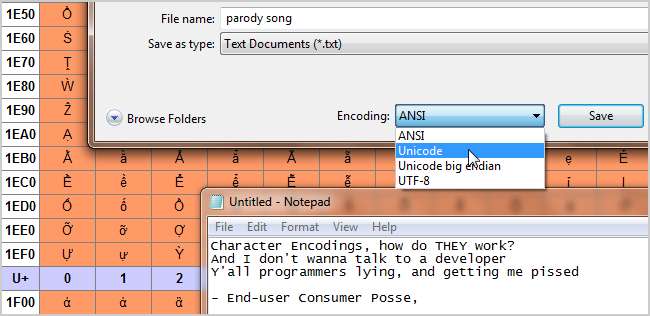
ASCII, UTF-8, ISO-8859 ... Možná jste viděli, jak se tyto podivné přezdívky vznášejí kolem, ale co vlastně znamenají? Čtěte dále, když vysvětlíme, co je kódování znaků a jak tyto zkratky souvisejí s prostým textem, který vidíme na obrazovce.
Základní stavební bloky
Když mluvíme o psaném jazyce, mluvíme o tom, že písmena jsou stavebními kameny slov, která pak vytvářejí věty, odstavce atd. Písmena jsou symboly, které představují zvuky. Když mluvíte o jazyce, mluvíte o skupinách zvuků, které se spojují a vytvářejí nějaký význam. Každý jazykový systém má složitou sadu pravidel a definic, které tyto významy řídí. Pokud máte slovo, je to k ničemu, pokud nevíte, z jakého jazyka pochází, a nepoužíváte ho s ostatními, kteří tímto jazykem mluví.
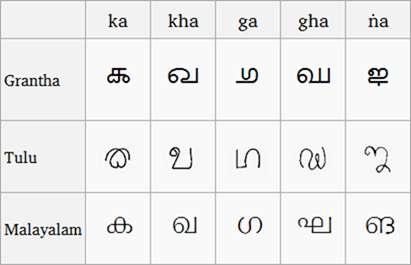
(Srovnání skriptů Grantha, Tulu a Malayalam, Obrázek z Wikipedia )
Ve světě počítačů používáme výraz „znak“. Znak je jakýmsi abstraktním pojmem definovaným konkrétními parametry, ale je to základní významová jednotka. Latinka „A“ není stejná jako řecká „alfa“ nebo arabská „alif“, protože mají různé kontexty - pocházejí z různých jazyků a mají mírně odlišnou výslovnost - takže můžeme říci, že se jedná o odlišné znaky. Vizuální reprezentace postavy se nazývá „glyf“ a různé sady glyfů se nazývají písma. Skupiny postav patří do „sady“ nebo „repertoáru“.
Když napíšete odstavec a změníte písmo, neměníte fonetické hodnoty písmen, měníte jejich vzhled. Je to jen kosmetické (ale ne nedůležité!). Některé jazyky, jako staroegyptský a čínský, mají ideogramy; tito představují celé myšlenky místo zvuků a jejich výslovnosti se mohou časem a vzdáleností lišit. Pokud nahradíte jeden znak druhým, nahradíte nápad. Je to víc než jen změna písmen, je to změna ideogramu.
Kódování znaků

(Obrázek z Wikipedia )
Když počítač něco napíšete na klávesnici nebo načtete soubor, jak počítač ví, co má zobrazit? K tomu slouží kódování znaků. Text ve vašem počítači ve skutečnosti nejsou písmena, je to řada spárovaných alfanumerických hodnot. Kódování znaků funguje jako klíč, jehož hodnoty odpovídají kterým znakům, podobně jako pravopis určuje, které zvuky odpovídají kterým písmenům. Morseova abeceda je druh kódování znaků. Vysvětluje, jak skupiny dlouhých a krátkých jednotek, jako jsou pípnutí, představují znaky. V Morseově abecedě jsou znaky pouze anglická písmena, číslice a tečky. Existuje mnoho počítačových kódování znaků, které se překládají do písmen, číslic, znaků s diakritikou, interpunkčních znamének, mezinárodních symbolů atd.
Na toto téma se často používá termín „kódové stránky“. Jsou to v podstatě kódování znaků, jak je používají konkrétní společnosti, často s drobnými úpravami. Například kódová stránka Windows 1252 (dříve známá jako ANSI 1252) je upravená forma normy ISO-8859-1. Většinou se používají jako interní systém pro označení standardních a upravených kódování znaků, které jsou specifické pro stejné systémy. Zpočátku nebylo kódování znaků tak důležité, protože počítače spolu nekomunikovaly. Vzhledem k tomu, že se internet stává stále důležitějším a síťové připojení je běžným jevem, stal se stále důležitějším pro náš každodenní život, aniž bychom si to vůbec uvědomovali.
Mnoho různých typů
(Obrázek z sarah sosiak )
Existuje spousta různých kódování znaků a existuje spousta důvodů. Které kódování znaků se rozhodnete použít závisí na tom, jaké jsou vaše potřeby. Pokud komunikujete v ruštině, má smysl použít kódování znaků, které dobře podporuje azbuku. Pokud komunikujete v korejštině, budete potřebovat něco, co dobře reprezentuje Hangul a Hanja. Pokud jste matematik, pak chcete něco, co má dobře zastoupené všechny vědecké a matematické symboly, stejně jako řecké a latinské symboly. Pokud jste šprýmař, možná byste z toho měli užitek obrácený text . A pokud chcete, aby si všechny tyto typy dokumentů mohla prohlížet kterákoli osoba, potřebujete kódování, které je docela běžné a snadno dostupné.
Podívejme se na některé z běžnějších.
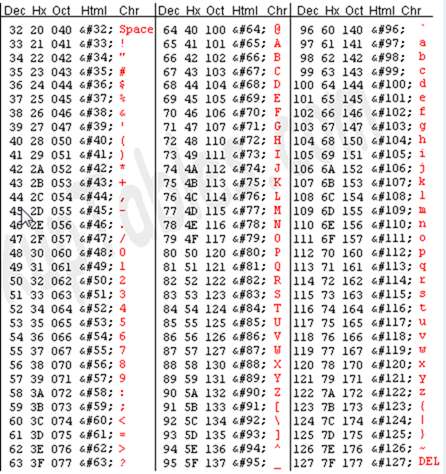
(Výňatek z ASCII tabulky, Obrázek z asciitable.com )
- ASCII - Americký standardní kód pro výměnu informací je jedním ze starších kódování znaků. Původně byl navržen na základě telegrafických kódů a postupem času se vyvíjel, aby zahrnoval více symbolů a některé dnes již zastaralé netištěné kontrolní znaky. Je to pravděpodobně tak základní, jak můžete získat, pokud jde o moderní systémy, protože je omezeno na latinskou abecedu bez znaků s diakritikou. Jeho 7bitové kódování umožňuje pouze 128 znaků, a proto se po celém světě používá několik neoficiálních variant.
- ISO-8859 - Nejčastěji používanou skupinou kódování znaků Mezinárodní organizace pro normalizaci je číslo 8859. Každé konkrétní kódování je označeno číslem, často předponou popisným přezdívkou, např. ISO-8859-3 (latinsky-3), ISO-8859-6 (latinsky / arabsky). Je to nadmnožina ASCII, což znamená, že prvních 128 hodnot v kódování je stejných jako ASCII. Je to 8-bit, ale umožňuje 256 znaků, takže se odtud odvíjí a zahrnuje mnohem širší pole znaků, přičemž každé konkrétní kódování se zaměřuje na jinou sadu kritérií. Latina-1 zahrnovala spoustu písmen a symbolů s diakritikou, ale později byla nahrazena revidovanou sadou zvanou Latina-9, která obsahuje aktualizované glyfy, jako je symbol Euro.
(Výňatek z tibetského písma, Unicode v4, z unicode.org )
- Unicode - Tento standard kódování se zaměřuje na univerzálnost. V současné době obsahuje 93 skriptů uspořádaných do několika bloků, přičemž mnoho dalších je v pracích. Unicode funguje jinak než jiné znakové sady v tom, že namísto přímého kódování glyfů je každá hodnota směrována dále na „bod kódu“. Jedná se o hexadecimální hodnoty, které odpovídají znakům, ale samotné glyfy jsou programem poskytovány odděleně, například webovým prohlížečem. Tyto body kódu jsou obvykle znázorněny následovně: U + 0040 (což znamená: ‘@’ ). Specifická kódování podle standardu Unicode jsou UTF-8 a UTF-16. UTF-8 se pokouší umožnit maximální kompatibilitu s ASCII. Je 8bitový, ale umožňuje všechny znaky pomocí substitučního mechanismu a více párů hodnot na znak. UTF-16 zbavuje perfektní kompatibilitu ASCII pro úplnější 16bitovou kompatibilitu se standardem.
- ISO-10646 - Toto není skutečné kódování, pouze znaková sada Unicode, která byla standardizována ISO. Je to hlavně důležité, protože se jedná o repertoár postav používaný HTML. Některé z pokročilejších funkcí poskytovaných Unicode, které umožňují řazení a zprava doleva vedle skriptů zleva doprava, chybí. Přesto to funguje velmi dobře pro použití na internetu, protože umožňuje použití široké škály skriptů a umožňuje prohlížeči interpretovat glyfy. Díky tomu je lokalizace o něco jednodušší.
Jaké kódování mám použít?
ASCII funguje pro většinu mluvčích angličtiny, ale ne pro mnoho jiného. Častěji uvidíte ISO-8859-1, která funguje pro většinu západoevropských jazyků. Ostatní verze ISO-8859 fungují pro cyrilici, arabštinu, řečtinu nebo jiné konkrétní skripty. Pokud však chcete zobrazit více skriptů ve stejném dokumentu nebo na stejné webové stránce, umožňuje UTF-8 mnohem lepší kompatibilitu. Funguje také velmi dobře pro lidi, kteří používají správnou interpunkci, matematické symboly nebo znaky mimo manžetu, jako například čtverce a zaškrtávací políčka .

(Více jazyků v jednom dokumentu, Screenshot z gujaratsamachar.com )
Každá sada má však své nevýhody. ASCII je omezen svými interpunkčními znaménky, takže při typograficky správných úpravách neuvěřitelně dobře nefunguje. Napsali jste někdy kopírování / vkládání z Wordu, abyste měli nějakou divnou kombinaci glyfů? To je nevýhoda ISO-8859, přesněji řečeno její předpokládaná interoperabilita s kódovými stránkami specifickými pro OS (díváme se na VÁS, Microsoft!). Hlavní nevýhodou UTF-8 je nedostatečná podpora úprav a publikování aplikací. Dalším problémem je, že prohlížeče často neinterpretují a pouze zobrazují značku pořadí bytů znaku kódovaného UTF-8. To má za následek zobrazení nežádoucích glyfů. A samozřejmě deklarovat jedno kódování a používat znaky z jiného, aniž byste je správně deklarovali / odkazovali na webové stránce, ztěžuje to prohlížečům správně je vykreslit a pro vyhledávače je vhodně indexovat.
Pro své vlastní dokumenty, rukopisy atd. Můžete k dokončení práce použít vše, co potřebujete. Pokud jde o web, zdá se, že většina lidí souhlasí s používáním verze UTF-8, která nepoužívá značku pořadí bytů, ale to není úplně jednomyslné. Jak vidíte, každé kódování znaků má své vlastní použití, kontext a silné a slabé stránky. Jako koncový uživatel to pravděpodobně nebudete muset řešit, ale nyní se můžete rozhodnout o další krok vpřed.







