ASCII, UTF-8, ISO-8859… Sie haben vielleicht diese seltsamen Moniker herumschweben sehen, aber was bedeuten sie eigentlich? Lesen Sie weiter, während wir erklären, was Zeichenkodierung ist und wie sich diese Akronyme auf den auf dem Bildschirm angezeigten Klartext beziehen.
Grundlegende Bausteine
Wenn wir über geschriebene Sprache sprechen, sprechen wir über Buchstaben als Bausteine von Wörtern, die dann Sätze, Absätze usw. bilden. Buchstaben sind Symbole, die Töne darstellen. Wenn Sie über Sprache sprechen, sprechen Sie über Gruppen von Klängen, die zusammenkommen, um eine Bedeutung zu bilden. Jedes Sprachsystem verfügt über komplexe Regeln und Definitionen, die diese Bedeutungen bestimmen. Wenn Sie ein Wort haben, ist es nutzlos, es sei denn, Sie wissen, aus welcher Sprache es stammt, und Sie verwenden es mit anderen, die diese Sprache sprechen.
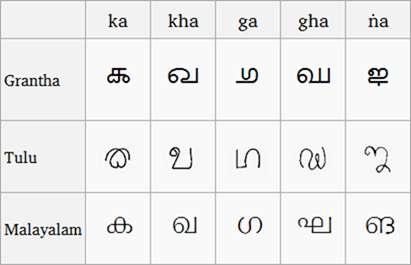
(Vergleich von Grantha-, Tulu- und Malayalam-Skripten, Bild von Wikipedia )
In der Welt der Computer verwenden wir den Begriff "Charakter". Ein Zeichen ist eine Art abstraktes Konzept, das durch bestimmte Parameter definiert wird, aber es ist die grundlegende Bedeutungseinheit. Das lateinische "A" ist nicht dasselbe wie ein griechisches "Alpha" oder ein arabisches "Alif", da sie unterschiedliche Kontexte haben - sie stammen aus verschiedenen Sprachen und haben leicht unterschiedliche Aussprachen - also können wir sagen, dass sie unterschiedliche Zeichen sind. Die visuelle Darstellung eines Zeichens wird als "Glyphe" bezeichnet, und verschiedene Sätze von Glyphen werden als Schriftarten bezeichnet. Gruppen von Charakteren gehören zu einer "Menge" oder einem "Repertoire".
Wenn Sie einen Absatz eingeben und die Schriftart ändern, ändern Sie nicht die phonetischen Werte der Buchstaben, sondern deren Aussehen. Es ist nur kosmetisch (aber nicht unwichtig!). Einige Sprachen, wie Altägyptisch und Chinesisch, haben Ideogramme; Diese repräsentieren ganze Ideen anstelle von Tönen, und ihre Aussprachen können über Zeit und Entfernung variieren. Wenn Sie ein Zeichen durch ein anderes ersetzen, ersetzen Sie eine Idee. Es ist mehr als nur das Ändern von Buchstaben, es ändert ein Ideogramm.
Zeichenkodierung

(Bild von Wikipedia )
Woher weiß der Computer, was angezeigt werden soll, wenn Sie etwas auf der Tastatur eingeben oder eine Datei laden? Dafür ist die Zeichenkodierung gedacht. Text auf Ihrem Computer besteht eigentlich nicht aus Buchstaben, sondern aus einer Reihe gepaarter alphanumerischer Werte. Die Zeichenkodierung fungiert als Schlüssel dafür, welche Werte welchen Zeichen entsprechen, ähnlich wie die Orthographie vorschreibt, welche Klänge welchen Buchstaben entsprechen. Morsecode ist eine Art Zeichenkodierung. Es wird erklärt, wie Gruppen von langen und kurzen Einheiten wie Signaltöne Zeichen darstellen. Im Morsecode sind die Zeichen nur englische Buchstaben, Zahlen und Punkte. Es gibt viele Computerzeichencodierungen, die in Buchstaben, Zahlen, Akzentzeichen, Satzzeichen, internationale Symbole usw. übersetzt werden.
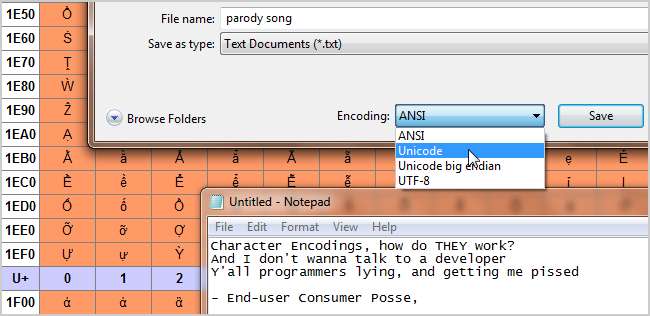
In diesem Thema wird häufig auch der Begriff „Codepages“ verwendet. Es handelt sich im Wesentlichen um Zeichencodierungen, wie sie von bestimmten Unternehmen verwendet werden, häufig mit geringfügigen Änderungen. Beispielsweise ist die Windows 1252-Codepage (früher als ANSI 1252 bekannt) eine modifizierte Form der ISO-8859-1. Sie werden hauptsächlich als internes System verwendet, um auf Standard- und modifizierte Zeichencodierungen zu verweisen, die für dieselben Systeme spezifisch sind. Schon früh war die Zeichenkodierung nicht so wichtig, da Computer nicht miteinander kommunizierten. Da das Internet immer bekannter wird und Networking häufig vorkommt, wird es zu einem immer wichtigeren Bestandteil unseres täglichen Lebens, ohne dass wir es überhaupt bemerken.
Viele verschiedene Arten
(Bild von sarah sosiak )
Es gibt viele verschiedene Zeichencodierungen, und dafür gibt es viele Gründe. Welche Zeichenkodierung Sie verwenden, hängt von Ihren Anforderungen ab. Wenn Sie auf Russisch kommunizieren, ist es sinnvoll, eine Zeichenkodierung zu verwenden, die Kyrillisch gut unterstützt. Wenn Sie auf Koreanisch kommunizieren, möchten Sie etwas, das Hangul und Hanja gut repräsentiert. Wenn Sie Mathematiker sind, möchten Sie etwas, bei dem alle wissenschaftlichen und mathematischen Symbole sowie die griechischen und lateinischen Glyphen gut dargestellt sind. Wenn Sie ein Schelm sind, profitieren Sie vielleicht davon verkehrter Text . Und wenn Sie möchten, dass alle diese Arten von Dokumenten von einer bestimmten Person angezeigt werden, möchten Sie eine Codierung, die ziemlich häufig und leicht zugänglich ist.
Werfen wir einen Blick auf einige der gebräuchlichsten.
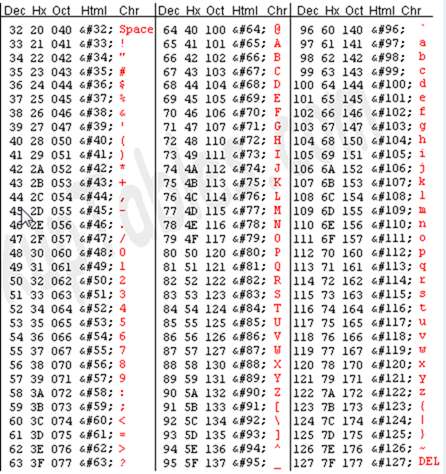
(Auszug aus der ASCII-Tabelle, Bild von asciitable.com )
- ASCII - Der amerikanische Standardcode für den Informationsaustausch ist eine der älteren Zeichencodierungen. Es wurde ursprünglich auf der Grundlage von Telegraphencodes entwickelt und im Laufe der Zeit um weitere Symbole und einige inzwischen veraltete, nicht gedruckte Steuerzeichen erweitert. Es ist wahrscheinlich so einfach wie es in Bezug auf moderne Systeme nur möglich ist, da es auf das lateinische Alphabet ohne akzentuierte Zeichen beschränkt ist. Die 7-Bit-Codierung erlaubt nur 128 Zeichen, weshalb weltweit mehrere inoffizielle Varianten verwendet werden.
- ISO-8859 - Die am häufigsten verwendete Gruppe von Zeichencodierungen der Internationalen Organisation für Normung ist die Nummer 8859. Jede spezifische Codierung wird durch eine Nummer gekennzeichnet, der häufig ein beschreibender Spitzname vorangestellt wird, z. ISO-8859-3 (Latein-3), ISO-8859-6 (Latein / Arabisch). Es ist eine Obermenge von ASCII, was bedeutet, dass die ersten 128 Werte in der Codierung mit ASCII identisch sind. Es ist jedoch 8-Bit und erlaubt 256 Zeichen. Daher baut es von dort aus auf und enthält eine viel größere Anzahl von Zeichen, wobei sich jede spezifische Codierung auf einen anderen Kriteriensatz konzentriert. Latin-1 enthielt eine Reihe von Buchstaben und Symbolen mit Akzent, wurde jedoch später durch ein überarbeitetes Set namens Latin-9 ersetzt, das aktualisierte Glyphen wie das Euro-Symbol enthält.
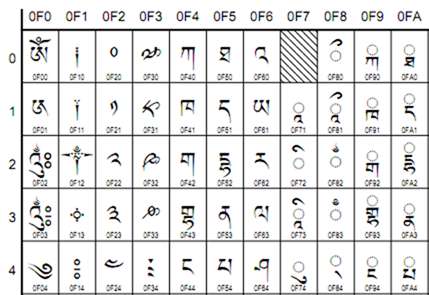
(Auszug aus der tibetischen Schrift, Unicode v4, aus unicode.org )
- Unicode - Dieser Kodierungsstandard zielt auf Universalität ab. Es enthält derzeit 93 Skripte, die in mehreren Blöcken organisiert sind, viele weitere sind in Arbeit. Unicode funktioniert anders als andere Zeichensätze, da jeder Wert nicht direkt für eine Glyphe codiert, sondern weiter auf einen „Codepunkt“ gerichtet ist. Hierbei handelt es sich um hexadezimale Werte, die Zeichen entsprechen. Die Glyphen selbst werden jedoch vom Programm, z. B. Ihrem Webbrowser, getrennt bereitgestellt. Diese Codepunkte werden üblicherweise wie folgt dargestellt: U + 0040 (übersetzt in ‘@’ ). Spezifische Codierungen nach dem Unicode-Standard sind UTF-8 und UTF-16. UTF-8 versucht, maximale Kompatibilität mit ASCII zu ermöglichen. Es ist 8-Bit, ermöglicht jedoch alle Zeichen über einen Substitutionsmechanismus und mehrere Wertepaare pro Zeichen. UTF-16-Gräben bieten perfekte ASCII-Kompatibilität für eine vollständigere 16-Bit-Kompatibilität mit dem Standard.
- ISO-10646 - Dies ist keine tatsächliche Codierung, sondern nur ein von der ISO standardisierter Unicode-Zeichensatz. Dies ist vor allem deshalb wichtig, weil es sich um das von HTML verwendete Zeichenrepertoire handelt. Einige der erweiterten Funktionen von Unicode, die die Sortierung und die Skripterstellung von rechts nach links neben der Skripterstellung von links nach rechts ermöglichen, fehlen. Trotzdem funktioniert es sehr gut für die Verwendung im Internet, da es die Verwendung einer Vielzahl von Skripten ermöglicht und es dem Browser ermöglicht, die Glyphen zu interpretieren. Dies erleichtert die Lokalisierung etwas.
Welche Codierung soll ich verwenden?
Nun, ASCII funktioniert für die meisten Englisch sprechenden Personen, aber nicht für viele andere. Häufiger sehen Sie ISO-8859-1, das für die meisten westeuropäischen Sprachen funktioniert. Die anderen Versionen von ISO-8859 funktionieren für kyrillische, arabische, griechische oder andere spezifische Skripte. Wenn Sie jedoch mehrere Skripte in demselben Dokument oder auf derselben Webseite anzeigen möchten, bietet UTF-8 eine wesentlich bessere Kompatibilität. Es funktioniert auch sehr gut für Leute, die korrekte Interpunktion, mathematische Symbole oder Zeichen ohne Manschette verwenden, wie z Quadrate und Kontrollkästchen .

(Mehrere Sprachen in einem Dokument, Screenshot von gujaratsamachar.com )
Jeder Satz weist jedoch Nachteile auf. ASCII ist in seinen Satzzeichen begrenzt, sodass es für typografisch korrekte Änderungen nicht besonders gut funktioniert. Haben Sie jemals Copy / Paste aus Word eingegeben, um eine seltsame Kombination von Glyphen zu erhalten? Dies ist der Nachteil von ISO-8859 oder genauer gesagt der angeblichen Interoperabilität mit betriebssystemspezifischen Codepages (wir sehen uns SIE, Microsoft!). Der Hauptnachteil von UTF-8 ist die mangelnde Unterstützung beim Bearbeiten und Veröffentlichen von Anwendungen. Ein weiteres Problem besteht darin, dass Browser häufig die Bytereihenfolge eines UTF-8-codierten Zeichens nicht interpretieren und nur anzeigen. Dies führt dazu, dass unerwünschte Glyphen angezeigt werden. Und natürlich macht es das Deklarieren einer Codierung und das Verwenden von Zeichen aus einer anderen, ohne sie auf einer Webseite richtig zu deklarieren / zu referenzieren, für Browser schwierig, sie korrekt zu rendern, und für Suchmaschinen, sie angemessen zu indizieren.
Für Ihre eigenen Dokumente, Manuskripte usw. können Sie alles verwenden, was Sie benötigen, um die Arbeit zu erledigen. Was das Web angeht, scheinen die meisten Leute der Verwendung einer UTF-8-Version zuzustimmen, die kein Byte-Bestellzeichen verwendet, aber das ist nicht ganz einstimmig. Wie Sie sehen können, hat jede Zeichenkodierung ihre eigene Verwendung, ihren eigenen Kontext sowie ihre eigenen Stärken und Schwächen. Als Endbenutzer müssen Sie sich wahrscheinlich nicht darum kümmern, aber jetzt können Sie den zusätzlichen Schritt nach vorne machen, wenn Sie dies wünschen.







