ASCII, UTF-8, ISO-8859… Olet ehkä nähnyt näiden outojen monikertojen kelluvan, mutta mitä ne oikeastaan tarkoittavat? Lue, kun selitämme merkkien koodausta ja miten nämä lyhenteet liittyvät näytöllä näkyvään pelkkään tekstiin.
Peruselementit
Kun puhumme kirjoitetusta kielestä, puhumme siitä, että kirjaimet ovat sanojen rakennuspalikoita, jotka sitten rakentavat lauseita, kappaleita ja niin edelleen. Kirjaimet ovat symboleja, jotka edustavat ääniä. Kun puhut kielestä, puhut ääniryhmistä, jotka muodostavat yhdessä jonkinlaisen merkityksen. Jokaisella kielijärjestelmällä on monimutkainen joukko sääntöjä ja määritelmiä, jotka hallitsevat näitä merkityksiä. Jos sinulla on sana, se on hyödytön, ellet tiedä, mistä kielestä se tulee, ja käytät sitä muiden sitä kieltä puhuvien kanssa.
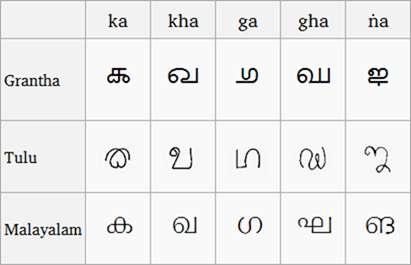
(Vertailu Granthan, Tulun ja Malajalamin käsikirjoituksista, Kuva Wikipedia )
Tietokoneiden maailmassa käytämme termiä "merkki". Hahmo on eräänlainen abstrakti käsite, jonka määrittelevät tietyt parametrit, mutta se on merkityksen perusyksikkö. Latinalainen A-kirjain ei ole sama kuin kreikan alfa tai arabialainen alif, koska niillä on erilainen konteksti - ne ovat eri kieliltä ja niillä on hieman erilaiset ääntämiset - joten voimme sanoa, että ne ovat erilaisia merkkejä. Hahmon visuaalista esitystä kutsutaan "kuvaksi" ja erilaisia kuvioryhmiä kutsutaan fonteiksi. Merkkiryhmät kuuluvat "sarjaan" tai "ohjelmistoon".
Kun kirjoitat kappaleen ja vaihdat kirjasinta, et muuta kirjainten foneettisia arvoja, vaan niiden ulkoasua. Se on vain kosmeettista (mutta ei merkityksetöntä!). Joillakin kielillä, kuten muinaisella egyptiläisellä ja kiinalla, on ideogrammit; nämä edustavat kokonaisia ideoita äänien sijaan, ja niiden ääntämiset voivat vaihdella ajan ja etäisyyden mukaan. Jos korvaat yhden merkin toisella, korvataan idea. Se on muutakin kuin vain kirjainten muuttaminen, ideogrammin muuttaminen.
Merkkien koodaus

(Kuva Wikipedia )
Kun kirjoitat jotain näppäimistöön tai lataat tiedoston, mistä tietokone tietää mitä näytetään? Tähän merkkikoodaus on tarkoitettu. Tietokoneesi teksti ei itse asiassa ole kirjaimia, vaan sarja pareitettuja aakkosnumeerisia arvoja. Merkkikoodaus toimii avaimena, jonka arvot vastaavat mitä merkkejä, aivan kuten ortografia sanelee, mitkä äänet vastaavat mitä kirjaimia. Morse-koodi on eräänlainen merkkikoodaus. Siinä selitetään, kuinka pitkät ja lyhyet yksiköt, kuten äänimerkit, edustavat merkkejä. Morse-koodissa merkit ovat vain englanninkielisiä kirjaimia, numeroita ja pisteitä. On olemassa monia tietokonemerkkikoodauksia, jotka kääntyvät kirjaimiksi, numeroiksi, korostusmerkeiksi, välimerkkeiksi, kansainvälisiksi symboleiksi ja niin edelleen.
Usein tästä aiheesta käytetään myös termiä "koodisivut". Ne ovat lähinnä tiettyjen yritysten käyttämiä merkkikoodauksia, usein pienin muutoksin. Esimerkiksi Windows 1252 -koodisivu (aiemmin tunnettu nimellä ANSI 1252) on ISO-8859-1: n muokattu muoto. Niitä käytetään enimmäkseen sisäisenä järjestelmänä viittaamaan vakio- ja muokattuihin merkkikoodauksiin, jotka ovat ominaisia samoille järjestelmille. Varhaisessa vaiheessa merkkien koodaus ei ollut niin tärkeää, koska tietokoneet eivät olleet yhteydessä toisiinsa. Internetin noustessa esiin ja verkostoituminen on yleistä, ja siitä on tullut yhä tärkeämpi jokapäiväisessä elämässämme edes ymmärtämättä sitä.
Monia erilaisia
(Kuva sarah sosiak )
Siellä on paljon erilaisia merkkikoodauksia, ja siihen on paljon syitä. Minkä merkkikoodauksen valitset käyttöösi, riippuu tarpeistasi. Jos puhut venäjän kielellä, on järkevää käyttää merkkikoodausta, joka tukee hyvin kyrillistä. Jos puhut koreaksi, haluat jotain, joka edustaa hyvin Hangulia ja Hanjaa. Jos olet matemaatikko, haluat jotain, jossa kaikki tieteelliset ja matemaattiset symbolit sekä kreikkalaiset ja latinalaiset kuviot ovat hyvin edustettuina. Jos olet kepponen, saatat hyötyä siitä ylösalaisin teksti . Ja jos haluat, että kuka tahansa henkilö voi tarkastella kaikkia tämäntyyppisiä asiakirjoja, haluat melko tavallisen ja helposti saatavilla olevan koodauksen.
Katsotaanpa joitain yleisempiä.
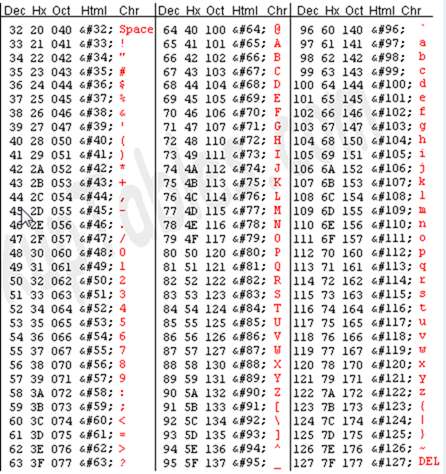
(Ote ASCII - taulukosta, kuva asciitable.com )
- ASCII - American Standard Code for Information Interchange on yksi vanhimmista merkkikoodauksista. Se kehitettiin alun perin lennätinkoodien perusteella ja kehittyi ajan myötä sisällyttämään enemmän symboleja ja joitain nyt vanhentuneita ei-tulostettuja ohjausmerkkejä. Se on luultavasti yhtä yksinkertainen kuin saat nykyaikaisissa järjestelmissä, koska se rajoittuu latinalaisiin aakkosiin ilman aksenttimerkkejä. Sen 7-bittinen koodaus sallii vain 128 merkkiä, minkä vuoksi ympäri maailmaa on käytössä useita epävirallisia variantteja.
- ISO-8859 - Kansainvälisen standardointijärjestön yleisimmin käytetty merkkikoodausten ryhmä on numero 8859. Jokainen erityinen koodaus on merkitty numerolla, jonka etuliitteenä on usein kuvaileva monikerta, esim. ISO-8859-3 (Latin-3), ISO-8859-6 (Latin / Arabia). Se on ASCII-sarja, mikä tarkoittaa, että koodauksen 128 ensimmäistä arvoa ovat samat kuin ASCII. Se on kuitenkin 8-bittinen ja sallii 256 merkkiä, joten se rakentaa sieltä ja sisältää paljon laajemman merkkivalikoiman, jossa jokainen erityinen koodaus keskittyy erilaisiin kriteereihin. Latin-1 sisälsi joukon korostettuja kirjaimia ja symboleja, mutta se korvattiin myöhemmin uudistetulla Latin-9 -sarjalla, joka sisältää päivitetyt kuviot, kuten Euro-symboli.
(Ote Tiibetin käsikirjoituksesta, Unicode v4, sivulta unicode.org )
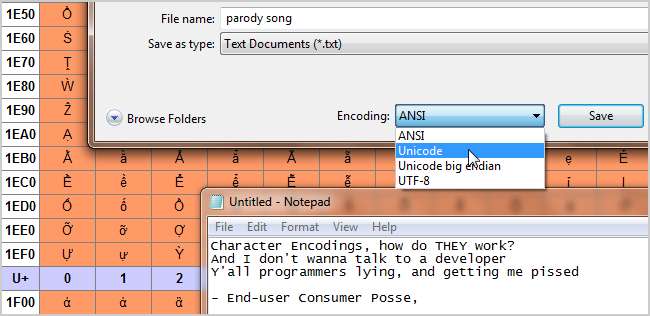
- Unicode - Tämän koodausstandardin tavoitteena on universaalisuus. Se sisältää tällä hetkellä 93 komentosarjaa, jotka on järjestetty useisiin lohkoihin, ja paljon enemmän töissä. Unicode toimii eri tavalla kuin muut merkistöjoukot siinä, että jokainen arvo ohjataan glyfin koodaamisen sijaan edelleen "koodipisteeseen". Nämä ovat heksadesimaaliarvoja, jotka vastaavat merkkejä, mutta ohjelmaa, kuten verkkoselaimesi, tarjoaa itse kuviot erillään. Nämä koodipisteet kuvataan yleisesti seuraavasti: U + 0040 (mikä tarkoittaa ‘@’ ). Erityiset koodaukset Unicode-standardin alla ovat UTF-8 ja UTF-16. UTF-8 yrittää sallia maksimaalisen yhteensopivuuden ASCII: n kanssa. Se on 8-bittinen, mutta sallii kaikki merkit korvausmekanismin ja useita arvopareja merkkiä kohden. UTF-16 ojittaa täydellisen ASCII-yhteensopivuuden täydellisempään 16-bittiseen yhteensopivuuteen standardin kanssa.
- ISO-10646 - Tämä ei ole varsinainen koodaus, vain ISO-standardoitu Unicode-merkistö. Se on enimmäkseen tärkeää, koska se on hahmoryhmä, jota HTML käyttää. Jotkut Unicoden tarjoamista kehittyneemmistä toiminnoista, jotka mahdollistavat lajittelun ja oikealta vasemmalle vasemmalta oikealle -koodauksen, puuttuvat. Silti se toimii erittäin hyvin Internetissä, koska se sallii useiden komentosarjojen käytön ja antaa selaimen tulkita kuviot. Tämä tekee lokalisoinnista hieman helpompaa.
Mitä koodausta minun pitäisi käyttää?
No, ASCII toimii useimmille englanninkielisille, mutta ei paljon muuta. Useammin näet ISO-8859-1: n, joka toimii useimmilla Länsi-Euroopan kielillä. Muut ISO-8859-versiot toimivat kyrillisillä, arabialaisilla, kreikkalaisilla tai muilla erityisillä skripteillä. Jos kuitenkin haluat näyttää useita komentosarjoja samassa asiakirjassa tai samalla verkkosivulla, UTF-8 mahdollistaa paljon paremman yhteensopivuuden. Se toimii myös hyvin ihmisille, jotka käyttävät oikeita välimerkkejä, matematiikkasymboleja tai mansetin ulkopuolisia merkkejä, kuten ruudut ja valintaruudut .

(Useita kieliä yhdessä asiakirjassa, kuvakaappaus gujaratsamachar.com )
Jokaisessa sarjassa on kuitenkin haittoja. ASCII: n välimerkkejä on rajoitettu, joten se ei toimi uskomattoman hyvin typografisesti oikeissa muokkauksissa. Oletko koskaan kirjoittanut kopioi / liitä vain Wordista, jotta sinulla on outo yhdistelmä kuvioita? Tämä on ISO-8859: n haittapuoli, tai tarkemmin sanottuna, sen oletettu yhteentoimivuus käyttöjärjestelmäkohtaisten koodisivujen kanssa (katsomme sinua, Microsoft!). UTF-8: n suurin haittapuoli on riittävän tuen puute sovellusten muokkauksessa ja julkaisemisessa. Toinen ongelma on, että selaimet eivät usein tulkitse UTF-8-koodatun merkin tavujärjestysmerkkiä. Tämän seurauksena ei-toivotut kuviot näytetään. Ja tietysti yhden koodauksen ilmoittaminen ja toisen merkkien käyttö ilmoittamatta tai viittaamatta niihin oikein verkkosivulla vaikeuttaa selainten renderointia ja hakukoneiden indeksoinnin asianmukaisesti.
Omissa asiakirjoissasi, käsikirjoituksissasi ja niin edelleen voit käyttää mitä tarvitset työn tekemiseen. Verkosta huolimatta näyttää siltä, että useimmat ihmiset sopivat käyttävänsä UTF-8-versiota, joka ei käytä tavujärjestysmerkkiä, mutta se ei ole täysin yksimielistä. Kuten näette, jokaisella merkkikoodauksella on oma käyttö, konteksti sekä vahvuudet ja heikkoudet. Loppukäyttäjänä sinun ei todennäköisesti tarvitse käsitellä tätä, mutta nyt voit ottaa ylimääräisen askeleen eteenpäin, jos niin haluat.







