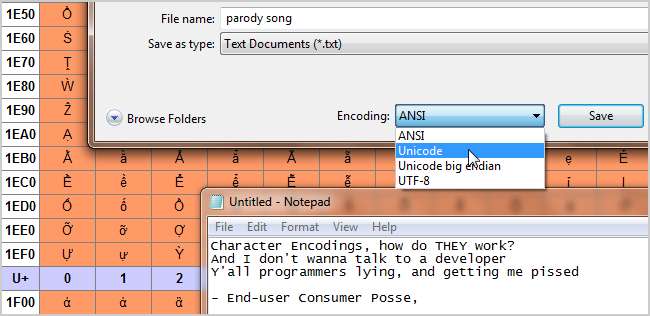
ASCII, UTF-8, ISO-8859… Anda mungkin pernah melihat moniker aneh ini beredar, tapi apa sebenarnya artinya? Baca terus selagi kami menjelaskan apa itu pengkodean karakter dan bagaimana akronim ini berhubungan dengan teks biasa yang kita lihat di layar.
Blok Bangunan Fundamental
Ketika kita berbicara tentang bahasa tertulis, kita berbicara tentang huruf sebagai bahan penyusun kata, yang kemudian membangun kalimat, paragraf, dan seterusnya. Huruf adalah simbol yang merepresentasikan suara. Saat Anda berbicara tentang bahasa, Anda berbicara tentang kelompok suara yang bersatu untuk membentuk suatu makna. Setiap sistem bahasa memiliki seperangkat aturan dan definisi kompleks yang mengatur makna tersebut. Jika Anda memiliki sebuah kata, itu tidak berguna kecuali Anda tahu dari bahasa apa dan Anda menggunakannya dengan orang lain yang berbicara bahasa itu.
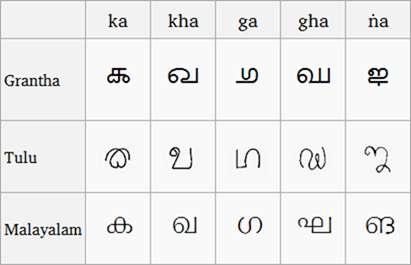
(Perbandingan skrip Grantha, Tulu, dan Malayalam, Gambar dari Wikipedia )
Dalam dunia komputer, kami menggunakan istilah "karakter". Karakter adalah semacam konsep abstrak, yang ditentukan oleh parameter tertentu, tetapi itu adalah unit makna fundamental. Bahasa Latin 'A' tidak sama dengan bahasa Yunani 'alpha' atau bahasa Arab 'alif' karena memiliki konteks yang berbeda - berasal dari bahasa yang berbeda dan pengucapan yang sedikit berbeda - jadi kita dapat mengatakan bahwa keduanya adalah karakter yang berbeda. Representasi visual dari karakter disebut "mesin terbang" dan kumpulan mesin terbang yang berbeda disebut font. Kelompok karakter termasuk dalam "set" atau "repertoar".
Saat Anda mengetik paragraf dan Anda mengubah fonta, Anda tidak mengubah nilai fonetik dari huruf-huruf tersebut, Anda mengubah tampilannya. Itu hanya kosmetik (tapi bukan tidak penting!). Beberapa bahasa, seperti bahasa Mesir dan Cina kuno, memiliki ideogram; ini mewakili keseluruhan ide, bukan suara, dan pengucapannya dapat bervariasi dari waktu ke waktu dan jarak. Jika Anda mengganti satu karakter dengan karakter lainnya, Anda mengganti ide. Ini lebih dari sekedar mengubah huruf, itu mengubah ideogram.
Pengkodean Karakter

(Gambar dari Wikipedia )
Saat Anda mengetik sesuatu di keyboard, atau memuat file, bagaimana komputer tahu apa yang harus ditampilkan? Untuk itulah pengkodean karakter. Teks di komputer Anda sebenarnya bukan huruf, ini adalah rangkaian nilai alfanumerik yang dipasangkan. Pengkodean karakter bertindak sebagai kunci yang nilainya sesuai dengan karakter mana, seperti bagaimana ortografi menentukan suara mana yang sesuai dengan huruf mana. Kode morse adalah semacam pengkodean karakter. Ini menjelaskan bagaimana kelompok unit panjang dan pendek seperti bip mewakili karakter. Dalam kode Morse, karakternya hanya huruf bahasa Inggris, angka, dan titik. Ada banyak pengkodean karakter komputer yang diterjemahkan ke dalam huruf, angka, tanda aksen, tanda baca, simbol internasional, dan sebagainya.
Seringkali pada topik ini, istilah "halaman kode" juga digunakan. Mereka pada dasarnya adalah pengkodean karakter seperti yang digunakan oleh perusahaan tertentu, seringkali dengan sedikit modifikasi. Misalnya, halaman kode Windows 1252 (sebelumnya dikenal sebagai ANSI 1252) adalah bentuk modifikasi dari ISO-8859-1. Mereka sebagian besar digunakan sebagai sistem internal untuk merujuk pada pengkodean karakter standar dan dimodifikasi yang khusus untuk sistem yang sama. Awalnya, pengkodean karakter tidak begitu penting karena komputer tidak berkomunikasi satu sama lain. Dengan meningkatnya popularitas internet dan jaringan menjadi hal yang umum, hal itu telah menjadi semakin penting dalam kehidupan kita sehari-hari tanpa kita sadari.
Berbagai Jenis
(Gambar dari sarah sosiak )
Ada banyak pengkodean karakter berbeda di luar sana, dan ada banyak alasan untuk itu. Pengkodean karakter mana yang Anda pilih untuk digunakan bergantung pada kebutuhan Anda. Jika Anda berkomunikasi dalam bahasa Rusia, masuk akal untuk menggunakan pengkodean karakter yang mendukung Cyrillic dengan baik. Jika Anda berkomunikasi dalam bahasa Korea, Anda pasti menginginkan sesuatu yang mewakili Hangul dan Hanja dengan baik. Jika Anda seorang ahli matematika, maka Anda menginginkan sesuatu yang memiliki semua simbol ilmiah dan matematika terwakili dengan baik, serta mesin terbang Yunani dan Latin. Jika Anda orang iseng, mungkin Anda akan mendapat manfaat darinya teks terbalik . Dan, jika Anda ingin semua jenis dokumen tersebut dilihat oleh orang tertentu, Anda menginginkan encoding yang cukup umum dan mudah diakses.
Mari kita lihat beberapa yang lebih umum.
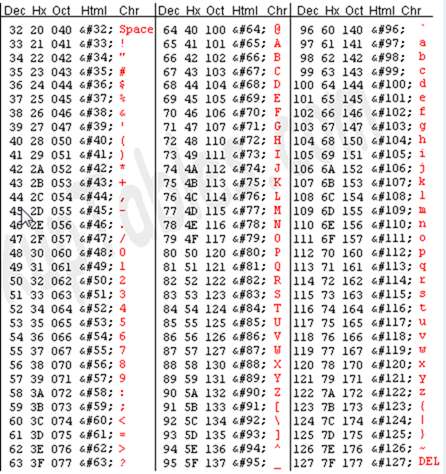
(Kutipan tabel ASCII, Gambar dari asciitable.com )
- ASCII - Kode Standar Amerika untuk Pertukaran Informasi adalah salah satu pengkodean karakter lama. Ini pada awalnya dirancang berdasarkan kode telegraf dan berkembang dari waktu ke waktu untuk memasukkan lebih banyak simbol dan beberapa karakter kontrol non-cetak yang sekarang sudah ketinggalan zaman. Ini mungkin dasar yang bisa Anda dapatkan dalam hal sistem modern, karena terbatas pada alfabet Latin tanpa karakter beraksen. Pengkodean 7-bitnya hanya memungkinkan 128 karakter, itulah sebabnya ada beberapa varian tidak resmi yang digunakan di seluruh dunia.
- ISO-8859 - Grup pengkodean karakter yang paling banyak digunakan oleh Organisasi Internasional untuk Standardisasi adalah nomor 8859. Setiap pengkodean spesifik ditentukan oleh angka, sering kali diawali dengan moniker deskriptif, mis. ISO-8859-3 (Latin-3), ISO-8859-6 (Latin / Arab). Ini adalah superset dari ASCII, yang berarti 128 nilai pertama dalam enkode sama dengan ASCII. Ini 8-bit, bagaimanapun, dan memungkinkan untuk 256 karakter, jadi itu dibangun dari sana dan mencakup lebih banyak karakter, dengan masing-masing pengkodean spesifik berfokus pada serangkaian kriteria yang berbeda. Latin-1 menyertakan sekumpulan huruf dan simbol beraksen, tetapi kemudian diganti dengan set yang direvisi yang disebut Latin-9 yang menyertakan mesin terbang yang diperbarui seperti simbol Euro.
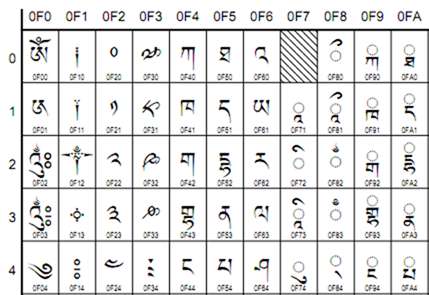
(Kutipan dari skrip Tibet, Unicode v4, dari unicode.org )
- Unicode - Standar pengkodean ini bertujuan untuk universalitas. Saat ini mencakup 93 skrip yang diatur dalam beberapa blok, dengan lebih banyak lagi yang sedang dikerjakan. Unicode bekerja secara berbeda dari kumpulan karakter lain dalam hal itu alih-alih mengkodekan langsung mesin terbang, setiap nilai diarahkan lebih jauh ke "titik kode". Ini adalah nilai heksadesimal yang sesuai dengan karakter tetapi mesin terbangnya sendiri disediakan secara terpisah oleh program, seperti browser web Anda. Poin kode ini biasanya digambarkan sebagai berikut: U + 0040 (yang diterjemahkan menjadi ‘@’ ). Pengodean khusus di bawah standar Unicode adalah UTF-8 dan UTF-16. UTF-8 mencoba untuk memungkinkan kompatibilitas maksimum dengan ASCII. Ini 8-bit, tetapi memungkinkan untuk semua karakter melalui mekanisme substitusi dan beberapa pasang nilai per karakter. UTF-16 membuang kompatibilitas ASCII yang sempurna untuk kompatibilitas 16-bit yang lebih lengkap dengan standar.
- ISO-10646 - Ini bukan pengkodean sebenarnya, hanya kumpulan karakter Unicode yang telah distandarisasi oleh ISO. Ini terutama penting karena itu adalah repertoar karakter yang digunakan oleh HTML. Beberapa fungsi lanjutan yang disediakan oleh Unicode yang memungkinkan pemeriksaan dan skrip kanan-ke-kiri di samping kiri-ke-kanan hilang. Namun, ini bekerja sangat baik untuk digunakan di internet karena memungkinkan untuk penggunaan berbagai macam skrip dan memungkinkan browser untuk menafsirkan mesin terbang. Ini membuat pelokalan agak lebih mudah.
Pengkodean Apa yang Harus Saya Gunakan?
Ya, ASCII berfungsi untuk sebagian besar penutur bahasa Inggris, tetapi tidak untuk yang lainnya. Lebih sering Anda akan melihat ISO-8859-1, yang berfungsi untuk sebagian besar bahasa Eropa Barat. Versi lain dari ISO-8859 berfungsi untuk skrip Sirilik, Arab, Yunani, atau skrip khusus lainnya. Namun, jika Anda ingin menampilkan beberapa skrip dalam dokumen yang sama atau pada halaman web yang sama, UTF-8 memungkinkan kompatibilitas yang jauh lebih baik. Ini juga berfungsi dengan sangat baik untuk orang yang menggunakan tanda baca yang tepat, simbol matematika, atau karakter yang tidak biasa, seperti kotak dan kotak centang .

(Beberapa bahasa dalam satu dokumen, Screenshot dari gujaratsamachar.com )
Namun, ada kekurangan untuk setiap set. ASCII memiliki tanda baca yang terbatas, jadi ASCII tidak bekerja dengan sangat baik untuk pengeditan yang benar secara tipografis. Pernah mengetik salin / tempel dari Word hanya untuk memiliki beberapa kombinasi mesin terbang yang aneh? Itulah kekurangan ISO-8859, atau lebih tepatnya, interoperabilitasnya yang seharusnya dengan halaman kode khusus OS (kami melihat ANDA, Microsoft!). Kelemahan utama UTF-8 adalah kurangnya dukungan yang tepat dalam mengedit dan menerbitkan aplikasi. Masalah lainnya adalah browser sering tidak menafsirkan dan hanya menampilkan tanda urutan byte dari karakter berenkode UTF-8. Ini menghasilkan mesin terbang yang tidak diinginkan ditampilkan. Dan tentu saja, mendeklarasikan satu encoding dan menggunakan karakter dari yang lain tanpa mendeklarasikan / mereferensikannya dengan benar di halaman web menyulitkan browser untuk merendernya dengan benar dan mesin telusur mengindeksnya dengan tepat.
Untuk dokumen Anda sendiri, manuskrip, dan sebagainya, Anda dapat menggunakan apa pun yang Anda butuhkan untuk menyelesaikan pekerjaan. Sejauh web berjalan, tampaknya sebagian besar orang setuju untuk menggunakan versi UTF-8 yang tidak menggunakan tanda urutan byte, tetapi itu tidak sepenuhnya bulat. Seperti yang Anda lihat, setiap pengkodean karakter memiliki kegunaan, konteks, serta kekuatan dan kelemahannya sendiri. Sebagai pengguna akhir, Anda mungkin tidak perlu berurusan dengan ini, tetapi sekarang Anda dapat mengambil langkah ekstra jika mau.






