Przewodnik po wizycie w chmurze Google

Nauczanie maszynowe. Głęboka nauka. Przetwarzanie języka naturalnego. Wizja komputerowa. Automatyzacja. Rozpoznawanie głosu. Prawdopodobnie słyszałeś wszystkie te i wiele innych terminów, wszystkie pod parasolem sztucznej inteligencji. W rzeczywistości, pole rośnie tak szybko, staje się coraz trudniejsze do odbicia ostatecznej definicji. AI staje się częścią prawie każdego aspektu naszego życia Witryny e-commerce. i wyszukiwarki, aby odblokować telefon.
Twoje strony internetowe i aplikacje mogą wykorzystać API, aby dotknąć bezpośrednio do mocy AI. Bez konieczności bycia "pociągiem" agentami AI, możesz skorzystać z ogromnych ilości danych już analizowanych. Google, Amazon, IBM i wielu innych stworzyli punkty końcowe dla programistów do podłączenia i zaczynają się od razu za pomocą AI.
Na przednim końcu można połączyć polecenia głosowe, interfejsy chatbot lub reaktywne kreatywne elementy Webgl. Na tylnym końcu bazy danych używają inteligentnych algorytmów, aby zmaksymalizować szybkość i analizę. API mogą zapewnić warstwę abstrakcji z szerokiej gamy funkcji AI, od przewidywania do szkolenia zbiorowego.
Pamiętaj, jeśli robisz swoją witrynę bardziej złożoną, jest ważne, oceniasz swój wybór hosting usługa, aby upewnić się, że obsługuje go. Dokonywanie witryny od podstaw? Rozważyć uproszczenie procesu z góry Kreator strony internetowej . A jeśli tworzysz nowy System projektowania , ważne jest, aby zachować go bezpieczne i dostępne w przyzwoitym magazyn w chmurze .
- Przewodnik po narzędziach internetowych Google
Czym jest wizja komputera?
Wizja komputera to badanie i tworzenie sztucznych systemów, które wyodrębniają informacje z obrazów. Może również obejmować mechaniczny system samej wizji. Pod względem rozpoznawania jest to proces analizy i określenia treści obrazu lub serii obrazów (w tym wideo). Może to obejmować skany medyczne, zdjęcia, wideo 360-stopniowe i praktycznie wszelkiego rodzaju obrazy, które można sobie wyobrazić.
Ai-zasilany wizja komputerowa może:
- Zidentyfikuj, etykiety i kategoryzuj treści
- Wykryj twarze i emocje
- Rozpoznawaj nakrycia głowy, takie jak okulary i kapelusze
- Zidentyfikuj punkty orientacyjne, budynki i struktury
- Oceń informacje o poziomie pikseli, takie jak dane kolorowe, jakość i rozdzielczość
- Rozpoznaj popularne logo.
- Zidentyfikuj i przeczytaj tekst
- Określ potencjalnie nieodpowiednie obrazy
Wizja komputerowa z interfejsem Vision Vision Google
Istnieje wiele wyborów dla API Vision, ale będziemy korzystać z API w Cloud Vision Google. Google gospodarze wielu AI API, w tym przetwarzanie języka naturalnego, rozpoznawanie głosu, głębokie uczenie się i wizję.
API Cloud Vision umożliwia witryny i aplikacje, aby zrozumieć, co jest na obrazie. Klasyfikuje treść na kategorie, etykietowanie wszystko, co widzi. Zapewnia również wynik zaufania, więc wiesz, jak prawdopodobne jest, że to, co uważa, że jest w obrazie faktycznie pojawia się. Możesz użyć tego do interakcji inteligentnie dotyczące wejścia kamery w aplikacjach AR lub Video. Możesz tworzyć narzędzia, aby pomóc tym, którzy są niedowidzącym. Możesz tworzyć asystentów, aby pomóc w identyfikacji budynków lub zabytków dla turystów. Możliwości są nieskończone.
01. Ustaw projekt Cloud
Jeśli wcześniej użyłeś API Google, niektóre z tych pierwszych kroków będą znane. Podobnie jak w przypadku innych usług Google, musisz skonfigurować projekt Cloud. Idź do Konsola Platformy Google Cloud i utwórz nowy projekt lub wybierz istniejący. Podobnie jak większość usług Google, API Cloud Vision jest bezpłatny, dopóki nie zaczniesz robić wielu próśb API. Może być konieczne wprowadzenie informacji o rozliczaniu, gdy aktywujesz API, ale nie jest to obciążone przy niskim wolumecie żądań i można usunąć usługi po zakończeniu testów.
02. Włącz interfejs API w chmurze
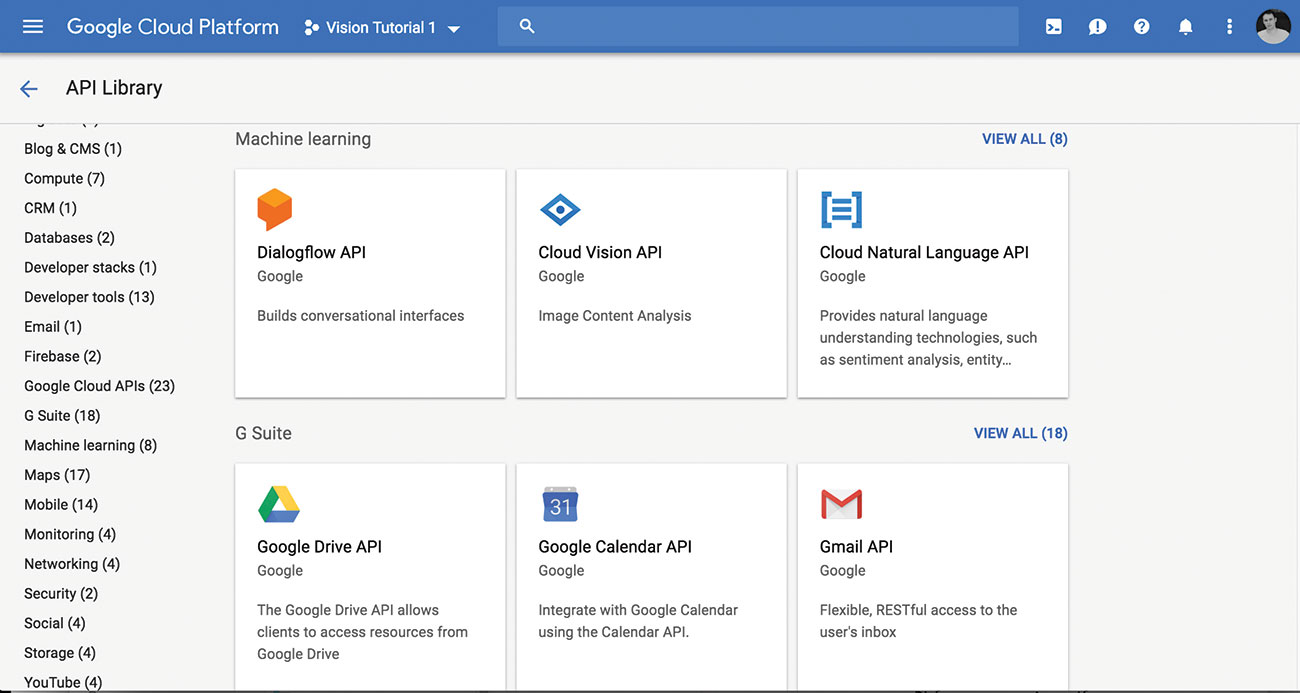
Przeglądaj Biblioteka API. i wybierz API Cloud Vision dla swojego projektu.
Po włączeniu powinieneś zobaczyć trochę zielonego czeku, a komunikat "API włączony" obok niego.
03. Utwórz konto serwisowe
Następnie musisz skonfigurować Konto serwisowe . Pomyśl o API jako tworzonej usługi internetowej. Ponieważ zamierzamy ustawić użycie jak typowa usługa, jest to najlepsza praktyka. Działa również najlepiej z przepływem uwierzytelniania.
04. Pobierz klucz prywatny
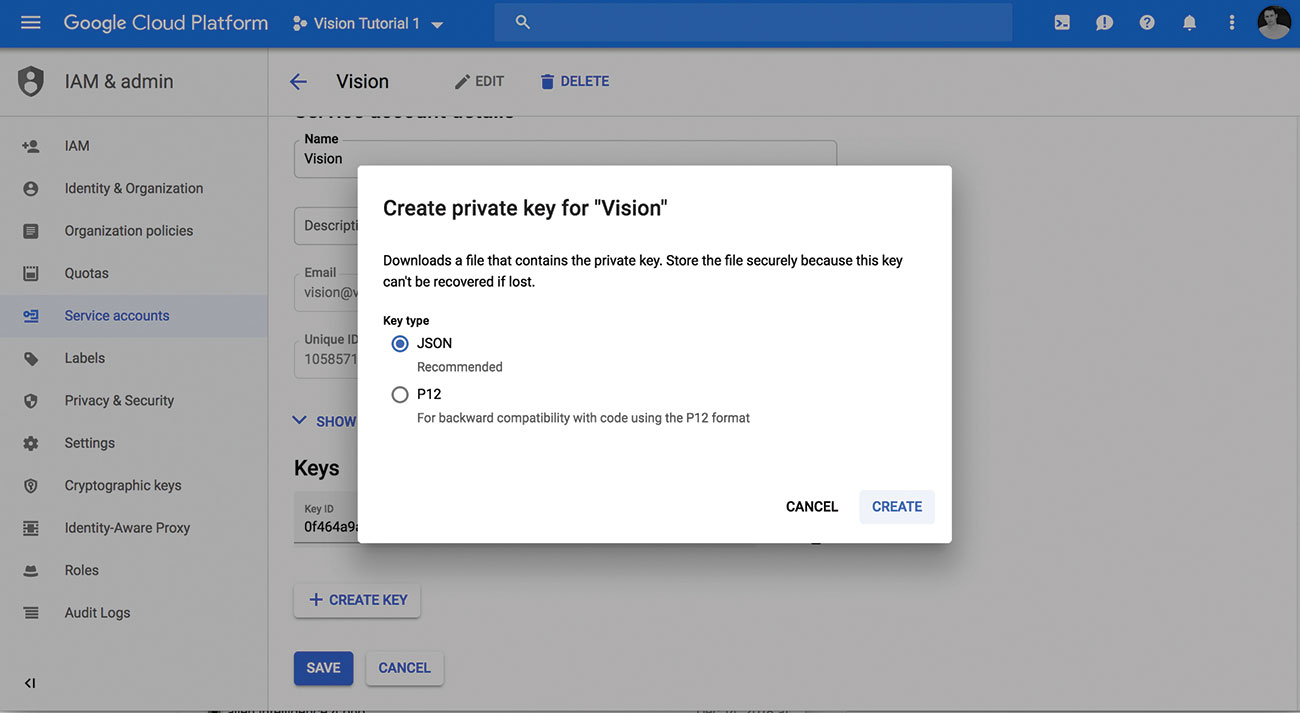
Po otrzymaniu projektu z włączonym API i kontem serwisowym możesz pobrać swój klucz prywatny jako plik JSON. Zwróć uwagę na lokalizację pliku, dzięki czemu można go użyć w następnych krokach.
Jeśli masz jakieś problemy z pierwszymi kilkoma krokami Szybki przewodnik to pomaga i kończy się pobraniem klucza JSON.
05. Ustaw zmienną środowiskową
Musisz ustawić Google_application_credentials. Zmienna środowiskowa, więc można uzyskać dostęp do naszych połączeń API. Wskazuje to do pliku JSON, który właśnie pobrałeś i zapisujesz, musisz wpisać ścieżkę za każdym razem. Otwórz nowe okno terminala i użyj eksport Jak więc:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/[username]/Downloads/[file name].json"Zastąpić [Nazwa Użytkownika] z twoją nazwą użytkownika. Upewnij się, że ścieżka do miejsca, do którego zapisany plik kluczy jest poprawny. Zastąpić [Nazwa pliku] Z plikiem klucza prywatnego i użyj ścieżki do swojego pliku.
W systemie Windows możesz zrobić to samo za pośrednictwem linii poleceń, tak jak:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\[username]\Downloads\[FILE_NAME].json"Uwaga: Jeśli zamkniesz okno terminalu lub konsoli, możesz ponownie uruchomić ponownie, aby ponownie ustawić zmienną. Wkrótce dodamy to do naszego kodu PHP, więc nie musisz się o tym martwić.
06. Zadzwoń do API
Teraz jesteś gotowy na kopanie w API Vision Cloud. Użyjesz Curl do wykonania szybkich testów API. Możesz także użyć tej metody z kodu.
Wnioski Curl można wykonać w większości języków, czy to PHP, Python czy węzeł. W ten sposób możesz dokonać połączeń bezpośrednich w wierszu poleceń lub przypisać wynik do zmiennej w wybranym języku. Znajdź szybkie wskazówki dotyczące korzystania z Curl tutaj .
Utwórz prosty plik JSON, aby utrzymać szczegóły żądania. Nazwać Google_vision.json. . Przechowuj go lokalnie, gdzie chcesz uruchomić polecenia terminala.
{
"upraszanie":[
{
"wizerunek":{
"źródło":{
"Imageuri":
"https://upload.wikimedia.org/wikipedia/commons/9/93/Golden_retriever_Carlos_%281058191055%29.jpg"
}
},
"funkcje": [{
"Wpisz": "Type_unspecified",
"Maxresults": 50
},
{
"Wpisz": "Landmark_detection",
"Maxresults": 50
},
{
"Wpisz": "Face_detection",
"Maxresults": 50
}
{
"Wpisz": "Label_detection",
"Maxresults": 50
},
{
"Wpisz": "Text_detection",
"Maxresults": 50
},
{
"Wpisz": "Safe_search_detekcja",
"Maxresults": 50
},
{
"Wpisz": "Image_properties",
"Maxresults": 50
}
]
}
]
} W powyższym kodzie wskazałeś obraz do analizy, a także konkretne funkcje API do użycia, w tym wykrywanie twarzy i wykrywanie punktów orientacyjnych. Safe_search_detection. Jest świetny, że wiedząc, czy obraz jest bezpieczny i w jakiej kategorii należy do, takich jak treść dorosłych lub gwałtowna. Image_properties. Opowiada o kolorach i szczegółach poziomu pikseli.
Aby wykonać polecenie Curl, w terminalu lub interfejsie wiersza polecenia wprowadź następujące elementy.
Curl -X Post -H "Autoryzacja: Nośnik" $ (GCloud Authment-DEVITE-Access-token) -H "Typ treści: Aplikacja / JSON; Charset = UTF-8" --Data-binarny @ Google_vision.json "https://vision.googleapis.com/v1/images: antion Wyniki Używając & gt; Wyniki Składnia, otrzymasz wyniki przechowywane w nowym pliku o nazwie dla Ciebie. Wskazałeś adres URL do API ( "https://vision.googleapis.com/v1/images:" ) i zawiera dane JSON POCZTA do tego.
Możesz uzyskać monitę przy pierwszym użyciu tego, aby aktywować API lub zezwolić na dostęp. Odpowiedz tak lub y do tego monitu i powinien zwrócić JSON.
Jeśli otworzysz plik wyników, otrzymasz wyniki danych JSON z żądania widzenia API. Oto fragment:
{
"Odpowiedzi": [
{
"Labelannotations": [
{
"Mid": "/ m / 0bt9lr",
"Opis": "Pies",
"Wynik": 0,982986,
"Miejscowość": 0,982986
},
{
"Mid": "/ m / 01t032",
"Opis": "Golden Retriever",
"Wynik": 0,952482,
"Topicity": 0,952482
},
{
... Od razu widzisz kilka przydatnych wyników. Pod etykietownie. Węzeł można zobaczyć 98-procentowego dopasowania, że obraz zawiera "psa" i dopasowanie 95 procent, które zawiera "Golden Retriever"! AI już zidentyfikował treść obrazu i innych szczegółów, w tym "pysk" i fakt, że jest prawdopodobnie "pies sportowy".
Nie wymaga to treningu ze swojej strony z powodu już wyszkolonego systemu AI Google Vision. Skanowanie przez wyniki, zobaczysz wszystko, od zalecanych regionów przycinania - dla obrazów automatycznych przycinania do tematów - do niesamowitego szczegółu, co jest w obrazach, w tym kolorach i treści. Wypróbuj go z innymi obrazami, aby zobaczyć, jak potężny jest API.
Możesz kontynuować korzystanie z tej metody, aby przetestować połączenia, których użyjemy. Możesz także skonfigurować lokalny SDK w języku preferujesz i zintegrować go w swojej aplikacji.
07. Zainstaluj bibliotekę klienta
Następnie zrobisz prostą aplikację internetową, aby pokazać, jak zintegrować API w swoich projektach.
Istnieje wiele dostępnych SDK w różnych językach, aby ułatwić integracja. Użyjesz PHP SDK do tej następnej sekcji. Jeśli chcesz dostosować kod, który podąża za innym językiem, jest świetny zasób SDK tutaj .
Zacznij od upewnienia się, że masz folder projektu skonfigurowany na lokalnym lub zdalnym serwerze. Jeśli nie masz już, zdobądź kompozytora i zainstaluj go do folderu projektu. Opcjonalnie możesz mieć kompozytor już zainstalowany na całym świecie i to też jest w porządku.
Uruchom następujące polecenie kompozytora, aby zainstalować pliki dostawcy dla SDK w Cloud Vision.
PHP -RR "Kopiuj (" https:///getcomposer.org/installer "," kompozytor-setup.php ");"
PHP -R "IF (Hash_file (" Sha384 "," kompozytor-setup.php ") === '93B54496392C0627746 70AC18B134C3B3A95E5A5E5C8
F1A9F115F203B75BF9A129D5DAA8BA6A13E2CC8A1DA080.
6388A8 ') {Echo' Installer Zweryfikowany "; } else {Echo 'installer Corrupt'; UNLINK ("kompozytor-setup.php"); } echo php_eol; "
PHP Composer-Setup.php
PHP -R "UNLINK (" kompozytor-setup.php ");"
PHP Composer.phar wymaga Google / Cloud-Vision Kompozytor tworzy folder dostawcy w folderze projektu i instaluje wszystkie zależności dla Ciebie. Jeśli utkniesz to ustawienie i chcesz użyć PHP, możesz to sprawdzić Instalowanie zasobów kompozytora. .
08. Utwórz nowy plik
Utwórz nowy plik PHP w folderze projektu. Ustaw go, jak chcesz, ale zawiera prosty formularz HTML, aby przesłać obrazy do szybkiego testowania. Oto przykładowy plik PHP z formą zawartą:
DocType HTML & GT;
& lt; html & gt;
& lt; Head & GT;
& LT; Nett & GT; Net - Tutorial Vision Computer & LT; / Title & GT;
& LT; / Head & GT;
& lt; body & gt;
& LT; Form Action = "index.php" Enctype = "Multipart / Form-Data" Metoda = "Post" & GT;
& lt; h1 & gt; wybierz obraz i lt; / h1 & gt;
& LT; Wpisz Wpisz = "Plik" Nazwa = "Plik" & GT; & LT; BR / & GT;
& lt; typ wejścia = "Prześlij" Value = "Prześlij obraz" Nazwa = "Prześlij" & GT; & lt; br / & gt;
& LT; / Form & GT;
& lt; div class = "wyniki" & gt;
& lt;? php
// kod PHP idzie tutaj //
Jeśli (! Isset ($ _ Post ["Prześlij"])) {Die (); }
?
& lt; / div & gt;
& lt; / body & gt;
& lt; / html & gt; Kod zawiera podstawowy plik HTML z formą i zastępczem dla kodu PHP. Kod rozpoczyna sprawdzanie istnienia obrazu, przesyłane z formularza. Jeśli jeszcze nie zostanie przesłany, nic nie robi.
09. Przechowuj obraz
Jeśli wolisz wskazać obrazy online lub w systemie, pomiń ten krok. Jeśli chcesz przetwarzać wybrane obrazy, dodaj ten kod, aby zapisać wybrany obraz.
// Zapisz obraz
$ Filepath = $ _files ["Plik"] ["Nazwa"];
Jeśli (Move_uploaded_file ($ _ pliki ["Plik"] ["TMP_NAME"], $ Filepath)) {
echo "& lt; P & GT; & lt; iMg src =". $ Filepath. "Style = 'Szerokość: 400px; Wysokość: Auto;' / & gt; & lt; ";
} else {
Echo "Błąd !!";
} 10. Dodaj zmienną środowiskową
Musisz ustawić Google_application_credentials. zmienna do uwierzytelnienia. W PHP używamy putenv. polecenie ustawić zmienną środowiskową. Dodaj ten kod następnie w swoim kodzie PHP:
Putenv ('Google_Application_Credentials = / Użytkownicy / RichardMattka / Downloads / Vision Tutorial 1-0F464A9A0F7B.json'); Wymień ścieżkę i nazwę pliku do pliku klucza JSON.
11. Dołącz bibliotekę
Dodaj bibliotekę i zainicjuj LanguageClient. klasa w swoim kodzie. Dodaj ten kod Dalej:
Wymagaj __dir__. "/vendor/autoload.php";
Użyj Google Cloud Vision V1 owoceanNotatorClient;
$ projectID = 'Vision-Tutorial-1';
$ imageannotator = Nowy imaganNotatorClientny ([
"rzutno" = & gt; $ PROCITID.
]); Zacznij od wymagania autolaku dostawcy. Jest to podobne w Pythonie lub węzła, gdy potrzebujesz swoich zależności. Importuj ImageannotatorClient. Następnie, aby skorzystać z klasy. Zdefiniuj swój rzutnik. . Jeśli nie jesteś pewien, co to jest, spójrz na konsolę projektu Google Cloud. Wreszcie, stwórz nowy ImageannotatorClient. Obiekt za pomocą projekcji i przypisz go do $ imageannotator. zmienna.
12. Analizuj zawartość obrazu
Rozpocznij przesyłanie obrazu do API do analizy. Wyświetlasz wynik jako JSON na ekran na teraz, ale w praktyce możesz ocenić wyniki i użyć ich jakikolwiek sposób, w jaki chcesz.
Dodaj następujące czynności, aby przesłać obraz do interfejsu API.
$ image = file_get_contents ($ filepath);
$ odpowiedź = $ imageannotator- & gt; labeldetection ($ image);
$ etykiety = $ odpowiedź- & gt; getlabelannotations ();
foreach ($ etykiety jako $ etykieta) {
echo "° C:" Wynik "i GT;";
$ Wynik = $ Label- & GT; GetDescription ();
echo $ wynik. "(". $ Label-& GT; GetScore (). ")";
echo "Przekłada to treść z przedłożonej formy do imageannotator. punkt końcowy i przechowuje wynik w $ odpowiedź. zmienna. Określa to label funkcja. Możesz także użyć wykrywanie twarzy , Logodetection. , textTetection. i wiele innych funkcji. Na pełną listę, Sprawdź tutaj .
Następnie iteruj na liście etykiet. Jest to tylko przykład, aby pokazać, jak go używać: możesz go przetworzyć i reagować na wyniki, których potrzebujesz.
13. Wykryj twarze

Kolejny szybki przykład tego, jak potężny interfejs API leży w wykrywanie twarzy funkcjonować. Spowoduje to zwrócenie danych emocji, a także informacje o lokalizacji, gdzie na obrazie są twarze. Wypróbuj ten kod, aby zobaczyć, jak to działa.
$ Odpowiedź = $ imageannotator- & gt; facitetection ($ image);
$ faces = $ response- i gt; getfaceannotations ();
$ linicoodName = ["nieznany", "very_unliky", "mało prawdopodobne",
"Możliwe", "prawdopodobne", "Very_likely"];
// var_dump ($ etykiety);
Foreach ($ Faces as $ Face) {
echo "° C:" Wynik "i GT;";
$ anger = $ face- & gt; getberlikelihood ();
Printf ("Gniew:% s". PHP_EOL, $ prawdopodobieństwa Nazwa [$ gniewu]);
$ joyte = $ face- & gt; getjoylikenia ();
Printf ("Joy:% s". PHP_EOL, $ prawdopodobieństwa Nazwa [$ Joy]);
$ Vertices = $ Face- & GT; Getboundingpoly () - & GT; Getvertices ();
$ bands = [];
foreach ($ wierzchołków jako Vertex) {
$ bands [] = sprintf ('(% d,% d) ", $ VERTEX- & GT; Getx (), VertEx- & GT; Gety ());
}
Drukuj ("granice:". Dołącz (",", $ granice). PHP_EOL);
echo "Zaczynasz używać wykrywanie twarzy Funkcja adnotatora i przejść na obrazku jak poprzedni przykład. Potem dostajesz faceannotiatons. . Używasz szeregu wag odpowiedzi w bardziej wspólnym języku, dzięki czemu można zobaczyć prawdopodobieństwo pewnych emocji. Podążając za tym, tworzysz odpowiedź jak wcześniej. Sprawdzasz dwa z kilku możliwych emocji, gniewu i radości, zwracając wyniki tych. Daje to również rogi skrzynek ograniczonych, które definiują każdą znalezioną twarz.
Ten artykuł został pierwotnie publikowany w wydaniu 316 netto , Najlepiej sprzedający się magazyn na świecie dla projektantów stron internetowych i programistów. Kup problem 316 tutaj lub Subskrybuj tutaj .
Powiązane artykuły:
- Niesamowite narzędzie AI rekonstruuje zdjęcia jak magia
- 17 najlepszych narzędzi w Google Analytics
- Najlepsi redaktorzy kodu
Jak - Najpopularniejsze artykuły

Jak narysować konia
Jak Feb 9, 2026Strona 1 z 2: Jak narysować konia: krok po kroku Jak narysować konia: k..

Utwórz ilustrowane portrety ze zdjęć
Jak Feb 9, 2026Studiowałem sztukę piękną i Techniki malowania I przez długi czas był całkowicie przeciwko pomysłem cyfrow..

Jak poruszać się między DAZ Studio a Zbrush
Jak Feb 9, 2026Dla przybronników do Zbrush. , Interfejs wydaje się bardzo różny od innych programów modelowania 3D, więc mo..

Wszystko, co musisz wiedzieć o nowym węzła.js 8
Jak Feb 9, 2026Najnowsze ważne wydanie węzła Tutaj aktualizujemy Cię na te funkcje i pozostałe najważniejsze aspekty tego wydania. ..

Create a digital Etch A Sketch
Jak Feb 9, 2026W tym samouczku bierzemy mechaniczną zabawkę do rysowania, jako inspirację i próbujemy wdrożyć te funkcje dla nowoczesnych ..

Jak tworzyć realistyczną tkaninę CG
Jak Feb 9, 2026Podczas pracy z tkaniną i tkaninami w 3d, może być trudno osiągnąć zarówno dobrą rozdzielczość, jak i świetny wygląd...

Najlepsze wskazówki dotyczące udoskonalania technik ilustracji rysowane ręcznie
Jak Feb 9, 2026Robiłem Sztuka ołówka Od mojego dzieciństwa, kiedy nosiłbym ołówek i papier dookoła ze mną. Kolorowanie i..

Jak wykonać elastyczną platformę wstążki
Jak Feb 9, 2026Ratowanie wstążki są dość powszechne 3d art. W dzisiejszych czasach produkcyjne. Mają podobne zachowanie do ..
Kategorie
- AI I Uczenie Maszynowe
- AirPods
- Amazonka
- Amazon Alexa I Amazon Echo
- Amazon Alexa I Amazon Echo
- Amazon Ogień TV
- Amazon Prime Film
- Androida
- Komórkowe I Tabletki Androida
- Telefony I Tablety Z Androidem
- Android TV
- Jabłko
- Apple App Store
- Jabłko HomeKit I Jabłko HomePod
- Jabłko Muzyki
- Apple TV
- Apple Obserwować
- Aplikacje I Aplikacji Sieci
- Aplikacje I Aplikacje Internetowe
- Audio
- Chromebook I Chrom OS
- Chromebook & Chrome OS
- Chromecastowi
- Chmura Internetowa I
- Chmura I Internet
- Chmura I Internet
- Sprzęt Komputerowy
- Historia Computer
- Przewód Skrawania I Na żywo
- Cięcie I Strumieniowanie Sznurków
- Niezgoda
- Disney +
- DIY
- Pojazdy Elektryczne
- EReaders
- Niezbędniki
- Wyjaśniacze
- Facebooku
- Hazard
- Ogólnie
- Gmail
- Wykryliśmy
- Google Assistant & Google Nest
- Google Assistant I Google Nest
- Wykryliśmy Chrom
- Wykryliśmy Dokumenty
- Dysk Google
- Mapy Google
- Sklep Google Play
- Arkusze Google
- Wykryliśmy Szkiełka
- Google TV
- Sprzęt Komputerowy
- HBO Max
- Jak
- Hulu
- , Internet Slang I Skróty
- IPhone I IPAD
- Kindle
- Dystrybucja
- Mac
- Konserwacja I Optymalizacja
- Microsoft Edge
- Microsoft Excel
- Microsoft Office
- Microsoft Outlook
- Microsoft PDF
- Microsoft Zespoły
- Microsoft Word
- Mozilla Firefox
- I Straty
- Przełącznik Nintendo
- Paramount +
- PC Gaming
- Peacock I
- Fotografie
- Photoshop
- PlayStation
- Bezpieczeństwo I Bezpieczeństwo
- Prywatność I Bezpieczeństwo
- Prywatność I Ochrona
- Łapanki Produkcie
- Programowanie
- Maliny Pi
- Roku
- Safari
- Samsung Komórkowe I Tabletki
- Telefony I Tabletki Samsung
- Luzu
- Inteligentne Domu
- Snapchat
- Social Media
- Przestrzeń
- Spotify
- Krzesiwo
- Rozwiązywanie Problemów
- Telewizja
- Twittera
- Gry Wideo
- Wirtualna Rzeczywistość
- VPN
- Przeglądarki Internetowe
- Fi I Routery
- Wi -Fi I Routery
- Okna
- Okna 10
- Okna 11
- Okna 7
- Xbox
- YouTube I YouTube TV
- YouTube I YouTube TV
- Powiększenie
- Explainers