GoogleのCloud Visionのガイド

機械学習深い学習。自然言語処理。コンピュータビジョン。オートメーション。音声認識。あなたはおそらく、最近、これらすべてのものと他の多くの用語を最近、人工知能の傘下に聞いた。実際、フィールドは急速に成長していますが、最終的な定義を釘付けにするのがますます困難になりつつあります。 AIは私たちの生活のほぼあらゆる面の一部になりつつある eコマースWebサイト エンジンを検索して携帯電話のロックを解除します。
あなたのウェブサイトとアプリはAPIを活用してAIの電源に直接タップすることができます。 AIエージェントを訓練することなく、すでに分析された大量のデータを利用することができます。 Google、Amazon、IBM、そして他の多くの人々は、開発者がフックしてすぐにAIを使い始めるためのエンドポイントを作成しました。
フロントエンドでは、音声コマンド、Chatbotインターフェイス、またはReactive WebGL Creative要素を接続できます。バックエンドでは、データベースは速度と分析を最大化するためにインテリジェントなアルゴリズムを使用します。 APIは、予測から集合的なトレーニングへの幅広いAI機能からの抽象化の層を提供することができます。
あなたがあなたのサイトをより複雑にするならば、それはあなたの選択を評価することが重要です。 ウェブホスティング それがそれを処理できることを確認するためのサービス。スクラッチからサイトを作る?トップでプロセスを単純化することを検討してください ウェブサイトビルダー 。そしてあなたが新しいものを作っているなら デザインシステム 、それを安全に保つことが重要であり、まともな中でアクセス可能です クラウドストレージ 。
- GoogleのWebツールのガイド
コンピュータビジョンとは何ですか?
コンピュータビジョンは、画像から情報を抽出する人工システムの研究と作成です。それはまた視覚の機械的システム自体を包含することができる。認識の面では、画像または一連の画像(ビデオを含む)の内容を分析し決定するプロセスである。これには、医療スキャン、写真、360度ビデオ、そして実質的に想像できるイメージを含めることができます。
AI-Powered Computer Vision:
- コンテンツを識別、ラベルを付して分類します
- 面と感情を検出します
- メガネや帽子などのヘッドウェアを認識しています
- ランドマーク、建物、構造を特定します
- カラーデータ、品質、解像度などのピクセルレベルの情報を評価する
- 人気のロゴを認識しています
- テキストを識別して読む
- 潜在的に不適切な画像を特定する
GoogleのCloud Vision Apiとのコンピュータビジョン
Vision APIの選択肢がたくさんありますが、GoogleのCloud Vision APIを使用します。 Googleは、自然言語処理、音声認識、深部学習、ビジョンを含む多くのAI APIをホストしています。
Cloud Vision APIでは、サイトやアプリが画像内にあるものを理解することができます。それはコンテンツをカテゴリに分類し、それが見るものすべてのラベルを付けます。それはまた信頼性のスコアを提供します、それであなたはそれが実際にそこに現れることが実際に現れることがどのくらいの可能性があるか知っています。これを使用して、ARまたはビデオアプリのカメラ入力に関してインテリジェントに対話することができます。あなたは視覚的に損なわれている人々を支援するためのツールを作成することができました。あなたは観光客のための建物やランドマークを識別するのを助けるためのアシスタントを作成することができました。可能性は無限大。
01.クラウドプロジェクトを設定します
あなたが前にGoogleのAPIを使用した場合、これらの最初のステップのいくつかはおなじみになるでしょう。他のGoogleサービスと同様に、クラウドプロジェクトを設定する必要があります。に Google Cloudプラットフォームコンソール 新しいプロジェクトを作成するか、既存のプロジェクトを選択します。 Googleのほとんどのサービスと同様に、Cloud Vision APIは、たくさんのAPI要求を開始するまで無料で使用できます。 APIをアクティブにすると、請求情報を入力する必要があるかもしれませんが、これは少量の要求で請求されず、テストが完了した後にサービスを削除できます。
02. Cloud Vision Apiを有効にします
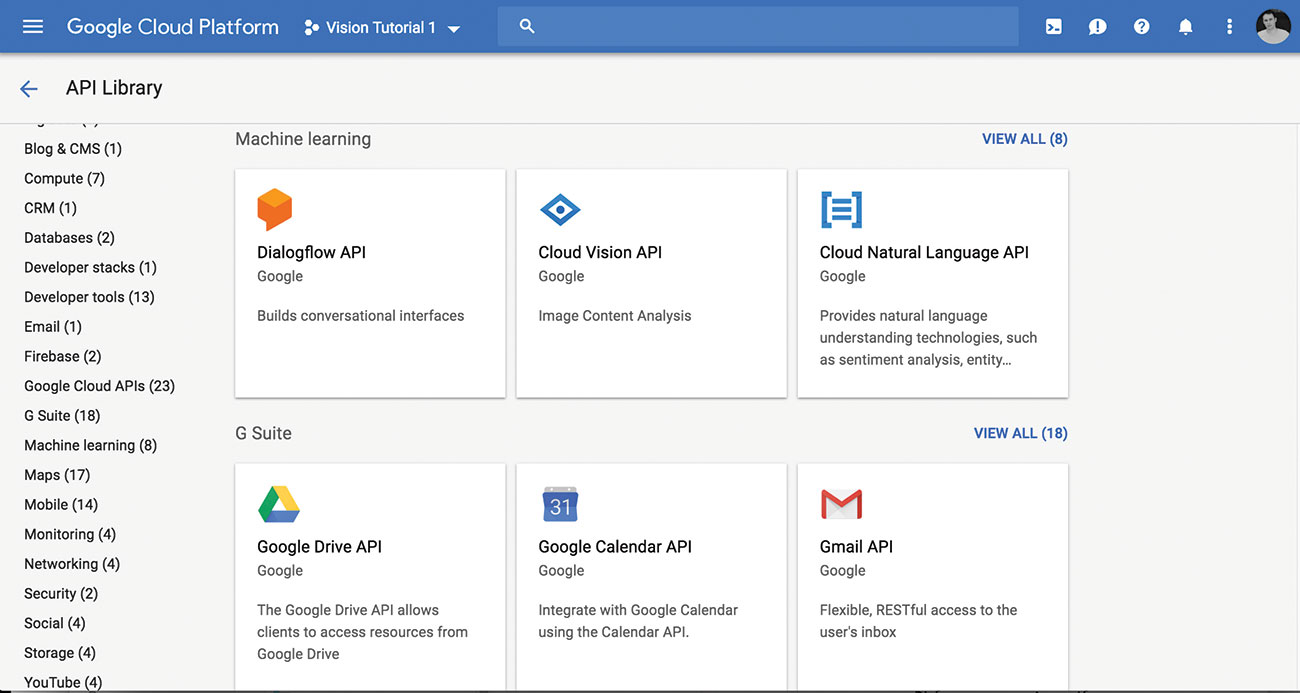
閲覧する APIライブラリ そしてプロジェクトのCloud Vision APIを選択してください。
一度有効になったら、少し緑色のチェックとその横に「APIが有効」というメッセージが表示されます。
03.サービスアカウントを作成します
次にAを設定する必要があります サービスアカウント 。あなたが作成しているWebサービスとしてAPIを考えてください。私たちは典型的なサービスのような使い方を設定しようとしているので、これはベストプラクティスです。認証フローでも最適な機能もあります。
04.秘密鍵をダウンロードしてください
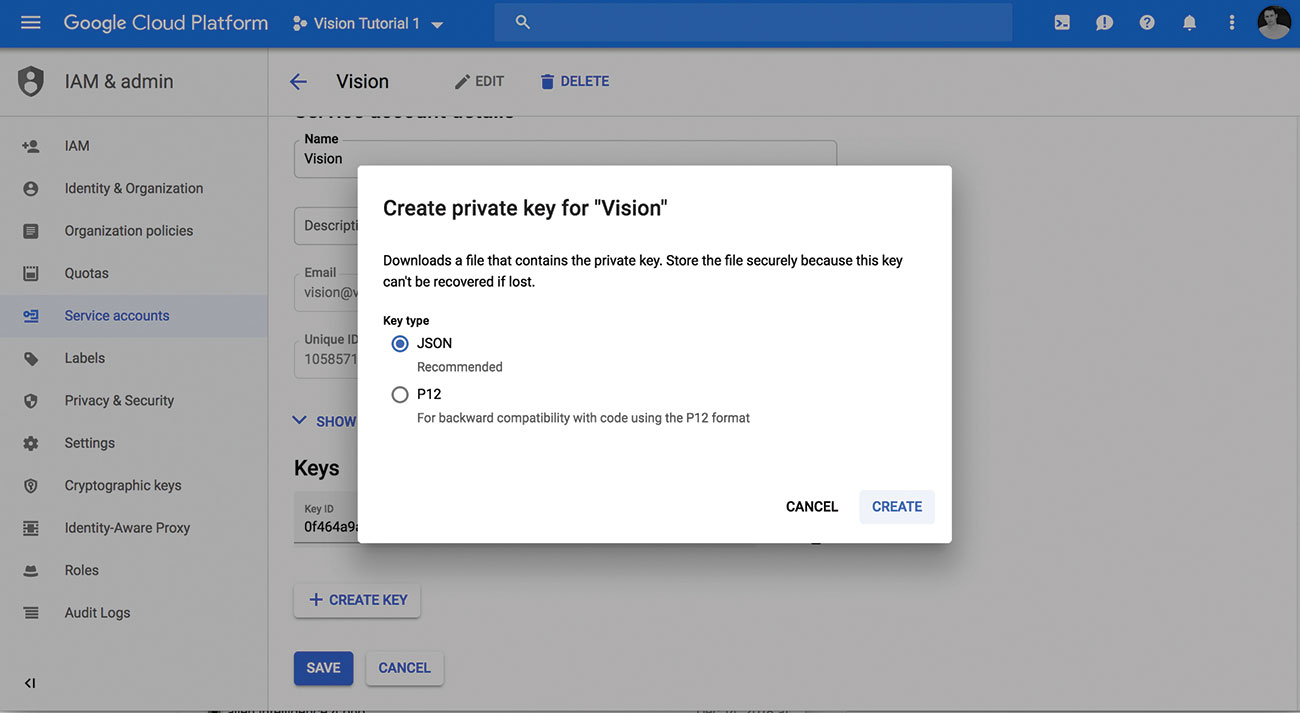
APIが有効とサービスアカウントでプロジェクトがあると、秘密鍵をJSONファイルとしてダウンロードできます。ファイルの場所を注意してください。そのため、次の手順で使用できます。
あなたが最初のいくつかのステップに問題があるならば、 クイックスタートガイド それはJSONキーのダウンロードで役立ちます。
05.環境変数を設定します
あなたはを設定する必要があります google_application_credentials 環境変数は、API呼び出しによってアクセスできます。これはあなたがダウンロードしたJSONファイルを指し、あなたが毎回パスを入力する必要があります。新しい端末ウィンドウを開き、を使用します 書き出す そのようなコマンド:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/[username]/Downloads/[file name].json"に代わる [ユーザー名] あなたのユーザー名を使って。秘密鍵ファイルを保存した場所へのパスが正しいことを確認してください。に代わる [ファイル名] 秘密鍵ファイルを使用して、ファイルへのパスを使用してください。
Windowsでは、次のようにコマンドラインで同じことを実行できます。
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\[username]\Downloads\[FILE_NAME].json"注:ターミナルまたはコンソールウィンドウを閉じると、その変数をもう一度設定するためにもう一度実行する必要があります。私たちはこれをまもなく私達のPHPコードに追加するので、もう一度心配する必要はありません。
06. APIに電話をかける
今、Cloud Vision APIに掘り下げる準備が整いました。 CURLを使用してAPIのクイックテストを行います。このメソッドもコードから使用することもできます。
PHP、Pythonまたはノードであろうと、ほとんどの言語でCURL要求を行うことができます。このようにして、コマンドラインでコールを指示するか、選択した言語で結果を変数に割り当てることができます。 Curlを使う上でいくつかの素早いヒントを見つけてください ここに 。
要求の詳細を保持するための単純なJSONファイルを作成します。あれを呼べ Google_Vision.Json. 。端末コマンドを実行する場所にローカルに保存します。
{174
"リクエスト":[
{
"画像":{
"ソース":{
「ImageUri」:
"https://upload.wikimedia.org/wikipedia/commons/9/93/golden_retriever_carlos_%2810581910556%29.jpg"
}
}、
"特徴": [{
"type": "type_unsecified"、
「MAXRESULTS」:50
}、
{
"type": "landmark_detection"、
「MAXRESULTS」:50
}、
{
"Type": "Face_detection"、
「MAXRESULTS」:50
}
{
"Type": "Label_detection"、
「MAXRESULTS」:50
}、
{
"type": "text_detection"、
「MAXRESULTS」:50
}、
{
"type": "safe_search_detection"、
「MAXRESULTS」:50
}、
{
"type": "image_properties"、
「MAXRESULTS」:50
}
]
}
]
上記のコードでは、顔検出やランドマーク検出など、使用する特定のAPI機能と同様に、分析する画像を表示しました。 safe_search_detection 画像が安全であり、それが成人の内容や暴力などのどのカテゴリに属しているかについて知るのに最適です。 image_properties 色やピクセルレベルの詳細について教えてください。
curlコマンドを実行するには、端末またはコマンドラインインターフェイスで、次のように入力します。
curl-x post -h "承認:ベアラ" $(gcloud auth application-default-default-access-token)-h "content-type:application / json; charset = UTF-8" --data-binary @ google_vision.json "https://vision.googleapis.com/v1/images:annotate">結果を使用することによって >結果 構文では、結果を新しいファイルに保存しておくことができます。あなたはAPIへのURLを示しました( "https://vision.googleapis.com/v1/images:annotate" そして、あなたのJSONデータを含めました 役職 それに。
これを使用するときに初めてプロンプトが表示されることもあります。そのプロンプトにはいまたはyに答え、JSONを返すはずです。
結果ファイルを開くと、JSONデータがVision APIリクエストから発生します。これがスニペットです:
{
"反応": [
{
"LabelAnnotations":[
{
"mid": "/ m / 0bt9lr"、
「説明」:「犬」、
「スコア」:0.982986
"TOPICALITY":0.982986
}、
{
"mid": "/ m / 01t032"、
「説明」:「ゴールデンレトリーバー」、
「スコア」:0.952482
"TOPICALITY":0.952482
}、
{
... あなたはすぐに非常に有用な結果を見ます。下 LabelAnnotations. ノード、画像に「犬」と95パーセントが「ゴールデンレトリーバー」が含まれていると95パーセントの一致を見ることができます。 AIはすでに画像の内容およびその他の詳細を識別し、「鼻」を含むその他の詳細とそれが可能性が高い「スポーツ犬」である。
これは、すでに訓練されたGoogle Vision AIシステムのためにあなたの部品にトレーニングを受けませんでした。結果をスキャンすると、推奨される作物領域からのすべてがすべてのものを見ることができます。カラーやコンテンツなど、画像内にあるものの素晴らしい詳細には、画像内にあるものの詳細な詳細を表示します。 APIがどれほど強力であるかを確認するために他の画像で試してみてください。
使用するコールをテストするには、このメソッドを使用し続けることができます。あなたはあなたが好む言語で地元のSDKを設定することもでき、それをあなたのアプリに統合することもできます。
07.クライアントライブラリをインストールします
次に、APIをプロジェクトに統合する方法を示すために、簡単なWebベースのアプリを作成します。
統合を容易にするためにさまざまな言語で利用可能なさまざまなSDKがあります。この次のセクションにはPHP SDKを使用します。あなたが別の言語に続くコードを微調整したい場合は、SDKの素晴らしいリソースがあります ここに 。
Localサーバーまたはリモートサーバーにプロジェクトフォルダが設定されていることを確認してください。すでに持っていない場合は、Composerを取得してプロジェクトフォルダにインストールします。任意選択で、あなたはすでにグローバルにインストールされていて、それも元気でもあるかもしれません。
次のcomposerコマンドを実行して、クラウドビジョンSDKのベンダーファイルをインストールします。
php -r "copy( 'https://getcomposer.org/installer'、 'composer-setup.php');
php -r "IF(hash_file( 'sha384'、 'composer-setup.php')=== '93b54496392C0627746 70ac18b134c3b3a95e5a5e5c8
F1A9F115F203B75BF9A129D5DAA8BA6A13E2CC8A1DA080
6388A8 '){Echo' Installer Verified '; erse {echo 'インストーラが破損しています。 unlink( 'composer-setup.php'); echo php_eol; "
php composer-setup.php.
php -r "unrink( 'composer-setup.php');"
php composer.pharにはGoogle / Cloud-Visionが必要ですComposerはプロジェクトフォルダにベンダーフォルダを作成し、すべての依存関係をインストールします。あなたがこれを立ち上げてphpを使いたいと思ったら、あなたはこれをチェックアウトすることができます Composerリソースのインストール 。
08.新しいファイルを作成します
プロジェクトフォルダに新しいPHPファイルを作成します。ただし、クイックテストのために画像をアップロードするための単純なHTMLフォームが好きですが設定します。これが、次の形式のPHPファイルの例です。
< DOCTYPE HTML>
< html>
<頭>
< title> net - コンピュータビジョンチュートリアル< / title>
< / gt;
< body>
<フォームaction = "index.php" enctype = "multipart / form-data" method = "post">
< h1>画像コードには、フォームを持つ基本的なHTMLファイルとPHPコードのプレースホルダが含まれています。コードは、フォームから提出された画像の存在のチェックを開始します。まだ提出されていない場合は、それは何もしません。
09.画像を保存します
オンラインまたはシステム上で画像を指すことをお勧めしたい場合は、この手順をスキップしてください。選択した画像を処理したい場合は、このコードを追加して選択した画像を保存してください。
//画像を保存してください
$ filePath = $ _files ["file"] ["name"];
if(move_uploaded_file($ _ファイル["file"] ["tmp_name"]、$ filepath)){
"< p> img src ="。 "style = 'width:400px;高さ:auto; / gt;< / p>
} そうしないと {
エコー "エラー!!";
10.環境変数を追加します
あなたはを設定する必要があります google_application_credentials 認証するための変数。 PHPでは私たちはを使っています put put 環境変数を設定するコマンド。 PHPコードの次にこのコードを追加してください。
Putenv( 'Google_Application_Credentials = / Users / RichardMattka / Downloads / Vision Tutorial 1-0F464A9A0F7B.JSON'); パスとファイル名をJSON秘密鍵ファイルに置き換えます。
11.ライブラリを含めます
ライブラリを追加して初期化します 言語屋 あなたのコードのクラス。次にこのコードを追加してください。
__dir__を必要とします。 '/vendor/autoload.php';
Google \ Cloud \ Vision \ V1 \ ImageAnnotatorClientを使用してください。
$ PROJECTID = 'VISION-TUTORIAL-1';
$ imageAnnotator = New ImageAnnotatorClient([]
'ProjectID' => $ ProjectID
]); ベンダーのオートロードを必要とすることから始めます。依存関係が必要な場合は、これはPythonまたはノードで似ています。輸入 ImageAnnotatorClient. 次に、クラスを利用します。あなたの定義 プロジェクション 。これが何であるかわからない場合は、Google Cloud Projectコンソールで調べてください。最後に、新品を作成してください imageAnnotatorClient. ProjectIDを使用してそれを割り当ててください $ imageAnnotator. 変数。
12.画像の内容を分析します
分析のためにAPIにイメージを送信し始めます。結果を今のところでjsonとして表示するが、実際には結果を評価し、必要な方法で使用することができます。
画像をAPIに送信するには、次のものを追加します。
$ image = file_get_contents($ FilePath);
$ RESPONS = $ IMANNEANTATOR - > LABELDETECTERECTION($画像);
$ LABELS = $ RESPONSE - > getLabelAnnotations();
foreach($ラベルとしての$ラベル){
"< divクラス= '結果'>
$ result = $ label - gt; getDescription();
エコー$の結果。 "(" $ label-> getScore() ")";
エコー "< / div>";
これにより、送信されたフォームからの内容が送信されます。 ImageAnnotator. 結果をエンドポイントと保存します $応答 変数。それを指定します LabelDetection 特徴。あなたも使うことができます 顔検出 、 ロゴ画像 、 TechnEDetection そして他の多くの機能。全リストの場合は、 こちらを確認してください 。
次に、ラベルのリストを繰り返します。これはそれを使用する方法を示す例です。プロシージャーを処理して結果に反応することができます。
13.面を検出します

APIがどのくらい強力になっているかのもう1つの迅速な例 顔検出 関数。これは感情データを返し、画像内の場所の場所情報と同様に、顔の位置情報を返します。このコードを試してみて、それがどのように機能するかを確認してください。
$ RESPONS = $ IMANANNOTATOR - > FACEEDETECTERECTION($ IMART);
$ faces = $ Response-> getFaceAnnotations();
$尤度Name = ['不明 "、' very_unlibely '、' louncyly '、
「可能性がある」、「おそらく」、「very_libely」]。
// var_dump($ラベル);
foreach($顔として$顔){
"< divクラス= '結果'>
$怒り= $ FACE - > getangerLikeirhood();
PRINTF( "怒り:%s"。PHP_EOL、$尤度名[$怒り]);
$ Joy = $ FACE - > getjoylikirihhood();
PRINTF( "喜び:%s"。PHP_EOL、$尤度名[$ Joy]);
$ vertices = $ FACE - gt; getBoundingPoly() - > getvertices();
$ bounds = [];
foreach($頂点としての頂点){
$範囲[] = sprintf( '(%d、%d)'、$ vertex- gt; getX()、$ vertex- gt; gety());
}
print( '範囲:'。結合( '、'、$範囲)。php_eol);
エコー "< / div>";
あなたはそれを使って始めます 顔検出 アノテータの機能と前の例のように画像を渡します。それからあなたは入手します FaceAnnotiatons. 。あなたはより一般的な言語で応答重みの配列を使うので、あなたは特定の感情の可能性を見ることができます。これに続いて、あなたは以前の応答を繰り返します。あなたはそれらの結果を返すいくつかの可能な感情、怒りと喜びのうちの2つをチェックします。これはまた、見つかった各顔を定義する境界ボックスの角を与えるでしょう。
この記事はもともと発行316に発行されました ネット Webデザイナーや開発者向けの世界で最も売れている雑誌。 ここに問題316を購入してください または ここで購読する 。
関連記事:
- 素晴らしいAIツールは魔法のような写真を再構築します
- Google Analyticsの17トップツール
- 最高のコード編集者
操作方法 - 最も人気のある記事



Photoshopのテクスチャの使い方
操作方法 Feb 3, 2026テクスチャは、伝統的なアートワークとデジタルアートワークの間の行をぼかしたものです。あなたのデジタルアートワークがその背後にあ�..





カテゴリ
- AI&機械学習
- エアポッド
- アマゾン
- Amazon Alexa&Amazon Echo
- Amazon Alexa&Amazon Echo
- Amazon Fire TV
- Amazon Prime Video
- Android
- Android携帯電話&タブレット
- Android電話とタブレット
- Android TV
- アップル
- Apple App Store
- Apple Homekit&Apple HomePod
- アップルミュージック
- アップルテレビ
- アップルウォッチ
- Apps&Web Apps
- アプリとWebアプリ
- オーディオ
- Chromebook&Chrome OS
- Chromebook&Chrome OS
- Chromecast
- クラウド&インターネット
- クラウドとインターネット
- クラウドとインターネット
- コンピュータハードウェア
- コンピュータ履歴
- コード切断&ストリーミング
- コード切断とストリーミング
- そば
- ディズニー+
- DIY
- 電気自動車
- EReaders
- 必需品
- 説明者
- ゲーム
- 一般
- Gmail
- Google Assistant&Google Nest
- Google Assistant&Google Nest
- Google Chrome
- Google Docs
- Google Drive
- Googleマップ
- Google Play Store
- Google Sheets
- Googleスライド
- Google TV
- ハードウェア
- HBO MAX
- 操作方法
- Hulu
- インターネットスラング&略語
- IPhone&iPad
- Kindle
- Linux
- Mac
- メンテナンスと最適化
- マイクロソフトエッジ
- Microsoft Excel
- Microsoft Office
- Microsoft Outlook
- Microsoft PowerPoint
- マイクロソフトチーム
- Microsoft Word
- Mozilla Firefox
- Netflix
- ニンテンドースイッチ
- パラマウント+
- PCゲーム
- 孔雀
- 写真
- Photoshop
- プレイステーション
- プライバシーとセキュリティ
- プライバシーとセキュリティ
- プライバシーとセキュリティ
- 製品全体の
- プログラミング
- ラズベリーPI
- 六王
- サファリ
- サムスン携帯電話&タブレット
- サムスンの電話とタブレット
- スラック
- スマートホーム
- スナップチャット
- ソーシャルメディア
- 空
- Spotify
- TINDER
- トラブルシューティング
- テレビ
- ビデオゲーム
- バーチャルリアリティ
- VPNS
- Webブラウザ
- WiFi&ルーター
- Wifi&ルーター
- Windows
- Windows 10
- Windows 11
- Windows 7
- Xbox
- YouTube&YouTube TV
- YouTube&YouTube TV
- ズーム
- 説明者