Ein Leitfaden für die Cloud-Vision von Google

Maschinelles Lernen. Tiefes Lernen. Verarbeitung natürlicher Sprache. Computer Vision. Automatisierung. Spracherkennung. Sie haben wahrscheinlich all diese und viele andere Bedingungen in letzter Zeit unter dem Regenschirm der künstlichen Intelligenz gehört. Tatsächlich wächst das Feld so schnell, es wird immer schwieriger, eine endgültige Definition zu nageln. AI wird Teil von fast jedem Aspekt unseres Lebens von E-Commerce-Websites. und Suchmaschinen, um Ihr Telefon freizuschalten.
Ihre Websites und Apps können APIs nutzen, um direkt in die Leistung von AI zu tippen. Ohne die AI-Agenten zu trainieren, können Sie massive Mengen von bereits analysierten Daten nutzen. Google, Amazon, IBM und viele andere haben Endpunkte für Entwickler geschaffen, um einzuhaken und mithilfe von AI sofort zu verwenden.
Am vorderen Ende können Sie Sprachbefehle, Chatbot-Schnittstellen oder reaktive Webgl-kreative Elemente anschließen. Auf dem hinteren Ende verwenden Datenbanken intelligente Algorithmen, um die Geschwindigkeit und Analyse zu maximieren. APIs kann eine Abstraktionschicht aus einem breiten Sortiment an AI-Funktionen bereitstellen, von Vorhersagen bis hin zu kollektiven Training.
Denken Sie daran, wenn Sie Ihre Website komplexer machen, ist es wichtig, dass Sie Ihre Wahl bewerten Web-Hosting Service, um sicherzustellen, dass es damit umgehen kann. Eine Website von Grund auf machen? Erwägen Sie, den Prozess mit einem Top zu vereinfachen Webseitenersteller . Und wenn Sie ein neues erstellen Designsystem Es ist wichtig, es sicher zu halten und anständig zugänglich zu halten Cloud-Speicherung. .
- Ein Leitfaden für die Webwerkzeuge von Google
Was ist Computervision?
Computervision ist die Studie und Erstellung von künstlichen Systemen, die Informationen aus Bildern extrahieren. Es kann auch das mechanische Sichtsystem selbst umfassen. In Bezug auf die Anerkennung ist es der Prozess der Analyse und Bestimmung des Inhalts eines Bildes oder einer Reihe von Bildern (einschließlich Video). Dies könnte medizinische Scans, Fotos, 360-Grad-Video und praktisch jede Art von Bildern einschließen, die Sie sich vorstellen können.
AI-Powered Computer Vision kann:
- Identifizieren, Beschriften und kategorisieren Sie den Inhalt
- Gesichter und Emotionen erkennen
- Erkenne Kopfbedeckungen wie Gläser und Hüte
- Identifizieren Sie Sehenswürdigkeiten, Gebäude und Strukturen
- Bewerten Sie die Informationen von Pixelebene wie Farbdaten, Qualität und Auflösung
- Beliebte Logos erkennen.
- Text identifizieren und lesen
- Identifizieren Sie möglicherweise unangemessene Bilder
Computer Vision mit Google's Cloud Vision API
Es gibt viele Möglichkeiten für Vision APIs, aber wir verwenden die Cloud Vision-API von Google. Google beherbergt viele AI-APIs, darunter natürliche Sprachverarbeitung, Spracherkennung, tiefes Lernen und Sehen.
Die Cloud Vision-API ermöglicht es Ihren Websites und Apps, zu verstehen, was sich in einem Bild befindet. Es klassifiziert den Inhalt in Kategorien, die alles bezeichnen, was er sieht. Es bietet auch einen Konfidenz-Score, so dass Sie wissen, wie wahrscheinlich es ist, dass das, was es glaubt, dass sich in einem Bild tatsächlich erscheint. Sie können dies verwenden, um intelligent in Intelligent in Bezug auf die Kameraeingabe in AR- oder Video-Apps zu interagieren. Sie können Werkzeuge erstellen, um diejenigen zu unterstützen, die sehbehindert sind. Sie können Assistenten erstellen, um Gebäude oder Sehenswürdigkeiten für Touristen zu erkennen. Die Möglichkeiten sind endlos.
01. Richten Sie ein Cloud-Projekt ein
Wenn Sie die APIs von Google bereits verwendet haben, sind einige dieser ersten Schritte vertraut. Wie bei anderen Google-Services müssen Sie ein Cloud-Projekt einrichten. Auf den Weg gehen Google Cloud-Plattformkonsole und erstellen Sie ein neues Projekt oder wählen Sie einen vorhandenen aus. Wie die meisten von Google's Services ist die Cloud Vision-API kostenlos, bis Sie viele API-Anfragen machen. Möglicherweise müssen Sie Abrechnungsinformationen eingeben, wenn Sie die API aktivieren, aber dies wird nicht in einem niedrigen Anforderungsvolumen berechnet, und Sie können die Dienste nach dem Testen entfernen.
02. Aktivieren Sie die Cloud Vision-API
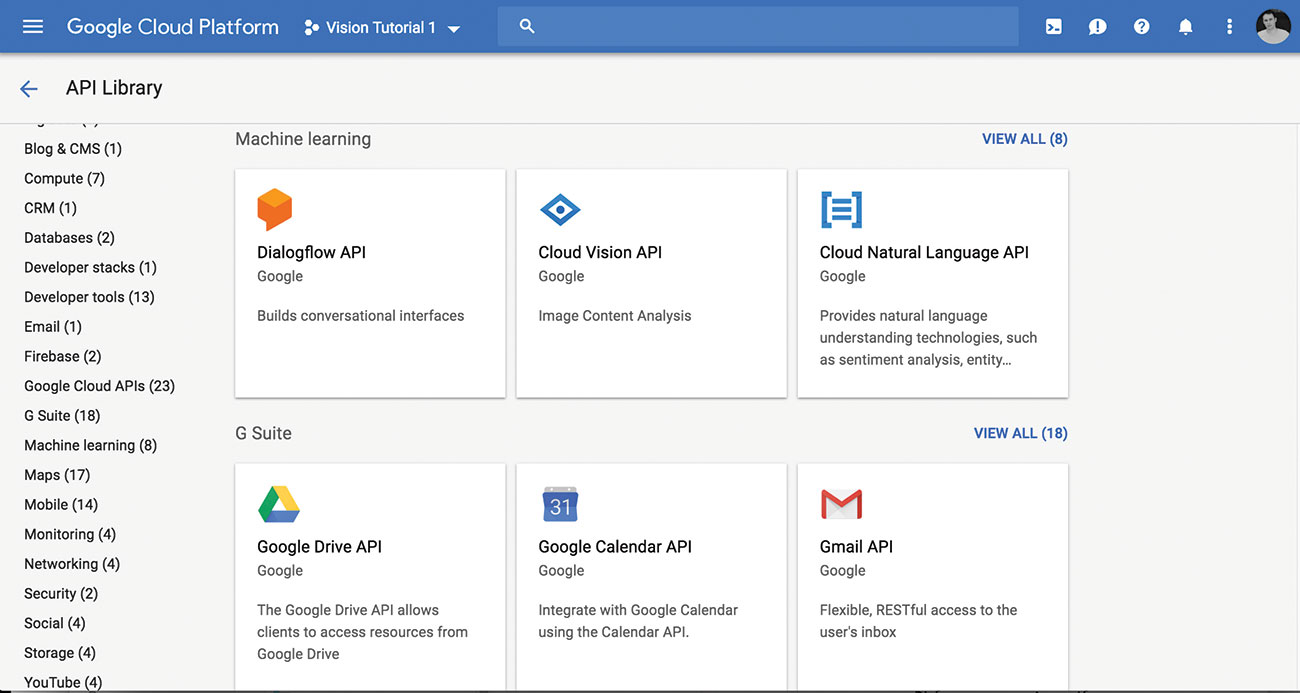
Durchsuchen Sie das API-Bibliothek und wählen Sie die Cloud Vision-API für Ihr Projekt aus.
Sobald Sie aktiviert sind, sollten Sie einen kleinen Green-Check sehen und die Meldung 'API aktiviert' daneben.
03. Erstellen Sie ein Service-Konto
Als nächstes müssen Sie ein einrichten Dienstleistungskonto . Denken Sie an die API als Web-Service, den Sie erstellen. Da wir uns wie ein typischer Service einrichten werden, ist dies die beste Praxis. Es funktioniert auch am besten mit dem Authentifizierungsfluss.
04. Privater Schlüssel herunterladen
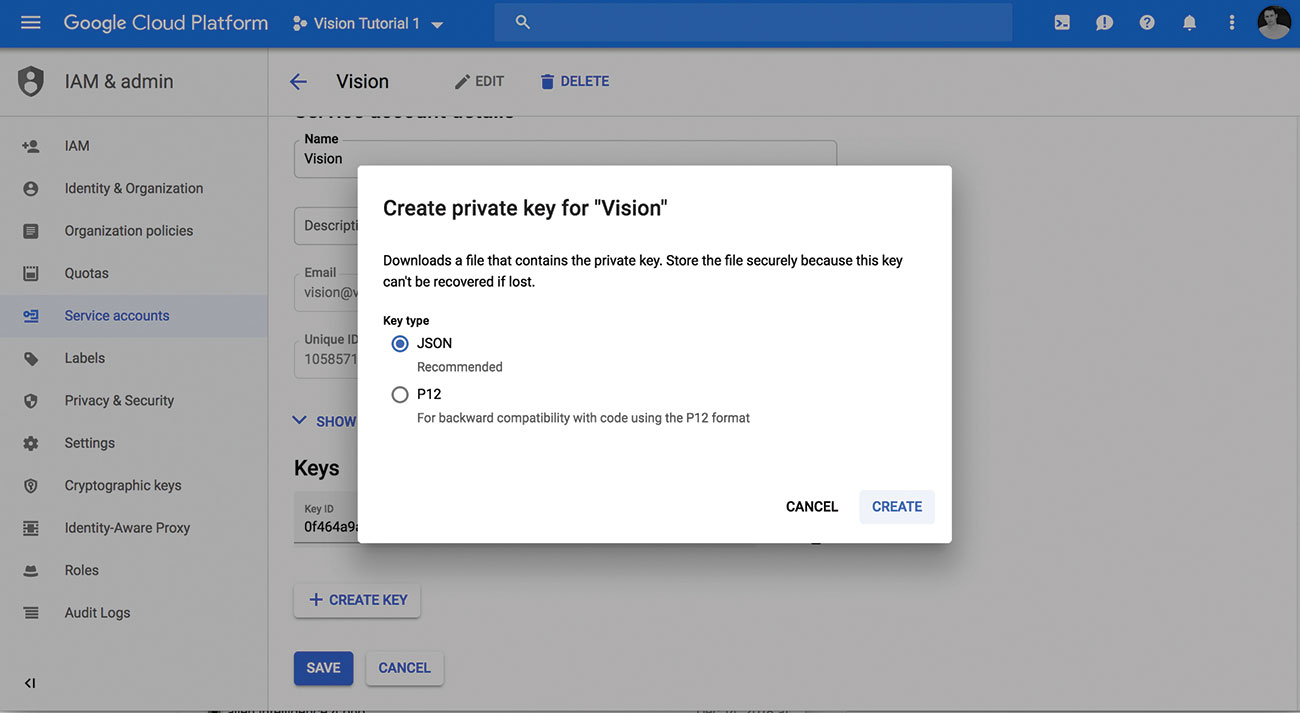
Wenn Sie ein Projekt mit dem API-aktivierten und einem Service-Konto haben, können Sie Ihren privaten Schlüssel als JSON-Datei herunterladen. Beachten Sie den Speicherort der Datei, sodass Sie es in den nächsten Schritten verwenden können.
Wenn Sie Probleme mit den ersten Schritten haben, gibt es ein kurzer Startanleitung das hilft und endet mit dem Download der JSON-Taste.
05. Umgebungsvariable einstellen
Sie müssen das einstellen Google_application_credentials. Umweltvariable, so kann es von unseren API-Anrufen zugegriffen werden. Dies zeigt an die JSON-Datei, die Sie gerade heruntergeladen haben, und speichert Sie, dass Sie den Pfad jedes Mal eingeben müssen. Öffnen Sie ein neues Terminalfenster und verwenden Sie die Export Befehl wie so:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/[username]/Downloads/[file name].json"Ersetze das [Nutzername] mit Ihrem Benutzernamen. Stellen Sie sicher, dass der Pfad zu dem Ort, an dem Sie gespeichert haben, dass die private Schlüsseldatei korrekt ist. Ersetze das [Dateinamen] mit Ihrer privaten Schlüsseldatei und verwenden Sie den Pfad in Ihre Datei.
Bei Windows können Sie das Gleiche über die Befehlszeile tun, wie folgt:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\[username]\Downloads\[FILE_NAME].json"Hinweis: Wenn Sie Ihr Terminal- oder Konsolenfenster schließen, müssen Sie möglicherweise wieder ausführen, um die Variable erneut einzustellen. Wir fügen uns auch in Kürze in unseren PHP-Code hinzu, sodass Sie sich nicht mehr darüber machen müssen.
06. Machen Sie einen Anruf an die API
Jetzt können Sie bereit, in die Cloud Vision-API zu graben. Sie verwenden Curl, um schnelle Tests der API mitzunehmen. Sie können diese Methode auch auch von Ihrem Code verwenden.
Die Curl-Anforderungen können in den meisten Sprachen erfolgen, unabhängig davon, ob PHP, PYDHON oder Knoten ist. Auf diese Weise können Sie die Anrufe direkt in der Befehlszeile erstellen oder das Ergebnis einer Variablen in der Sprache Ihrer Wahl zuweisen. Finden Sie einige schnelle Tipps zur Verwendung von Curl Hier .
Erstellen Sie eine einfache JSON-Datei, um die Details der Anforderung zu halten. Nennen google_vision.json. . Speichern Sie es lokal, wo Sie die Terminalbefehle ausführen möchten.
{{
"Anfragen": [
{
"Bild":{
"Quelle":{
"Imageuri":
"https://uppload.wikimedia.org/wikipedia/carlons/9/93/golden_retriever_carlos_%2810581910556%29.jpg"
}
},
"Eigenschaften": [{
"Typ": "type_unspecified",
"MaxResults": 50
},
{
"Typ": "landmark_detection",
"MaxResults": 50
},
{
"Typ": "Face_Detection",
"MaxResults": 50
}
{
"Typ": "label_detection",
"MaxResults": 50
},
{
"Typ": "text_detection",
"MaxResults": 50
},
{
"Typ": "Safe_Search_Detection",
"MaxResults": 50
},
{
"Typ": "Image_Properties",
"MaxResults": 50
}
]
}
]
} Im obigen Code haben Sie ein Bild analysiert, um zu analysieren, sowie bestimmte API-Funktionen zu verwenden, einschließlich Gesichtserkennung und Wahrzeichenerfassung. Safe_search_detection. ist großartig, um zu wissen, ob das Bild sicher ist und in welcher Kategorie sie gehört, wie Erwachseneninhalte oder gewalttätig. Image_properties. Erzählt Ihnen die Details von Farben und Pixelebene.
Geben Sie zum Ausführen des Curl-Befehls in Ihrer Terminal- oder Befehlszeilenoberfläche das Folgende ein.
curl -x post -h "Autorisierung: Inhaber" $ (GCLOUD AUTH-Anwendung-Standarddruck-Zugriff-Token) -H "Content-Type: Application / JSON; charet = UTF-8" --Data-Binary @ google_vision.json "https://vision.googleapis.com/v1/images:Agotate" & gt; Ergebnisse Mit dem verwendeten & gt; Ergebnisse Syntax, Sie haben die in einer neuen Datei gespeicherten Ergebnisse, die in einer neuen Datei gespeichert sind. Sie haben die URL an die API angegeben ( "https://vision.googleapis.com/v1/images:Annotate" ) und enthalten Ihre JSON-Daten an POST dazu.
Sie können das erste Mal dazu auffordern, dass Sie das erste Mal verwenden, um die API zu aktivieren oder den Zugriff zulassen. Beantworten Sie Ja oder Y an diese Eingabeaufforderung und sollte den JSON zurückgeben.
Wenn Sie die Ergebnisdatei öffnen, erhalten Sie von der Vision-API-Anforderung JSON-Datenergebnisse. Hier ist ein Snippet:
{
"Antworten": [
{
"Labelannments": [
{
"MID": "/ M / 0BT9LR",
"Beschreibung": "Hund",
"Score": 0.982986,
"Aktualität": 0.982986
},
{
"MID": "/ M / 01T032",
"Beschreibung": "Golden Retriever",
"Score": 0.952482,
"Aktuelles": 0.952482
},
{
... Sie sehen einige sehr nützliche Ergebnisse sofort. Unter dem Labelannoten Knoten, Sie können eine 98 Prozent-Übereinstimmung sehen, dass das Bild einen "Hund" und eine 95-Prozent-Übereinstimmung enthält, die einen "Golden Retriever" enthält! Die AI hat den Inhalt des Bildes und anderer Details bereits identifiziert, einschließlich einer "Schnauze" und der Tatsache, dass es wahrscheinlich ein "sportlicher Hund" ist.
Dies erforderte aufgrund des bereits ausgebildeten Google Vision-AI-Systems kein Training Ihrer Seite. Scannen Durch den Ergebnissen sehen Sie alles aus empfohlenen Erntebereiche - für das automatische Zuschneiden von Bildern zu Themen - zu unglaublichen Details dessen, was sich in den Bildern befindet, einschließlich Farben und Inhalte. Probieren Sie es mit anderen Bildern aus, um zu sehen, wie leistungsstark die API ist.
Sie können diese Methode weiterhin verwenden, um die Anrufe zu testen, die wir verwenden. Sie können auch ein lokales SDK in einer Sprache einrichten, die Sie bevorzugen und in Ihre App integrieren.
07. Installation der Clientbibliothek
Als Nächstes erstellen Sie eine einfache webbasierte App, um zu zeigen, wie Sie die API in Ihre Projekte integrieren können.
Es gibt eine Reihe von SDKs, die in einer Vielzahl von Sprachen verfügbar sind, um die Integration einfach zu gestalten. Sie verwenden das PHP-SDK für diesen nächsten Abschnitt. Wenn Sie den Code optimieren möchten, der in eine andere Sprache folgt, gibt es eine großartige Ressource von SDKs Hier .
Beginnen Sie, indem Sie sicherstellen, dass Sie einen Projektordner auf Ihrem lokalen oder Remote-Server einrichten lassen. Wenn Sie es noch nicht haben, erhalten Sie den Komponisten und installieren Sie es in Ihrem Projektordner. Optional haben Sie möglicherweise den bereits weltweit installierten Komponisten, und das ist auch in Ordnung.
Führen Sie den folgenden Composer-Befehl aus, um die Anbieter-Dateien für die Cloud Vision SDK zu installieren.
PHP -R "copy ('https://getcomposer.org/installer', 'composer-setup.php');"
PHP -R "IF (Hash_File ('SHA384', 'Composer-Setup.php') === '93B54496392C0627746 70AC18B134C3B3A95E5A5E5C8
F1A9F115F203B75BF9A129D5DAA8BA6A13E2CC8A1DA080.
6388A8 ') {Echo' Installer Verifiziert '; } else {Echo 'Installer Corrupt';; Unlink ('composer-setup.php'); } Echo php_eol; "
PHP Composer-Setup.php
PHP -R "Unlink (Composer-Setup.php ');"
PHP Composer.phar erfordern Google / Cloud-Vision Komponist erstellt einen Anbieterordner in Ihrem Projektordner und installiert alle Abhängigkeiten für Sie. Wenn Sie feststellen, dass Sie das einstellen und PHP verwenden möchten, können Sie dies überprüfen Komponisten-Ressource installieren. .
08. Erstellen Sie eine neue Datei
Erstellen Sie eine neue PHP-Datei in Ihrem Projektordner. Setzen Sie es jedoch, wie Sie möchten, aber ein einfaches HTML-Formular, um Bilder zum Schnelltest hochzuladen. Hier ist ein Beispiel PHP-Datei mit dem enthaltenen Formular:
& lt; doctype html & gt;
& lt; HTML & GT;
& lt; head & gt;
& lt; Titel & GT; Net - Computer Vision Tutorial & lt; / title & gt;
& lt; / head & gt;
& lt; body & gt;
& lt; Forme Action = "Index.php" Enctype = "Multipart / Form-Data" -Methode = "Post" & GT;
& lt; H1 & GT; Select Image & lt; / h1 & gt;
& lt; Eingangstyp = "Datei" Name = "Datei" & GT; & lt; br / & gt; & lt; br / & gt;
& lt; Eingabetyp = "Senden" Wert = "Bild hochladen" Name = "Senden" & gt; & lt; br / & gt;
& lt; / form & gt;
& lt; div class = "Ergebnisse" & gt;
& lt; PHP
// PHP-Code geht hier //
if (! Isset ($ _ Post ['Senden'])) {sterb (); }
? & gt;
& lt; / div & gt;
& lt; / body & gt;
& lt; / html & gt; Der Code enthält eine grundlegende HTML-Datei mit einem Formular und einem Platzhalter für den PHP-Code. Der Code beginnt mit der Überprüfung der Existenz des Bildes, das aus dem Formular eingereicht wurde. Wenn es noch nicht eingereicht wird, tut es nichts.
09. Speichern Sie das Bild
Wenn Sie lieber auf Bilder online oder auf Ihrem System angeben möchten, überspringen Sie diesen Schritt. Wenn Sie Bilder auswählen möchten, fügen Sie diesen Code hinzu, um das ausgewählte Bild zu speichern.
// Bild speichern
$ filepath = $ _files ["Datei"] ["Name"];
if (Move_UPLADED_FILE ($ _-Dateien ["Datei"] ["TMP_NAME"], $ FilePath)) {
Echo "& lt; p & gt; & lt; iMG src =". $ filepath. "Style = 'Breite: 400px; Höhe: Auto;' / & gt; & lt; / p & gt; ";
} else {
echo "Fehler !!";
} 10. Fügen Sie Umgebungsvariable hinzu
Sie müssen das einstellen Google_application_credentials. Variable dafür zur Authentifizierung. In PHP verwenden wir das Putenv. Befehl, eine Umgebungsvariable einzustellen. Fügen Sie diesen Code neben Ihrem PHP-Code hinzu:
PUTENV ('Google_application_credentials = / Benutzer / RichardMattka / Downloads / Vision Tutorial 1-0F464A9A0F7B.JSON'); Ersetzen Sie den Pfad- und Dateinamen in Ihrer JSON Private Key-Datei.
11. Fügen Sie die Bibliothek ein
Fügen Sie die Bibliothek hinzu und initialisieren Sie die Langweilig Klasse in Ihrem Code. Fügen Sie diesen Code neben:
erfordern __dir__. '/vendor/autoload.php';
Verwenden Sie Google \ Cloud \ Vision \ V1 \ ImageNnotatorClient;
$ projectid = 'Vision-Tutorial-1';
$ imageannnotator = new imageannotatorclient ([
'projectid' = & gt; $ projecid.
]); Beginnen Sie mit der Anforderung des Herstellers Autoload. Dies ist in Python oder Knoten ähnlich, wenn Sie Ihre Abhängigkeiten benötigen. Das importieren ImageannotatorClient. als nächstes, um die Klasse zu nutzen. Definieren Sie Ihr projiziert . Wenn Sie sich nicht sicher sind, was das ist, schauen Sie in Ihrer Google Cloud-Projektkonsole auf. Schließlich erstellen Sie ein neues ImageannotatorClient. Objekt mithilfe Ihres Projektidens und weisen Sie es der $ imageannnotator. Variable.
12. Bildinhalt analysieren
Senden Sie das Bild an die API zur Analyse. Sie zeigen das Ergebnis als JSON zum Bildschirm an, aber in der Praxis können Sie die Ergebnisse bewerten und belegten, wie Sie möchten.
Fügen Sie folgendermaßen hinzu, um das Bild an die API einzureichen.
$ bild = file_get_contents ($ filepath);
$ Response = $ imageannnotator- & gt; labeldetection ($ bild);
$ labels = $ response- & gt; getlabelannoten ();
foreach ($ Etiketten als $ label) {
echo "& lt; div class = 'Ergebnis' & gt;";
$ result = $ label- & gt; gettescription ();
Echo $ Ergebnis. "(". $ label- & gt; GetScore (). ")";
echo "& lt; / div & gt;";
} Dies gilt den Inhalt von dem eingereichten Formular an das Imageannotator. Endpunkt und speichert das Ergebnis in der $ Antwort Variable. Es gibt das an Labeldetection. Merkmal. Sie können auch verwenden Gesichtserkennung , LogDection , TextDetection. und viele andere Funktionen. Für eine vollständige Liste, überprüfe hier .
Als nächstes über die Liste der Labels. Dies ist nur ein Beispiel, um zu zeigen, wie Sie es verwenden können: Sie können es verarbeiten und auf die Ergebnisse reagieren, jedoch müssen Sie jedoch benötigen.
13. Gesichter erkennen.

Ein weiteres kurzes Beispiel dafür, wie mächtig die API ist, liegt in der Gesichtserkennung Funktion. Dies gibt Emotiondaten sowie die Standortinformationen, wo in dem Bild die Gesichter sind. Testen Sie diesen Code, um zu sehen, wie es funktioniert.
$ Response = $ imageannnotator- & gt; Foundetection ($ bild);
$ Gesichter = $ Antwort- & GT; GetFaceannotationen ();
$ likelihoodname = ['unbekannt', 'sehr_unlikely', 'unwahrscheinlich',
"Möglich", "wahrscheinlich", "sehr_likely";
// var_dump ($ markels);
foreach ($ Gesichter als $ Gesicht) {
echo "& lt; div class = 'Ergebnis' & gt;";
$ anger = $ face- & gt; Getangerlikerihood ();
Printf ("Wut:% s". php_eol, $ likelihoodname [$ anger]);
$ Joy = $ Face- & GT; Getjoylikelihood ();
Printf ("Freude:% s". php_eol, $ likelihoodname [$ Joy]);
$ Scheitelpunkte = $ Face- & gt; getBoundingPoly () - & gt; Getvertices ();
$ Grenzen = [];
foreach ($ Eiter als $ vertex) {
$ Grenzen [] = Sprintf ('(% d,% d)', $ vertex- & gt; getX (), $ vertex- & gt; gaty ());
}
drucken ('Grenzen:'. Join (',', $ Grebs). php_eol);
echo "& lt; / div & gt;";
} Sie fangen an, indem Sie die Gesichtserkennung Funktion des Annotators und des Durchlaufs in das Bild wie das vorherige Beispiel. Dann bekommst du das Gesichtsnotiaturen . Sie verwenden ein Array von Antwortgewichten in der häufigeren Sprache, sodass Sie die Wahrscheinlichkeit bestimmter Emotionen sehen können. Folgen, dass Sie die Antwort wie zuvor iterieren. Sie überprüfen zwei von mehreren möglichen Emotionen, Wut und Freude, was die Ergebnisse derer zurückgibt. Dies gibt Ihnen auch die Ecken der Begrenzungskästen, die jedes gefundene Gesicht definieren.
Dieser Artikel wurde ursprünglich in Ausgabe 316 von veröffentlicht Netz Das weltweit meistverkaufte Magazin für Webdesigner und Entwickler. AUSGABE 316 Hier kaufen oder Abonnieren Sie hier .
Zum Thema passende Artikel:
- Das erstaunliche AI-Tool rekonstruiert Fotos wie Magie
- 17 Top-Tools in Google Analytics
- Die besten Code-Editoren
wie man - Die beliebtesten Artikel

Wie zeichnet man einen Vogel
wie man Feb 2, 2026Lernen, wie man einen Vogel zeichnet, kann ein brillanter Zeitvertreib sein. Wenn Sie auf der Suche nach Ihren Zeichnungskenntnissen suchen oder daran denk..

Farbe ausdrucksstarker Porträtkunst mit Arttrage 5
wie man Feb 2, 2026Arttrage ist ein beliebtes digitales Kunstwerkzeug (für mehr Artrage Einführung) In diesem Tutorial bringt ich S..

17 Möglichkeiten, bessere Kreaturen zu zeichnen
wie man Feb 2, 2026Wenn Sie Kreaturen ziehen, ist es wichtig, dass sie glaubwürdig sind. Egal wie verrückt Ihre Designs werden, denken Sie daran, ..

Wie zeichnet man eine große Katze mit Pastellen
wie man Feb 2, 2026Die Weichheit und die Leuchtkraft der Pastellstöcke machen sie zur idealen Wahl für Hintergründe in meiner Pastellzeic..


Procreate Tutorial: Neue Tools erforscht
wie man Feb 2, 2026Als ich zum ersten Mal entdeckte, dass Procreate ich von der Idee verblüfft war, ein tragbares Gerät zu haben, das mir ermögli..

Wie erstellt man eine vollseitige Website in Winkel
wie man Feb 2, 2026Seite 1 von 4: Seite 1 Seite 1 Seite 2 Seite 3 ..

So verbessern Sie die Leistung von E-Commerce-Sites
wie man Feb 2, 2026Tammy Everts. gibt eine Präsentation über die Verbindung zwischen Design, Leistung und Umwandlungsr..
Kategorien
- AI & Machine Learning
- AIRPODS
- Amazon
- Amazon Alexa & Amazon Echo
- Amazon Alexa & Amazon Echo
- Amazonas Feuerfernseher
- Amazon Prime Video
- Android
- Android-Telefone & Tablets
- Android Phones & Tablets
- Android TV
- Apfel
- Apple App Store
- Apple Homekit & Apple HomePod
- Apple Music
- Apple TV
- Apple Watch
- Apps & Web-Apps
- Apps & Web Apps
- Audio
- Chromebook & Chrome OS
- Chromebook & Chrome OS
- Chromecast
- Cloud & Internet
- Cloud & Internet
- Cloud Und Internet
- Computerhardware
- Computerverlauf
- Schnurschneiden & Streaming
- Cord Cutting & Streaming
- Discord
- Disney +
- DIY
- Electric Vehicles
- Ereader
- Grundlagen
- Explainers
- Spielen
- General
- Gmail
- Google Assistant & Google Nest
- Google Assistant & Google Nest
- Google Chrome
- Google Docs
- Google Drive
- Google Maps
- Google Play Store
- Google-Blätter
- Google-Folien
- Google TV
- Hardware
- HBO MAX
- Wie Man
- Hulu
- Internet Slang & Abkürzungen
- IPhone & IPad
- Kindle
- Linux
- Mac
- Wartung Und Optimierung
- Microsoft Edge
- Microsoft Excel
- Microsoft Office
- Microsoft Outlook
- Microsoft PowerPoint
- Microsoft-Teams
- Microsoft Word
- Mozilla Firefox
- Netflix
- Nintendo-Schalter
- Paramount +
- PC-Gaming
- Peacock
- Fotografie
- Photoshop
- Playstation
- Datenschutz & Sicherheit
- Privacy & Security
- Privatsphäre Und Sicherheit
- Produkt-Roundups
- Programming
- Raspberry Pi
- Roku
- Safari
- Samsung-Telefone & Tablets
- Samsung Phones & Tablets
- Slack
- Smart Home
- Snapchat
- Social Media
- Space
- Spotify
- Zunder
- Fehlerbehebung
- TV
- Videospiele
- Virtual Reality
- VPNs
- Webbrowser
- WIFI & Router
- WiFi & Routers
- Windows
- Windows 10
- Windows 11
- Windows 7
- Xbox
- YouTube & YouTube TV
- YouTube & YouTube TV
- Zoom
- Erklärer