Apple은 사용자로부터 수집하는 데이터를 비공개로 유지하는 데있어 명성을 유지하고 있습니다. 어떻게? "차등 프라이버시"라는 것을 사용합니다.
차별 프라이버시 란 무엇입니까?
사과 다음과 같이 설명합니다.
Apple은 차등 개인 정보 보호 기술을 사용하여 개인의 개인 정보를 손상시키지 않고 많은 사용자의 사용 패턴을 발견합니다. 개인의 신원을 모호하게하기 위해 Differential Privacy는 개인의 사용 패턴의 작은 샘플에 수학적 노이즈를 추가합니다. 더 많은 사람들이 동일한 패턴을 공유함에 따라 일반적인 패턴이 나타나기 시작하여 사용자 경험을 알리고 향상시킬 수 있습니다.
차등 개인 정보 보호의 철학은 다음과 같습니다. iPhone, iPad, Mac 등 기기가 더 큰 집계 데이터 풀 (다양한 작은 사진으로 구성된 큰 그림)에 계산을 추가하는 사용자는 다음과 같이 공개해서는 안됩니다. 그들이 어떤 데이터를 제공했는지는 말할 것도 없습니다.
이 작업을 수행하는 회사는 Apple 뿐만이 아닙니다. Google과 Microsoft 모두 더 일찍 사용했습니다. 그러나 애플은 그것에 대해 자세히 이야기함으로써 대중화했습니다. 2016 WWDC 기조 연설 .
그렇다면 다른 익명 데이터와 어떻게 다른가요? 음, 익명화 된 데이터는 사람에 대해 충분히 알고 있다면 여전히 개인 정보를 추론하는 데 사용될 수 있습니다.
해커가 회사의 급여를 공개하는 익명 데이터베이스에 액세스 할 수 있다고 가정 해 보겠습니다. 직원 X가 다른 지역으로 이전하고 있다는 것도 알고 있다고 가정 해 보겠습니다. 그런 다음 해커는 직원 X가 이동하기 전과 후에 데이터베이스를 쿼리하여 쉽게 수입을 추론 할 수 있습니다.
Employee X의 민감한 정보를 보호하기 위해 Differential Privacy는 수학적 "노이즈"및 기타 기술을 사용하여 데이터를 변경하여 데이터베이스를 쿼리하는 경우에만 근사 직원 X에게 지급 된 금액 (또는 다른 사람)
따라서 제공된 데이터와 여기에 추가 된 노이즈 간의 '차이'로 인해 그의 개인 정보가 보존되므로보고있는 데이터가 실제로 특정 개인의 데이터인지 여부를 거의 알 수 없을 정도로 모호합니다.
Apple의 차별적 개인 정보 보호는 어떻게 작동합니까?
차별적 개인 정보 보호는 비교적 새로운 개념입니다. 하지만 아이디어는 회사에 사용자의 데이터를 기반으로 한 통찰력을 제공 할 수 있다는 것입니다. 바로 그거죠 데이터의 출처 또는 출처.
예를 들어 Apple은 Mac 또는 iOS 기기에서 차등 개인 정보 보호 기능을 사용하기 위해 해싱, 서브 샘플링, 노이즈 주입이라는 세 가지 구성 요소를 사용합니다.
해싱은 텍스트 문자열을 가져 와서 고정 된 길이의 더 짧은 값으로 바꾸고 이러한 키를 고유 한 문자 또는 '해시'의 비가 역적으로 임의의 문자열로 혼합합니다. 이렇게하면 데이터가 가려져 기기가 데이터를 원래 형태로 저장하지 않습니다.
서브 샘플링은 사람이 입력하는 모든 단어를 수집하는 대신 Apple에서 더 작은 샘플 만 사용함을 의미합니다. 예를 들어 그림 이모티콘을 사용하여 친구와 긴 문자 대화를한다고 가정 해 보겠습니다. 전체 대화를 수집하는 대신 서브 샘플링은 이모티콘과 같이 Apple이 관심을 갖는 부분 만 사용할 수 있습니다.
마지막으로 기기에서 노이즈를 주입하여 더 모호하게 만들기 위해 원본 데이터 세트에 임의의 데이터를 추가합니다. 즉, Apple은 너무 약간 가려진 결과를 얻으므로 정확하지 않습니다.
이 모든 작업은 기기에서 발생하므로 Apple이 분석 할 수 있도록 클라우드로 전송되기 전에 이미 단축, 혼합, 샘플링 및 흐리게 처리되었습니다.
Apple의 차별적 개인 정보는 어디에 사용됩니까?
Apple이 힘 앱과 서비스를 개선하기 위해 데이터를 수집하려고합니다. 그러나 현재 Apple은 네 가지 특정 영역에서만 차등 개인 정보를 사용하고 있습니다.
- 충분한 사람들이 단어를 특정 이모티콘으로 바꾸면 모든 사람에게 제안이 될 것입니다.
- 일상적인 것으로 간주 될 수있는 충분한 지역 사전에 새 단어가 추가되면 Apple은 다른 모든 사전에도 해당 단어를 추가합니다.
- Spotlight에서 검색어를 사용하면 앱 추천을 제공하고 해당 앱에서 해당 링크를 열거 나 App Store에서 설치할 수 있습니다. 예를 들어 IMDB 앱을 추천하는 'Star Trek'를 검색한다고 가정 해 보겠습니다. 더 많은 사람들이 IMDB 앱을 열거 나 설치할수록 모든 사람의 검색 결과에 더 많이 표시됩니다.
- Notes의 조회 힌트에 대해보다 정확한 결과를 제공합니다. 예를 들어, "apple"이라는 단어가 포함 된 메모가 있다고 가정 해 보겠습니다. 조회 검색을 수행하면 사전 정의뿐만 아니라 Apple 웹 사이트, Apple Store 위치 등에 대한 결과도 제공됩니다. 아마도 더 많은 사람들이 특정 결과를 탭할수록 다른 모든 사용자를위한 조회에 더 자주 표시 될 것입니다.
그림 이모티콘을 예로 들어 보겠습니다. iOS 10에서 Apple 새로운 이모티콘 대체 기능 도입 iMessage에서. "사랑"이라는 단어를 입력하면 하트 이모티콘으로 바꿀 수 있습니다. "개"라는 단어를 입력하면 짐작했듯이 개 이모티콘으로 바꿀 수 있습니다.
마찬가지로 iPhone에서 원하는 그림 이모티콘을 예측할 수 있습니다. "I 'm going to walk the dog"라는 메시지를 입력하면 iPhone이 강아지 그림 이모티콘을 유용하게 제안합니다.
따라서 Apple은 수집 한 모든 iMessage 데이터를 가져 와서 전체적으로 검사하고 사람들이 입력하는 내용과 문맥에 따라 패턴을 추론 할 수 있습니다. 이는 다른 사람들이 작성하고 "원하는 그림 이모티콘 일 것입니다."라고 생각하는 모든 텍스트 대화를 통해 iPhone이 더 현명한 선택을 할 수 있음을 의미합니다.
(이모티콘의) 마을이 필요합니다
Differential Privacy의 단점은 작은 샘플에서 정확한 결과를 제공하지 않는다는 것입니다. 그 힘은 특정 데이터를 모호하게 만드는 데 있기 때문에 한 명의 사용자가 원인 일 수 없습니다. 제대로 작동하고 잘 작동하려면 많은 사용자가 참여해야합니다.
비트 맵 사진을 아주 가까이에서 보는 것과 같습니다. 조금만 보면 그것이 무엇인지 알 수 없지만 한 걸음 물러서서 전체를 보면 그림이 매우 높지 않더라도 그림이 더 선명하고 선명 해집니다. 해결.
따라서 이모티콘 교체 및 예측을 개선하기 위해 Apple은 전 세계에서 iPhone 및 Mac 데이터를 수집하여 사람들이하는 일을 더욱 명확하게 파악하여 앱과 서비스를 개선해야합니다. 이 모든 무작위적이고 시끄러운 크라우드 소싱 데이터를 사용하여 '엉덩이'대신 복숭아 그림 이모티콘을 사용하는 사용자 수와 같은 패턴을 찾습니다.
따라서 차등 개인 정보 보호의 힘은 Apple이 대량의 집계 데이터를 검사 할 수있는 동시에 누가 데이터를 보내는 지에 대해 현명하지 않은지 확인하는 데 달려 있습니다.
iOS 및 macOS에서 차등 개인 정보를 옵트 아웃하는 방법
그래도 차등 개인 정보 보호가 귀하에게 적합하다고 확신하지 못한다면 운이 좋을 것입니다. 기기 설정에서 바로 선택 해제 할 수 있습니다.
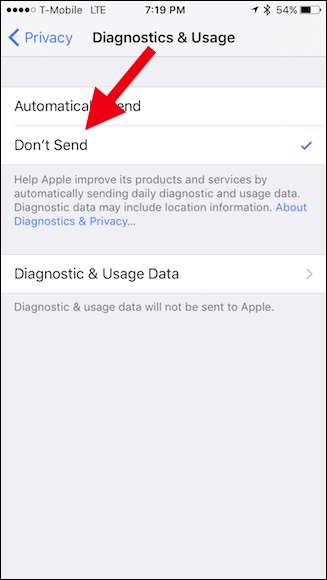
iOS 기기에서 "설정"을 누른 다음 "개인 정보"를 누릅니다.
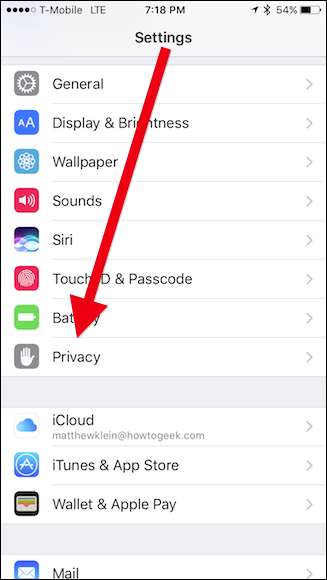
개인 정보 화면에서 "진단 및 사용"을 탭합니다.

마지막으로 진단 및 사용 화면에서 "보내지 않음"을 탭합니다.
macOS에서는 시스템 환경 설정을 열고 "보안 및 개인 정보 보호"를 클릭합니다.
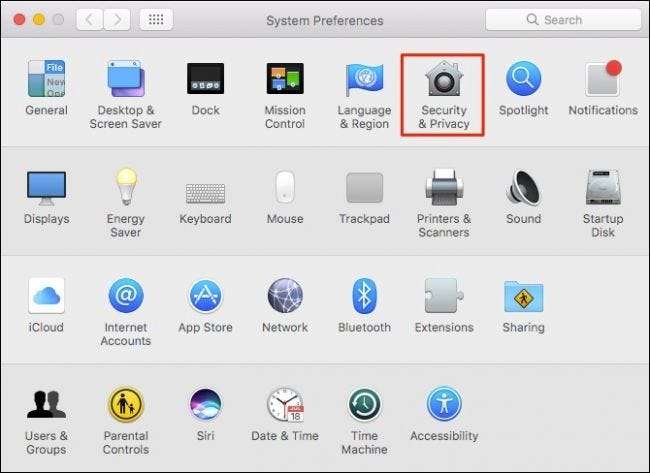
보안 및 개인 정보 환경 설정에서 "개인 정보"탭을 클릭 한 다음 "진단 및 사용 데이터를 Apple에 보내기"가 선택 해제되어 있는지 확인하십시오. 이렇게 변경하려면 왼쪽 하단에있는 잠금 아이콘을 클릭하고 시스템 비밀번호를 입력해야합니다.

명백하게, 차동 프라이버시에는 더 많은 것이 있습니다. 이 간단한 설명보다 이론과 응용 모두에서. 그것의 고기와 감자는 심각한 수학에 크게 의존하기 때문에 꽤 무겁고 복잡해질 수 있습니다.
하지만 이것이 작동 방식에 대한 아이디어를 제공하고 회사가 식별되는 것에 대한 두려움없이 특정 데이터를 수집하는 것에 대해 더 자신감을 갖게되기를 바랍니다.