Der er ingen tvivl om, at nutidens websider er fulde af rigt indhold og bruger mere båndbredde til fuldt indlæsning, men ville brugen af en tekstbaseret browser i stedet for en GUI-baseret gøre en væsentlig forskel i at reducere netværkstrafik? Dagens SuperUser Q & A-indlæg har svarene på en nysgerrig læsers spørgsmål.
Dagens spørgsmål og svar-session kommer til os med tilladelse fra SuperUser - en underinddeling af Stack Exchange, en community-driven gruppe af Q&A websteder.
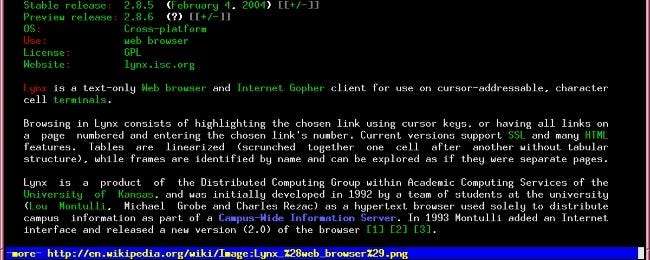
Lynx Browser-skærmbillede med tilladelse til Wikipedia .
Spørgsmålet
SuperUser-læser Paulb vil vide, om tekstbaserede browsere rent faktisk kan reducere netværkstrafik:
Gør tekstbaserede browsere som f.eks Los , Links og ELinks forbruge mindre båndbredde end GUI-baserede browsere som Firefox, Chrome og Internet Explorer?
Jeg gætter på, at der ikke er nogen reduktion i trafikken. Min begrundelse for dette er, at jeg tror, at en tekstbaseret browser downloader hele siden, som den tilbydes af serveren. Enhver strømlining eller reduktion af side-widgetry sker lokalt.
Måske er der en vis reduktion i trafikken, da de fleste tekstbaserede browsere ikke udfører sidescript eller flash-filer, hvilket kan medføre mere trafik.
Kan tekstbaserede browsere gøre en mærkbar forskel i at reducere netværkstrafik?
Svaret
SuperUser-bidragyder gronostaj har svaret til os:
Webserveren sender ikke hele hjemmesiden, men dokumenter, som browsere anmoder om. For eksempel når du åbner google.com, spørger browseren webserveren for dokumentet google.com. Webserveren behandler anmodningen og sender nogle HTML-kode tilbage.
Derefter kontrollerer browseren, hvad webserveren har sendt. I dette tilfælde er det en HTML-webside, så den analyserer dokumentet og ser efter refererede scripts, stilark, billeder, skrifttyper osv.
På dette tidspunkt er browseren færdig med at downloade det originale dokument, men har stadig ikke downloadet de refererede dokumenter. Det kan vælge at gøre det eller springe over at downloade dem. Almindelige browsere forsøger at downloade alle refererede dokumenter for at få den bedste oplevelse. Hvis du har en annonceblokering ( ligesom Adblock Plus ) eller et privatlivs-plugin ( som Ghostery eller NoScript ), så blokerer det muligvis også nogle ressourcer.
Derefter downloader browseren de henviste dokumenter en efter en, hver gang beder webserveren eksplicit om en enkelt ressource. I vores Google-eksempel finder browseren følgende referencer ( bare for at nævne nogle få af dem ):
- https://www.google.com/images/srpr/logo11w.png (Google Logo)
- https://www.google.com/textinputassistant/tia.png (Tastaturikon)
- https://ssl.gstatic.com/gb/images/i1_3d265689.png (Nogle kombinerede billeder, et trick der bruges til at reducere antallet af browseranmodninger.)
De faktiske filer kan være forskellige for forskellige brugere, da browsere og sessioner kan ændre sig over tid. Tekstbaserede browsere downloader ikke billeder, Flash-filer, HTML5-video osv., Så de downloader færre data.
@NathanOsman laver en godt punkt i kommentarerne . Nogle gange er små billeder indlejret direkte i HTML-dokumenter, og i disse tilfælde kan downloading af dem ikke undgås. Dette er et andet trick, der bruges til at reducere antallet af anmodninger. De er dog meget små, ellers er omkostningerne ved kodning af en binær fil i base64 for store. Der er få sådanne billeder på google.com ( base64 kodet størrelse / dekodet størrelse ):
- 19 × 11 pixel tastaturikon (106 Bytes / 76 Bytes)
- 28 × 38 pixel Mikrofonikon (334 Bytes / 248 Bytes)
- 1 × 1 pixel Transparent GIF (62 Bytes / 43 Bytes) Den vises i Google Chrome Dev Tools-ressourcer-fanen, men jeg kunne ikke finde den i kildekoden (sandsynligvis tilføjet senere med JavaScript).
- 1 × 1 pixel Korrupt GIF-fil, der vises to gange. (34 Bytes / 23 Bytes) Formålet er et mysterium for mig.
Har du noget at tilføje til forklaringen? Lyd fra i kommentarerne. Vil du læse flere svar fra andre teknisk kyndige Stack Exchange-brugere? Tjek den fulde diskussionstråd her .







