PowerShell 3에는 강력하고 새로운 웹 관련 기능을 포함하여 많은 새로운 기능이 있습니다. 그들은 웹 자동화를 극적으로 단순화하고 오늘 우리는 웹 페이지에서 모든 단일 링크를 추출하고 원하는 경우 선택적으로 리소스를 다운로드하는 방법을 보여줄 것입니다.
PowerShell로 웹 스크래핑
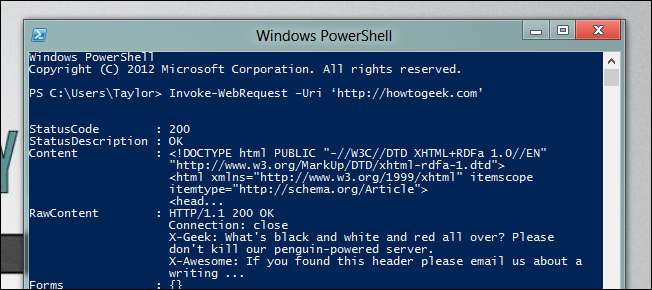
웹을 더 쉽게 자동화 할 수있는 두 가지 새로운 cmdlet, 사람이 읽을 수있는 콘텐츠를 더 쉽게 구문 분석 할 수있는 Invoke-WebRequest와 컴퓨터가 읽을 수있는 콘텐츠를 더 쉽게 읽을 수 있도록하는 Invoke-RestMethod가 있습니다. 링크는 페이지의 HTML의 일부이기 때문에 사람이 읽을 수있는 부분입니다. 웹 페이지를 얻으려면 Invoke-WebRequest를 사용하고 URL을 제공하기 만하면됩니다.
Invoke-WebRequest –Uri‘http://howtogeek.com’
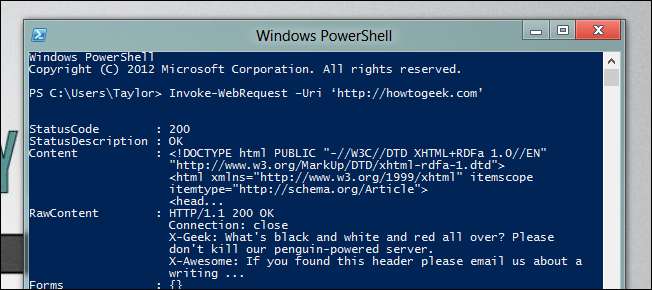
아래로 스크롤하면 응답에 links 속성이있는 것을 볼 수 있으며 PowerShell 3의 새로운 멤버 열거 기능을 사용하여이를 필터링 할 수 있습니다.
(Invoke-WebRequest –Uri‘http://howtogeek.com’).
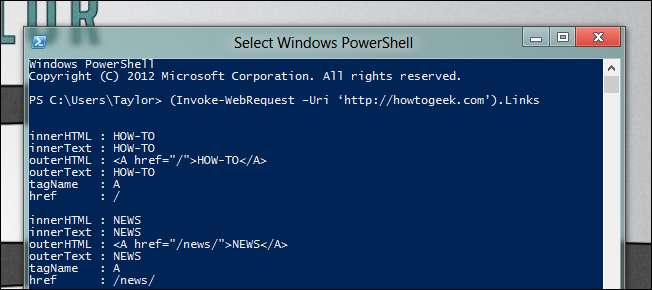
보시다시피 많은 링크가 다시 표시됩니다. 여기에서 찾고있는 링크를 필터링 할 수있는 독특한 것을 찾기 위해 상상력을 발휘해야합니다. 첫 페이지에있는 모든 기사의 목록을 원한다고 가정 해 보겠습니다.
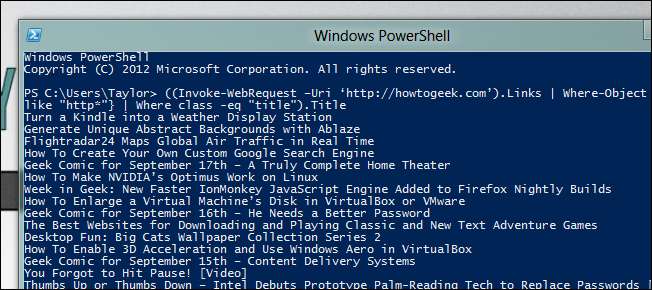
((Invoke-WebRequest –Uri‘ http://howtogeek.com '). 링크 | Where-Object {$_.href -like “http*”} | 여기서 class -eq“title”). Title
새로운 cmdlet으로 할 수있는 또 다른 훌륭한 기능은 일상적인 다운로드를 자동화하는 것입니다. Nat Geo 웹 사이트에서 오늘의 이미지를 자동으로 스크래핑하는 것을 살펴 보겠습니다.이를 위해 새 웹 cmdlet을 Start-BitsTransfer와 결합합니다.
$ IOTD = ((Invoke-WebRequest -Uri‘ http://photography.nationalgeographic.com/photography/photo-of-the-day/’).Links | innerHTML- "* Download Wallpaper *"와 같은) .href
시작 비트 전송-소스 $ IOTD-대상 C : \ IOTD \
그게 전부입니다. 나만의 멋진 트릭이 있습니까? 댓글로 알려주세요.







