PowerShell 3には、いくつかの強力な新しいWeb関連機能を含む、多くの新機能があります。これらはWebの自動化を劇的に簡素化します。今日は、Webページからすべてのリンクを抽出し、必要に応じてリソースをダウンロードする方法を紹介します。
PowerShellでWebをスクレイピングする
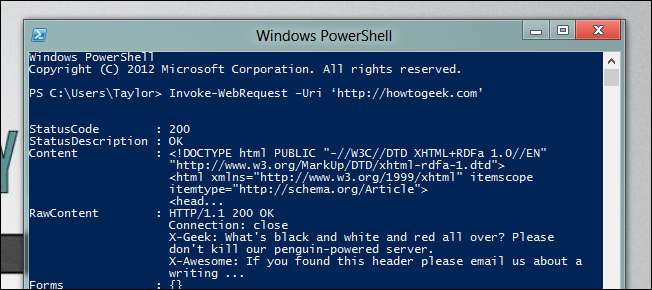
Webの自動化を容易にする2つの新しいコマンドレットがあります。人間が読めるコンテンツの解析を容易にするInvoke-WebRequestと、機械が読めるコンテンツを読みやすくするInvoke-RestMethodです。リンクはページのHTMLの一部であるため、人間が読める形式の一部です。 Webページを取得するために必要なのは、Invoke-WebRequestを使用してURLを指定することだけです。
Invoke-WebRequest –Uri「http://howtogeek.com」
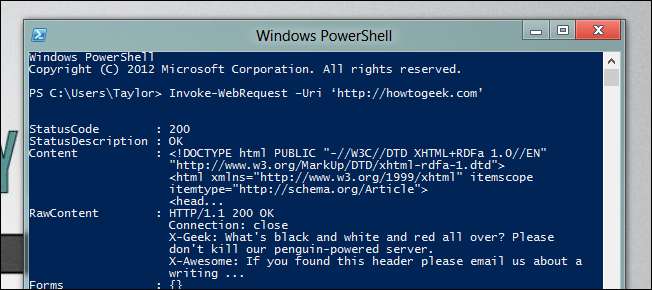
下にスクロールすると、応答にリンクプロパティがあることがわかります。これにより、PowerShell3の新しいメンバー列挙機能を使用してこれらを除外できます。
(Invoke-WebRequest –Uri‘http://howtogeek.com ’)。リンク
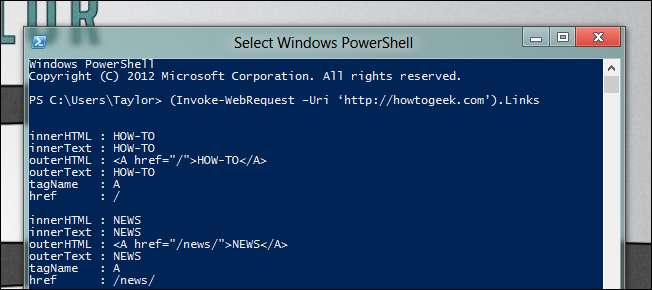
たくさんのリンクが戻ってくるのがわかると思いますが、ここで想像力を駆使して、探しているリンクを除外するためのユニークなものを見つける必要があります。フロントページにすべての記事のリストが必要だとします。
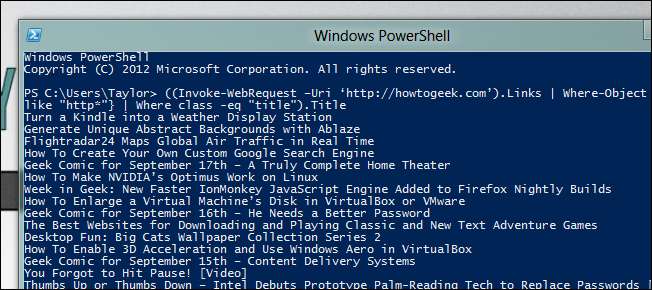
((Invoke-WebRequest –Uri ‘ http://howtogeek.com ’)。リンク | Where-Object {$_.href -like “http*”} |ここで、class -eq“ title”)。Title
新しいコマンドレットでできるもう1つの優れた点は、毎日のダウンロードを自動化することです。 Nat Geo Webサイトからその日の画像を自動的にスクレイピングする方法を見てみましょう。これを行うために、新しいWebコマンドレットをStart-BitsTransferと組み合わせます。
$ IOTD =((Invoke-WebRequest -Uri ‘ hっtp://pほとgらphy。なちおなlげおgらpひc。こm/pほとgらphy/pほとーおfーてぇーだy/’)。ぃんks | innerHTMLのような「*壁紙のダウンロード*」)。href
Start-BitsTransfer -Source $ IOTD -Destination C:\ IOTD \
これですべてです。あなた自身の巧妙なトリックはありますか?コメントで教えてください。







