Il tuo browser invia il suo agente utente a ogni sito web a cui ti connetti. Abbiamo scritto su cambiando lo user agent del browser prima - ma cos'è esattamente un programma utente, comunque?
Un agente utente è una "stringa", ovvero una riga di testo, che identifica il browser e il sistema operativo per il server web. Sembra semplice, ma i programmi utente sono diventati un pasticcio nel tempo.
Le basi
Quando il browser si collega a un sito Web, include un campo User-Agent nella sua intestazione HTTP. Il contenuto del campo dell'agente utente varia da browser a browser. Ogni browser ha il proprio agente utente distintivo. In sostanza, un agente utente è un modo per un browser di dire "Ciao, sono Mozilla Firefox su Windows" o "Ciao, sono Safari su iPhone" a un server web.
Il server Web può utilizzare queste informazioni per fornire pagine Web diverse a browser Web e sistemi operativi diversi. Ad esempio, un sito web potrebbe inviare pagine per dispositivi mobili a browser per dispositivi mobili, pagine moderne a browser moderni e un messaggio "aggiorna il browser" a Internet Explorer 6.
Esame degli agenti utente
Ad esempio, ecco l'agente utente di Firefox su Windows 7:
Mozilla / 5.0 (Windows NT 6.1; WOW64; rv: 12.0) Gecko / 20100101 Firefox / 12.0
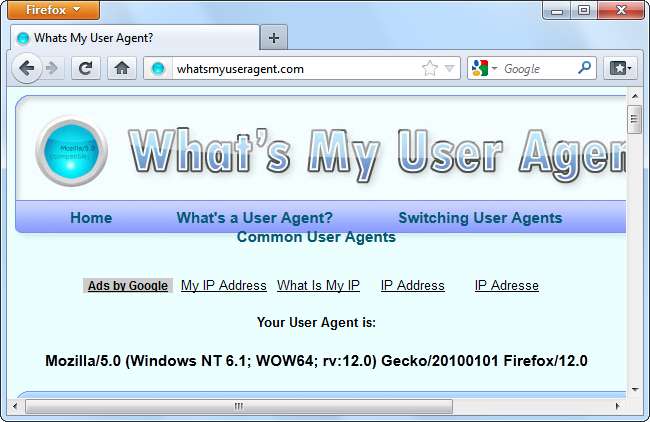
Questo agente utente dice abbastanza al server web: il sistema operativo è Windows 7 (nome in codice Windows NT 6.1), è una versione a 64 bit di Windows (WOW64) e il browser stesso è Firefox 12.
Ora diamo un'occhiata allo user agent di Internet Explorer 9, che è:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)
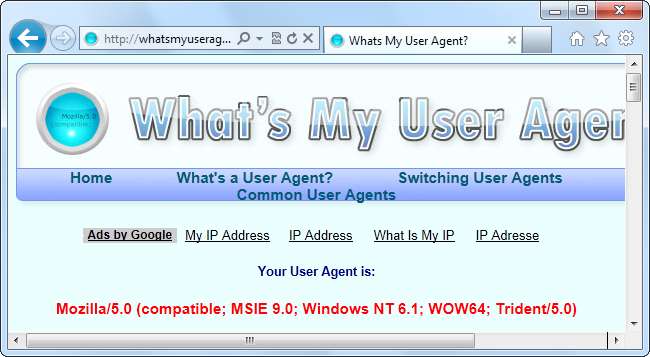
La stringa dell'agente utente identifica il browser come IE 9 con il motore di rendering Trident 5. Tuttavia, potresti notare qualcosa di confuso: IE si identifica come Mozilla.
Torneremo su questo in un minuto. Innanzitutto, esaminiamo anche l'agente utente di Google Chrome:
Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 536.5 (KHTML, come Gecko) Chrome / 19.0.1084.52 Safari / 536.5
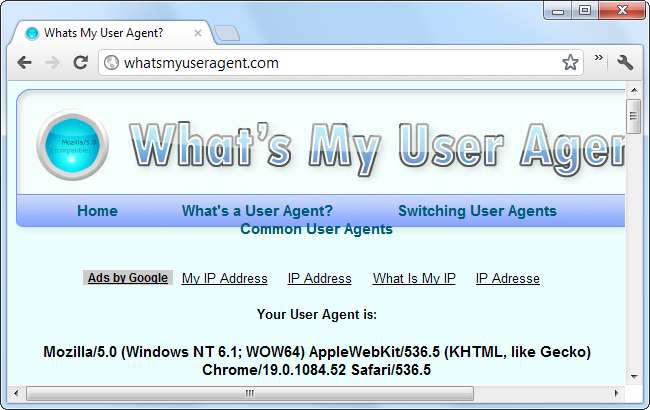
La trama si infittisce: Chrome finge di essere sia Mozilla che Safari. Per capire il motivo, dovremo esaminare la cronologia dei programmi utente e dei browser.
Il pasticcio della stringa dell'agente utente
Mosaic è stato uno dei primi browser. La sua stringa agente utente era NCSA_Mosaic / 2.0. Successivamente, Mozilla è arrivato (in seguito ribattezzato Netscape) e il suo programma utente era Mozilla / 1.0. Mozilla era un browser più avanzato di Mosaic, in particolare supportava i frame. I server web hanno verificato che il programma utente contenesse la parola Mozilla e ha inviato pagine contenenti frame ai browser Mozilla. Ad altri browser, i server web hanno inviato le vecchie pagine senza frame.
Alla fine, è arrivato Internet Explorer di Microsoft che supportava anche i frame. Tuttavia, IE non riceveva pagine web con frame, perché i server web le inviavano semplicemente ai browser Mozilla. Per risolvere questo problema, Microsoft ha aggiunto la parola Mozilla al proprio agente utente e ha inserito ulteriori informazioni (la parola "compatibile" e un riferimento a IE.) I server Web sono stati felici di vedere la parola Mozilla e hanno inviato a IE le pagine Web moderne. Altri browser che sono venuti dopo hanno fatto la stessa cosa.
Alla fine, alcuni server hanno cercato la parola Gecko, il motore di rendering di Firefox, e hanno offerto ai browser Gecko pagine diverse rispetto ai browser meno recenti. KHTML - originariamente sviluppato per Konquerer sul desktop KDE di Linux - ha aggiunto le parole "like Gecko" in modo che anche le pagine moderne fossero progettate per Gecko. WebKit era basato su KHTML: quando è stato sviluppato, hanno aggiunto la parola WebKit e mantenuto la linea originale "KHTML, like Gecko" per motivi di compatibilità. In questo modo, gli sviluppatori di browser continuavano ad aggiungere parole ai loro programmi utente nel tempo.
I server web non si preoccupano davvero di quale sia la stringa esatta dell'agente utente: controllano solo se contiene una parola specifica.
Utilizza
I server Web utilizzano agenti utente per una varietà di scopi, tra cui:
- Fornire diverse pagine Web a diversi browser Web. Questo può essere utilizzato per il bene - ad esempio, per servire pagine web più semplici a browser meno recenti - o per il male - per esempio, per visualizzare un messaggio "Questa pagina web deve essere visualizzata in Internet Explorer".
- Visualizzazione di contenuti diversi su sistemi operativi diversi, ad esempio visualizzando una pagina ridotta sui dispositivi mobili.
- Raccolta di statistiche che mostrano i browser e i sistemi operativi utilizzati dai propri utenti. Se vedi mai le statistiche sulla quota di mercato del browser, è così che vengono acquisite.
Anche i bot che eseguono la scansione del Web utilizzano agenti utente. Ad esempio, il crawler web di Google si identifica come:
Googlebot/2.1 (+http://www.google.com/bot.html)
I server Web possono offrire ai bot un trattamento speciale, ad esempio consentendogli di accedere tramite schermate di registrazione obbligatorie. (Sì, questo significa che a volte puoi ignorare le schermate di registrazione impostando il tuo agente utente su Googlebot.)
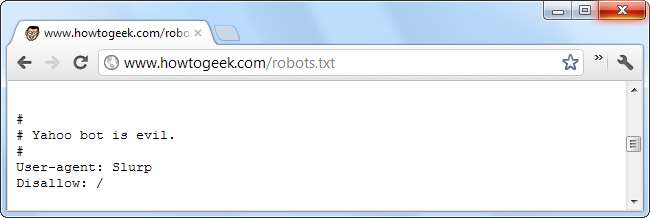
I server web possono anche dare ordini a bot specifici (o tutti i bot) utilizzando il file robots.txt. Ad esempio, un server web potrebbe dire a un bot specifico di andare via o dire a un altro bot di indicizzare solo determinate aree del sito web. Nel file robots.txt, i bot sono identificati dalle stringhe del loro agente utente.
Tutti i principali browser contengono modi per impostare agenti utente personalizzati , in modo da poter vedere a quali server Web inviano i diversi browser. Ad esempio, imposta il browser desktop sulla stringa dell'agente utente di un browser per dispositivi mobili e vedrai le versioni per dispositivi mobili delle pagine web sul desktop.







