Twoja przeglądarka wysyła swojego agenta użytkownika do każdej witryny, z którą się łączysz. Pisaliśmy o zmiana klienta użytkownika przeglądarki wcześniej - ale czym właściwie jest klient użytkownika?
Agent użytkownika to „ciąg znaków” - to znaczy wiersz tekstu - identyfikujący przeglądarkę i system operacyjny na serwerze WWW. Brzmi to prosto, ale programy użytkownika stały się z czasem bałaganem.
Podstawy
Kiedy Twoja przeglądarka łączy się ze stroną internetową, zawiera pole User-Agent w nagłówku HTTP. Zawartość pola agenta użytkownika różni się w zależności od przeglądarki. Każda przeglądarka ma własnego, charakterystycznego agenta użytkownika. Zasadniczo klient użytkownika to sposób, w jaki przeglądarka może powiedzieć „Cześć, jestem Mozilla Firefox w systemie Windows” lub „Cześć, jestem Safari na iPhonie” do serwera WWW.
Serwer sieciowy może wykorzystywać te informacje do udostępniania różnych stron internetowych różnym przeglądarkom internetowym i różnym systemom operacyjnym. Na przykład witryna internetowa może wysyłać strony mobilne do przeglądarek mobilnych, nowoczesne strony do nowoczesnych przeglądarek oraz komunikat „proszę uaktualnić przeglądarkę” do przeglądarki Internet Explorer 6.
Badanie agentów użytkownika
Na przykład, oto klient użytkownika przeglądarki Firefox w systemie Windows 7:
Mozilla / 5.0 (Windows NT 6.1; WOW64; rv: 12.0) Gecko / 20100101 Firefox / 12.0
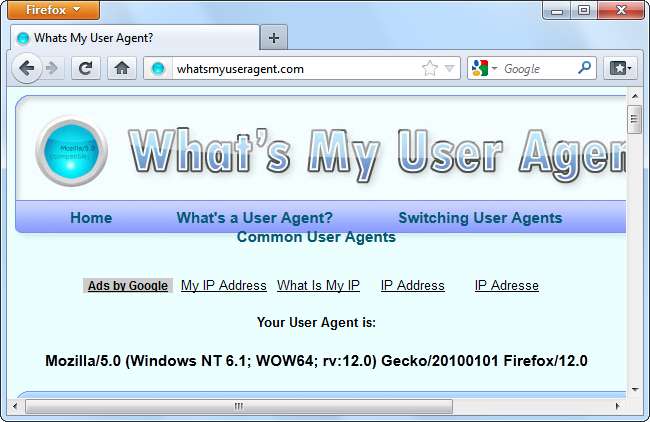
Ten klient użytkownika przekazuje wiele informacji serwerowi WWW: system operacyjny to Windows 7 (nazwa kodowa Windows NT 6.1), jest to 64-bitowa wersja systemu Windows (WOW64), a sama przeglądarka to Firefox 12.
Przyjrzyjmy się teraz klientowi użytkownika Internet Explorera 9, który jest:
Mozilla / 5.0 (kompatybilny; MSIE 9.0; Windows NT 6.1; WOW64; Trident / 5.0)
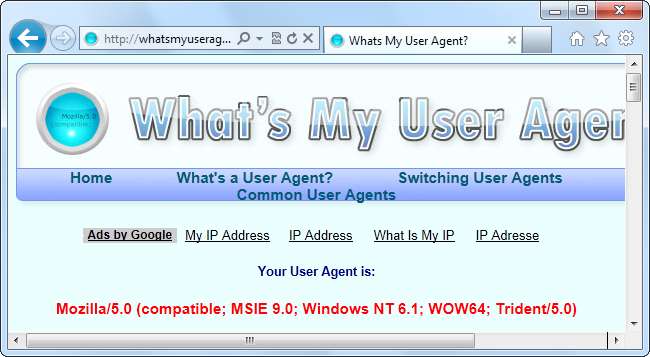
Ciąg agenta użytkownika identyfikuje przeglądarkę jako IE 9 z silnikiem renderującym Trident 5. Możesz jednak zauważyć coś zagmatwanego - IE identyfikuje się jako Mozilla.
Wrócimy do tego za minutę. Najpierw przyjrzyjmy się też klientowi użytkownika Google Chrome:
Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 536.5 (KHTML, jak Gecko) Chrome / 19.0.1084.52 Safari / 536.5
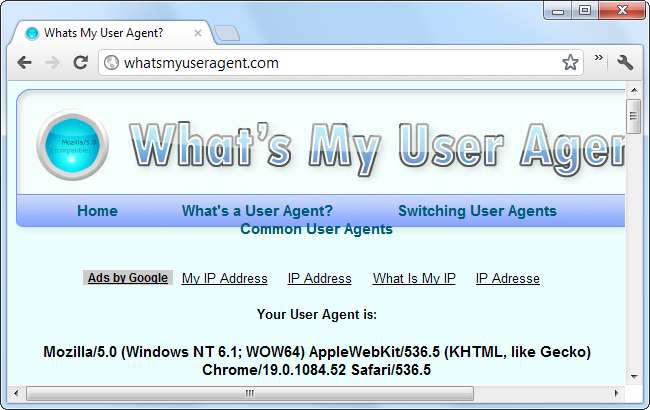
Fabuła się zagęszcza: Chrome udaje jednocześnie Mozillę i Safari. Aby zrozumieć dlaczego, będziemy musieli zbadać historię klientów użytkownika i przeglądarek.
Komunikat ciągu agenta użytkownika
Mosaic była jedną z pierwszych przeglądarek. Jego ciąg agenta użytkownika to NCSA_Mosaic / 2.0. Później pojawiła się Mozilla (później przemianowana na Netscape), a jej agentem użytkownika była Mozilla / 1.0. Mozilla była bardziej zaawansowaną przeglądarką niż Mosaic - w szczególności obsługiwała ramki. Serwery WWW sprawdziły, czy agent użytkownika zawiera słowo Mozilla i wysłał strony zawierające ramki do przeglądarek Mozilla. Do innych przeglądarek serwery WWW wysyłały stare strony bez ramek.
Ostatecznie pojawił się Internet Explorer firmy Microsoft, który obsługiwał również ramki. Jednak IE nie otrzymywał stron internetowych z ramkami, ponieważ serwery WWW wysłały je właśnie do przeglądarek Mozilla. Aby rozwiązać ten problem, Microsoft dodał słowo Mozilla do swojego agenta użytkownika i wrzucił dodatkowe informacje (słowo „kompatybilny” i odniesienie do IE). Serwery WWW ucieszyły się, widząc słowo Mozilla i wysłały IE do nowoczesnych stron internetowych. Inne przeglądarki, które pojawiły się później, zrobiły to samo.
W końcu niektóre serwery szukały słowa Gecko - silnik renderujący Firefoksa - i wyświetlały przeglądarki Gecko inne strony niż starsze przeglądarki. KHTML - pierwotnie opracowany dla Konquerera na pulpicie KDE w Linuksie - dodał słowa „jak Gecko”, dzięki czemu otrzymali także nowoczesne strony zaprojektowane dla Gecko. WebKit był oparty na KHTML - kiedy został opracowany, dodali słowo WebKit i zachowali oryginalną linię „KHTML, jak Gecko” dla celów kompatybilności. W ten sposób programiści przeglądarek z czasem dodawali słowa do swoich programów użytkownika.
Serwery internetowe tak naprawdę nie dbają o dokładny ciąg agenta użytkownika - po prostu sprawdzają, czy zawiera on określone słowo.
Używa
Serwery internetowe używają agentów użytkownika do różnych celów, w tym:
- Udostępnianie różnych stron internetowych różnym przeglądarkom internetowym. Można to wykorzystać w dobrym celu - na przykład do udostępniania prostszych stron internetowych starszym przeglądarkom - lub zła - na przykład do wyświetlania komunikatu „Ta strona internetowa musi być przeglądana w przeglądarce Internet Explorer”.
- Wyświetlanie różnych treści w różnych systemach operacyjnych - na przykład poprzez wyświetlanie odchudzonej strony na urządzeniach mobilnych.
- Gromadzenie statystyk pokazujących przeglądarki i systemy operacyjne używane przez ich użytkowników. Jeśli kiedykolwiek zobaczysz statystyki dotyczące udziału w rynku przeglądarek, oto sposób ich pozyskiwania.
Boty przeszukujące sieci również używają agentów użytkownika. Na przykład robot sieciowy Google identyfikuje się jako:
Googlebot / 2.1 (+ http: //www.google.com/bot.html)
Serwery internetowe mogą traktować boty w specjalny sposób - na przykład zezwalając im na obowiązkowe ekrany rejestracji. (Tak, oznacza to, że czasami możesz ominąć ekrany rejestracji, ustawiając swojego klienta użytkownika na Googlebota).
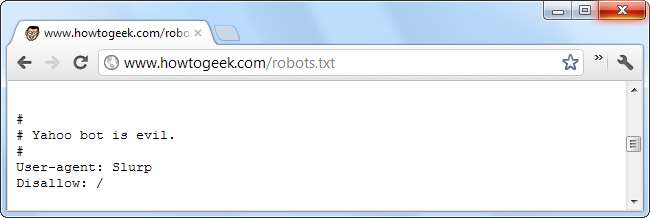
Serwery internetowe mogą również wydawać polecenia określonym botom (lub wszystkim robotom) za pomocą pliku robots.txt. Na przykład serwer WWW może nakazać określonemu botowi odejść lub powiedzieć innemu botowi, aby indeksował tylko określone obszary witryny. W pliku robots.txt boty są identyfikowane na podstawie ciągów ich klientów użytkownika.
Wszystkie główne przeglądarki zawierają sposoby ustaw niestandardowych agentów użytkownika , dzięki czemu możesz zobaczyć, jakie serwery internetowe wysyłają do różnych przeglądarek. Na przykład ustaw przeglądarkę na komputerze na ciąg klienta użytkownika przeglądarki mobilnej, a na komputerze zobaczysz mobilne wersje stron internetowych.







 w systemie Windows Vista")